Neurosymbolic Diffusion Models
van Krieken, Emile, Pasquale Minervini, Edoardo Ponti, and Antonio Vergari. “Neurosymbolic Diffusion Models.” arXiv preprint arXiv:2505.13138 (2025).

What story does this paper tell?
[Motivation] Neurosymbolic (NeSy) predictors can learn wrong concepts while achieving high accuracy, making them less reliable in real-world scenarios.
[Insight] Ambiguity arises when data and program together admit multiple indistinguishable concept assignments.
[Insight] NeSy predictors should express uncertainty over the concepts that are consistent with the data, which can guide user intervention, inform trust, or trigger data acquisition when the ambiguity arises.
[Motivation] Standard NeSy predictors are built on top of neural networks that assume conditional independence between the extracted concepts (Conditional Independence Assumption), limiting their ability to model
- interactions (i.e. dependencies) between concepts, and
- uncertainty over concepts.
This leads to overconfident predictions and poor out-of-distribution (OOD) generalization.
[Goal] Design expressive, scalable and reliable NeSy predictors that can model dependency between and uncertainty over concepts.
[Assumption] In theory, discrete diffusion models are particularly suited for NeSy predictors, as each step of their denoising process involves predicting a discrete distribution that fully factorizes (Local Independence Assumption).
[Motivation] In practice, designing a diffusion process for NeSy predictors is highly non-trivial, as it requires dealing with a symbolic program and marginalizing over all possible concepts – a task that is generally intractable.
[Contribution] Devise a novel continuous-time loss function for diffusion that incorporates symbolic programs.
[Contribution] An efficient gradient estimator for scalable training.
[Contribution] Neurosymbolic Diffusion Models (NeSyDMs), the first class of diffusion models that operate over the concepts of a NeSy predictor in conjunction with symbolic programs.
[Core Idea] Exploit classical NeSy predictors, while modeling concepts as dependent entities globally by formalizing a masked diffusion process.
[Conclusion] The continuous-time losses of masked diffusion models extend to non-factorized distributions.
[Conclusion] NeSyDMs are
- calibrated and performant on visual reasoning problems, and
- scaling beyond the SOTA on the complex visual path-planning task.
Background
Neurosymbolic (NeSy) Predictors
Neurosymbolic models that extract high-level symbolic concepts in the form of latent variables from raw inputs for reasoning and predicting labels in an interpretable manner.
NeSy predictors based on fuzzy logics:
- assume a form of independence between concepts
NeSy predictors based on probabilistic logics
- go beyond the independence assumption and can model dependencies
- previous methods:
- SPL, BEARS: mix multiple independent distributions, strong Reasoning Shortcut (RS)-awareness (See Reasoning Shortcuts)
- Neurosymbolic Probabilistic Logic Programming (DeepProbLog, Scallop): add helper variables to increase expressivity
- Limitations:
- built on exact or top-k inference
difficult to scale to high-dimensional reasoning problems - expressivity is limited by the number of mixture components
- built on exact or top-k inference
- Methods that approximate inference:
- assume independence between concepts
- lack RS-awareness
Goal of NeSy predictors: learn a parameterized predictive model
that maps high-dimensional inputs to low-dimensional discrete labels , where each label can take a value from . Implementation of the predictive model:
Concept extractor: a neural network
that maps the input to a vector of symbolic concepts, i.e., discrete variables encoding high-level information that can take values from the discrete label space. Prediction program: a function
that maps concepts to the low-dimensional discrete labels as output predictions. The predictive model is formally defined by computing a conditional weighted model count (WMC) that marginalizes over all concepts which are consistent with the output labels, and then summing their probability masses:
where
is an indicator function.
NeSy Generative Models
- Generating from expressive models (e.g., LLMs, Diffusion Models) while involving programs and constraints.
- Generating from LLMs:
- NeSy loss functions that encode constraints
- Constrained decoding (e.g., sequential Monte-Carlo methods, probabilistic circuits)
- limitation: rely on heuristics to steer LLMs towards constraints
Reasoning Shortcuts (RSs)
- Recent work proved that NeSy predictors are susceptible to reasoning shortcuts.
- Definition: A predictive model predicts the correct output labels given the inputs, but maps the inputs to concepts incorrectly.
- This can dramatically harm model performance on unseen data.
- Mitigating RSs is challenging and potentially costly.
- Models can be made aware of their RSs by properly expressing uncertainty over all concepts that are consistent with the input-output mappping.
- Then we can deploy NeSy predictors in an active learning setting, where uncertain concepts are queried for extra labeling.
(Conditional) Independence Assumption
- The concepts are independent of inputs, i.e.
- NeSy predictors use this assumption to perform efficient probabilistic reasoning.
- Recent work proved that such models cannot simultaneously represent the relevant uncertainty over different concepts while maximizing Equation (1).
- The only maximizers of Equation (1) for the independent model are to deterministically return either
or . - However, there exists no maximizer that can simultianeously assign probability mass to both cases.
- This means that independent models cannot be RS-aware.
- This raises the need to design NeSy predictors that can express dependencies between concepts.
Classes of Expressive Models for Instantiation of NeSy Predictors
Mixture models and probabilistic circuits:
- requires compiling the program into a binary circuit via knowledge compilation
- requires ensuring the compatibility of the probabilistic circuit with binary circuit
- challenging to scale to programs to high-dimensional space
Autoregressive models:
- Marginalization over concepts does not commute with AR-conditioning
computationally expensive
- Marginalization over concepts does not commute with AR-conditioning
Diffusion models:
- same limitation as AR-models, but
- assume the conditional independence assumption locally at every denoising step
- sufficient to encode global dependencies
Masked Diffusion Models (MDMs):
- Forward diffusion: Starting from time step
, gradually mask dimensions of a data point with some probability at each time step , such that the data point becomes fully masked as time step .
where
and is a strictly decreasing noising schedule with and . Once a dimension is masked, another dimension remains unmasked.
Backward denoising (parametrized and trainable): Start with a fully masked data point, gradually unmask dimensions by assigning values in the label space. Then, remask some dimensions using the reverse posterior
: The standard loss function partially masks
to obtain , and then uses the conditionally independent unmasking model to attempt to reconstruct . This loss function requires that
implements the carry-over unmasking assumption, i.e. it should assign a probability of 1 to values of previously unmasked dimensions.
- Forward diffusion: Starting from time step
Research Questions
- RQ1: Can NeSyDMs scale to high-dimensional reasoning problems?
- RQ2: Does the expressiveness of NeSyDMs improve reasoning shortcut awareness compared to independent models?
Model Architecture
Conditionally Independent Unmasking Model
- Input: an image
+ partially masked concepts , - Output: predicted unmasked concepts
Prediction Program
- Input: unmasked concepts
predicted by - Output: predicted output label
Forward Diffusion Process
- defined as in Equation 2
- forward process for concepts:
- forward process for output labels:
Backward Denoising (Reverse) Processes
Concept Reverse Process
- defined as in Equation 3 with a conditional concept masking model
:
Output Reverse Process
- parameterized by reusing the concept unmasking model:
- takes the concept unmasking model and marginalizes over all concepts
that are consistent with the partially masked output - To implement the carry-over unmasking assumption, use
, a variation of the prediction program that always returns if dimension is unmasked in .
Negative Evidence Lower-Bound (NELBO)
- Motivation: No direct access to ground-truth concepts
. - Use a variational setup and derive a lower-bound for the intractable data log-likelihood
.
Specifically, use a variational distributionthat shares parameters with the MDM to approximate the posterior .
To implement this, the concept unmasking modelis repurposed with the controlled text generation (CTG) method from Guo et al., 2024.
Loss Function
- Intuition: Define the NeSyDM’s reverse process over
discrete steps. Consider the data log-likelihood as goes to infinity, giving a NELBO for a continuous-time process, which serves as the base for the loss function to train NeSyDM. - Theorem 3.1.
Letbe a concept unmasking model, a given program, a variational distribution, and a noising schedule. Then, we have that the data log-likelihood as is bounded as , where 
- The concept unmasking loss
is like the unmasking loss used in MDMs.
Since we do not have access to the ground-truth concept, we sample it from the variational distribution and ask the model to reconstruct from a partially masked version . - The output unmasking loss
is a sum of weighted model counts (WMC), one for each dimension of the output .
weights concepts using the conditionally independent concept unmasking model that is conditioned on partially masked concepts .
The conditional independence of the concept unmasking model allows the use of standard techniques in NeSy literature to computeefficiently. - The variational entropy
is maximized to encourage the variational distribution to cover all concepts that are consistent with the input and output .
- The concept unmasking loss
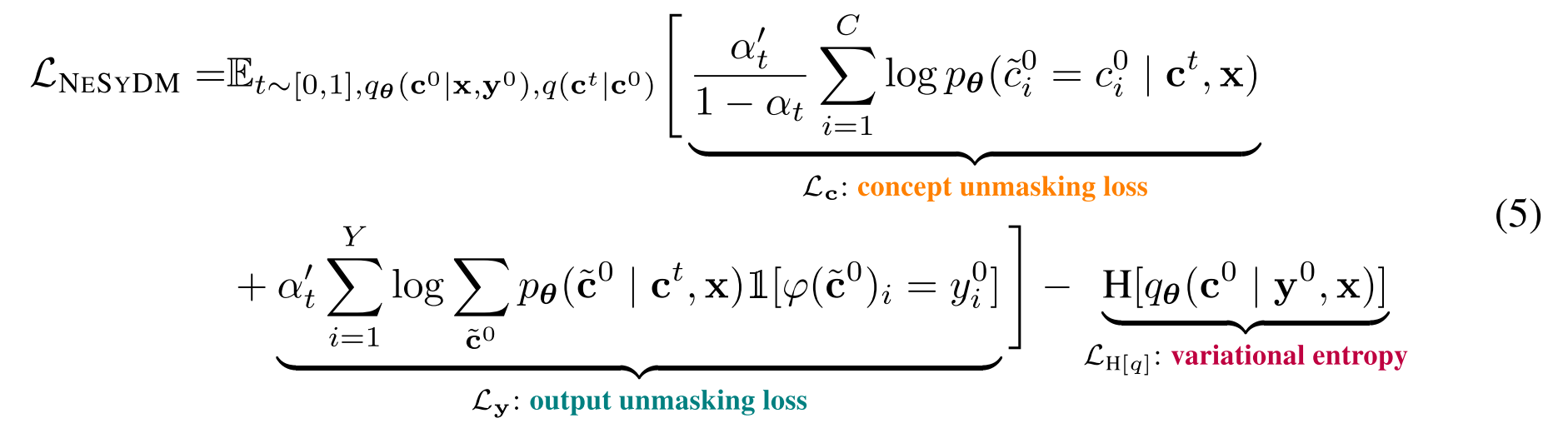
Variational Posterior
Motivation: compute NELBO
Goal: a variational distribution
to sample likely concepts that are consistent with the ground-truth output label Solution: Adapt the sampling algorithm using a concept unmasking model that depends on the output label and the program:
where
-is the concept unmasking model,
-is the ground-truth output label,
-is the prediction program,
-is a normalizing constant. Difference from the standard unmasking process (cf. Equation 3): Equation 6 only consider valid
. Challenge: Sampling from
is NP-hard. If we have a tractable representation of
, e.g., a polysize circuit as the output of a knowledge compilation step, then we can represent compactly and exactly sample from it. Without access to such a circuit, we can instead use a relaxation of the constraint similar to the CTG method proposed by Guo et al., 2024:
- Let
, where and approaches the hard constraint. - At each step in the backward denoising process, we resample to approximately obtain samples from
.
- Let
This procedure may sample concepts
that are inconsistent with the ground-truth label , but it prefers samples that reconstruct more dimensions of . In practice, with a reasonably large
, this effectively samples times from and chooses the sample that violates the fewest constraints.
Loss Optimization and Scalability
Question: How to optimize the NeSyDM NELBO
using gradient descent? Solution: a gradient estimation algorithm that scales to large reasoning problems by approximating intractable computation
The empirical concept unmasking loss
is tractable. The output unmasking loss
and the variational entropy are intractable and must be backpropagate through. Output unmasking loss
: develop a sampling-based approach that approximates the WMC gradients - Use the REINFORCE Leave-One-Out (RLOO) estimator.
Given:
- a time step,
- samplesand
- samples $\tilde{c}_1^{0}, … ,\tilde{c}s^{0} \sim p{\theta}(c^0 \mid c^t, x)$,
apply:
where .
- Use the REINFORCE Leave-One-Out (RLOO) estimator.
Variational entropy
- Challenge: The variational distribution samples from a conditioned version of the unmasking model, where the computation of likelihoods and the maximization of entropy of
is highly intractable. - Attempted solution: two biased approximations of
- Conditional 1-step entropy
- Unconditional 1-step entropy
- Challenge: The variational distribution samples from a conditioned version of the unmasking model, where the computation of likelihoods and the maximization of entropy of
 where
where Sampling and Inference
- Challenge: Excatly computing the mode
is intractable. - Solution: Approximate it using a majority voting strategy.
Sample
concepts from the trained MDM. Compute the output labels with
. Take the most frequent output:
If the concept dimension
is too large, use first-hitting sampler. Otherwise, use T-step time-discretized sampler.
Sampling from the variational distribution
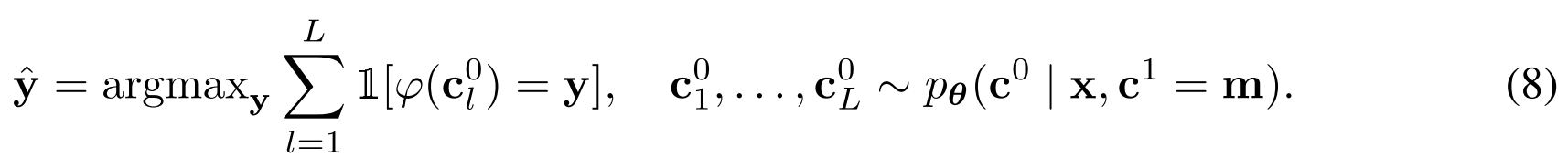




Experiment
Tasks and Datasets
For RQ1:
- Multidigit MNIST Addition (visual reasoning task)
- ?? (visual path planning task)
For RQ2:
- MNIST Half, MNIST Even-Odd (MNIST E-O) (visual reasoning task)
- BDD-OIA (BDD) (self-driving, visual path planning task)
- RSBench (RS-awareness)
Conclusions
- NeSyDMs are one of the best NeSy predictors that can scale to high-dimensional reasoning problems while remaining RS-awareness.
- NeSyDMs are suitable for real-world safety-critical applications.
Future Work
Incorporate additional exact inference routines by combining the following two aspects or automatically (and approximately) reduce a different setting into one of them:
- obtaining an efficient circuit
- decomposing the output label into separate dimensions
Extend NeSyDM to tackle constrained generation from GANs, VAEs, deep HMMs, other discrete diffusion models, continuous diffusion models, and hybrid diffusion models (symbolic, discrete concepts + continuous latent variables).
- Title: Neurosymbolic Diffusion Models
- Author: Der Steppenwolf
- Created at : 2025-05-23 09:28:56
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/05/23/Neurosymbolic-Diffusion-Models/
- License: This work is licensed under CC BY-NC-SA 4.0.