FreeCtrl: Constructing Control Centers with Feedforward Layers for Learning-Free Controllable Text Generation
Zijian Feng, Hanzhang Zhou, Kezhi Mao, and Zixiao Zhu. 2024. FreeCtrl: Constructing Control Centers with Feedforward Layers for Learning-Free Controllable Text Generation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7627–7640, Bangkok, Thailand. Association for Computational Linguistics.
What problem does this paper address?
Single- and multi-attribute controllable text generation (CTG)
What is the motivation of this paper?
- Learning-based CTG methods require extensive attribute-specific training data and computational resources.
- Learning-free CTG methods often yield inferior performance.
- FFN vectors suffer from a major limitation, high-maintenance, which makes it difficult to adjust their weights for precise control.
- Low weights lack the power to steer LLMs.
- High weights compromise output diversity and fluency.
What are the main contributions?
- A systematic analysis of using Feed-Forward Neural Network (FFN) vectors for CTG.
- FreeCtrl, a learning-free approach that dynamically adjusts the weights of selected FFN vectors.
- Comprehensive experiments demonstrate the effectiveness of FreeCtrl compared to previous learning-based and leanring-free approaches.
Which insights inspired the proposed method?
- The weights of different FFN vectors influence the likelihood of different tokens generated by LLMs.
- The outputs generated by LLMs can be explained by examining the weights associated with the value vectors.
- FFN vectors can enable stable, diverse controls for LLM outputs, directing sentence generation toward desired attributes.
This is based on the following three key characteristics of FFN vectors:- Convergence: Increasing the weight of an FFN vector can result in a stable and convergent output distribution in LLMs, thereby elevating the probabilities of specific tokens.
- Diversity: Diverse FFN vectors can increase the output probabilities of most tokens in the LLM’s vocabulary, which covers keywords relevant to general attributes in CTG.
- Prompt-Invariance: The observed effects of convergence and diversity remain consistent across different input prompts.
- FFN can be conceptualized as a neural key-value memory system, where keys and values are represented by columns and rows in different weight matrices.
- Initially higher weights are necessary to guide the generation towards the desired direction.
How does the proposed method work?
Main idea: Manipulate FFN vectors to regulate the output of LLMs.
Key principle: Increasing a single FFN vector’s weight alters the output distribution, raising the probability of specific tokens. This enables targeted enhancement of certain FFN vector weights to raise the output probability of attribute keywords, hence directing LLM generation towards preferred attributes.
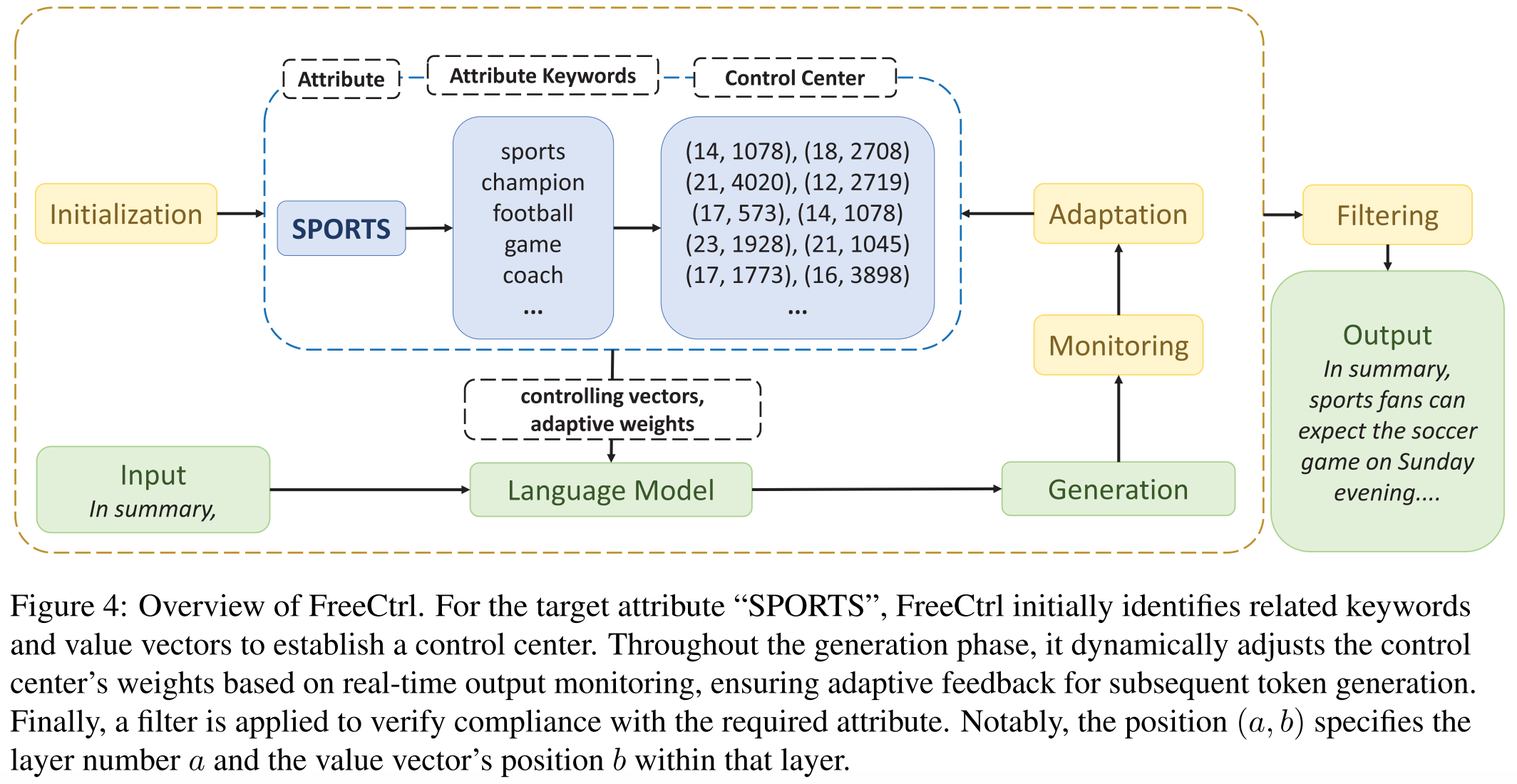
1. Initialization
1.1. Attribute Keyword Collection
Goal: Collect a set of keywords for each attribute.
Input: an attribute
from an attribute set Output: a set
of keywords associated with extracted from external KBs Issue: External KBs may contain noise.
- Solution:
- Apply a refinement function

- Filter out keywords
with .
- Insight: A suitable attribute keyword should have a relevance score for its corresponding attribute that is higher than the average relevance score for other attributes.
- Solution:
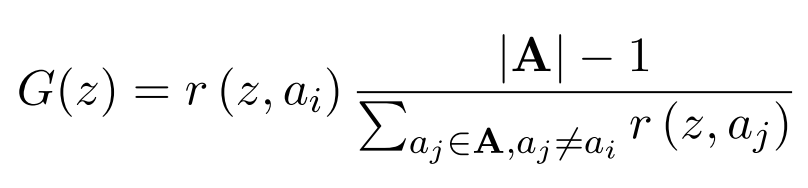
1.2. Control Center Construction
- Goal: Identify the value vectors and construct the control center for each attribute.
- Input: a keyword
for attribute - Output: a control center
for - Value Vectors
:
- f: activation function
, : weight metrices : input at layer - FFN
a neural key-value memory-system: - keys
columns in - values
rows in
- keys
- Given an input vector
, the keys generate coefficients , which assign weights to the values in . - In other words, within each layer, the value vectors
are extracted from the rows of the secondary weight matrix .
- Control effect:
: softmaxed output distribution across the LLM’s vocabulary , modulated by all value vectors, with = 50. : index of keyword in the vocabulary : total number of value vectors
- Choose value vectors with top-
probabilities for keyword :
retrieves the index of value vectors in
- Establish a control center for attribute
: - by aggregating the value vectors of the keywords related to
, with
- by aggregating the value vectors of the keywords related to
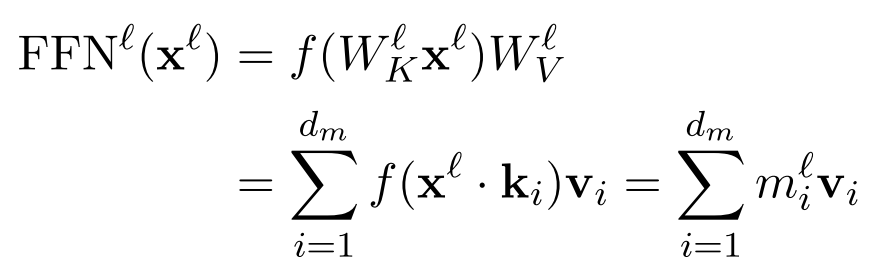
3. Monitoring
Goal: Evaluate each token in the generated response for its relevance to a target attribute.
Inputs:
: current output at timestamp for attribute , with length : set of keywords for attribute : set of all attributes
Output: sentence score
How to Compute correlation score and sentence score?
- Get embedding
for each token in the current output, where , and
embeddingfor the keywords of target attribute . - Compute the correlation score between current output and target attribute:
- Compute the maximum cosine similarity between each token in the current output and all target attribute keywords.
- Take their mean value as the correlation score. - Compute the sentence score for current output and target attribute:
- Get embedding
4. Adaptation
- Goal: Dynamically adjust the weights for the subsequent timestamp during generation.
- Premise: The model generates one token at each timestamp.
- Inputs:
: sentence score of the current output for target attribute : sentence score of the last token in the current output
- Output: weights
for the subsequent timestamp
where
-is a predefined hyperparameter,
-is a scaling hyperparameter, and
- $\hat{\mu}{t}^{a_i} = \max(\mu{t}^{a_i}, \mu_{s_{l_t}}^{a_i})$. - Intuition: Increase the weight for the target attribute if the final score is below a threshold, otherwise set the weight to 0 to prevent generating outputs associated with contrary attributes.
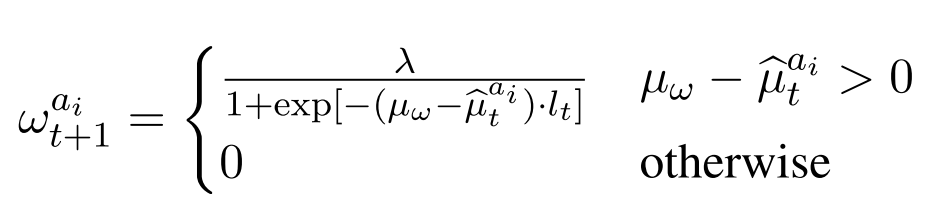 where
where5. Filtering
- Goal: Filter out noncompliant outputs using a threshold.
- Noncompliant outputs: Some generated outputs might not meet the
threshold, despite maintaining high weights. - Only the sentences fulfilling
are considered valid outputs, where is the final timestamp in the generation process.
How is the proposed method adapted for multi-attribute control?
- Intuition: Activate different control centers at different timestamps during generation.
- Multiple attributes:
- Gather the respective control center for each attribute.
- Calculate sentence scores and weights for all attributes.
- At each timestamp, select the control center with the highest weight.
How does FreeCtrl differ from other CTG methods (novelty)?
- Learning-free: No training/fine-tuning/prefix-tuning, adaptation in inference time.
- Control mechanism: Identify the LLM’s FFN vectors relevant to the target attributes and dynamically adjust their weights to control the output likelihood of attribute keywords.
Previous work:
PriorControl:
- Inference-phase method.
- Need to prefix-tune the encoder for latent space estimation.
- Need to train the model to learn invertible transformation.
MIRACLE:
- Inference-phase method.
- Need to collect a single-aspect dialogue dataset.
- Need to train a Condional Variational Auto-Encoder (CVAE) to learn the joint attribute latent space.
- Need an energy-based model (EBM).
MacLaSa:
- Inference-phase method.
- Need to train an attribute classifier.
- Need to train a Variational Auto-Encoder (VAE) to learn the joint attribute latent space.
- Need to solve ordinary differential equation (ODE).
- Need an energy-based model (EBM).
MAGIC:
- Inference-phase method.
- Need to construct counterfactual examples.
- Need to prefix-tune auto-encoder.
Experimental Settings:
Which attributes are controlled?
- topic
- sentiment
- detoxification
Which control scenarios?
- single-attribute
- multi-attribute
Which model is employed?
- GPT-2 medium
Which datasets are used for evaluation?
- AGNews (topic)
- IMDB (sentiment)
- Jigsaw Toxic (detoxification)
Which baselines are used for comparison?
- Learning-based baselines:
- PPLM: classifier gradients as bias indicators
- GeDi: decoding-phase control using compact conditional generative models
- Contrastive Prefix: contrastive prefix learning
- Discrete: discrete sampling
- PriorControl: probability density estimation in latent space using invertible transformations
- Learning-free baseline:
- Mix&Match: external scoring experts
What are the results and conclusions of the experiments?
- Automatic evaluation, single-attribute:
- Automatic evaluation, multi-attribute:
- Human evaluation:
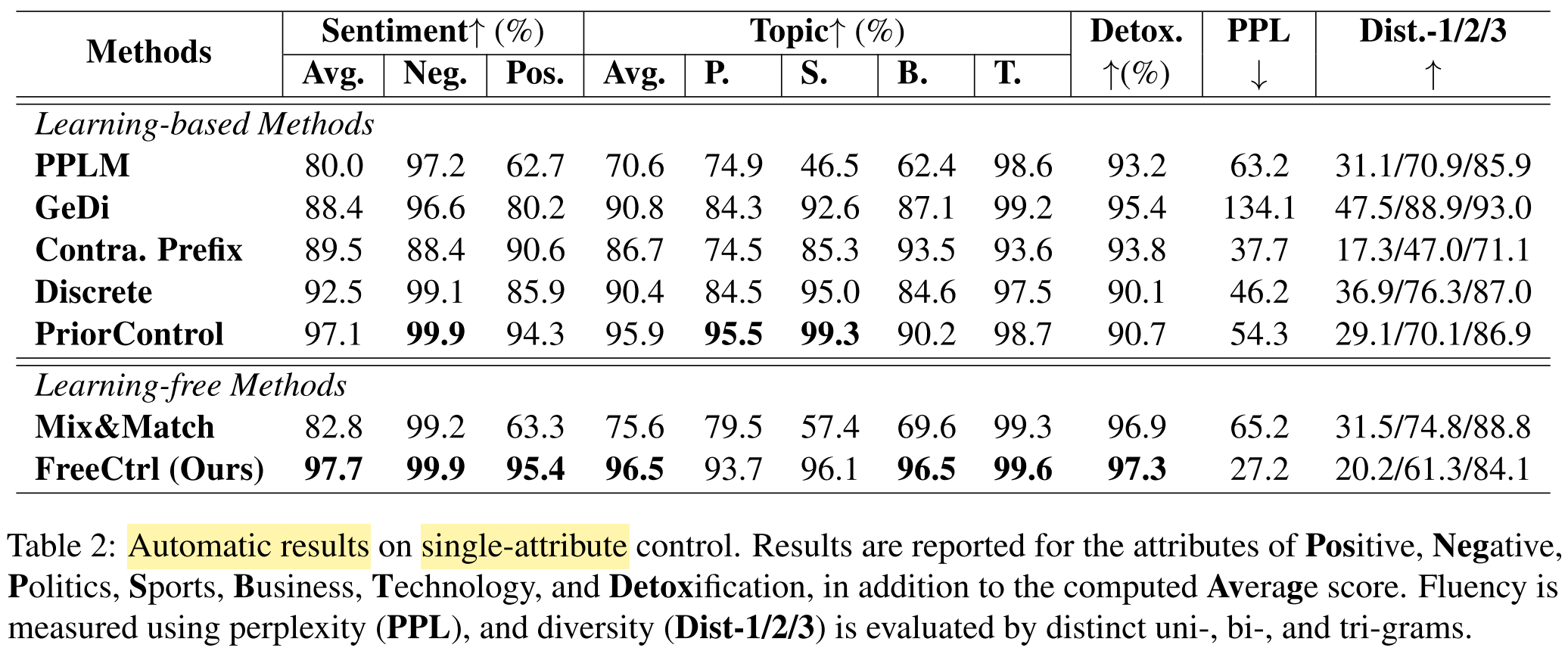
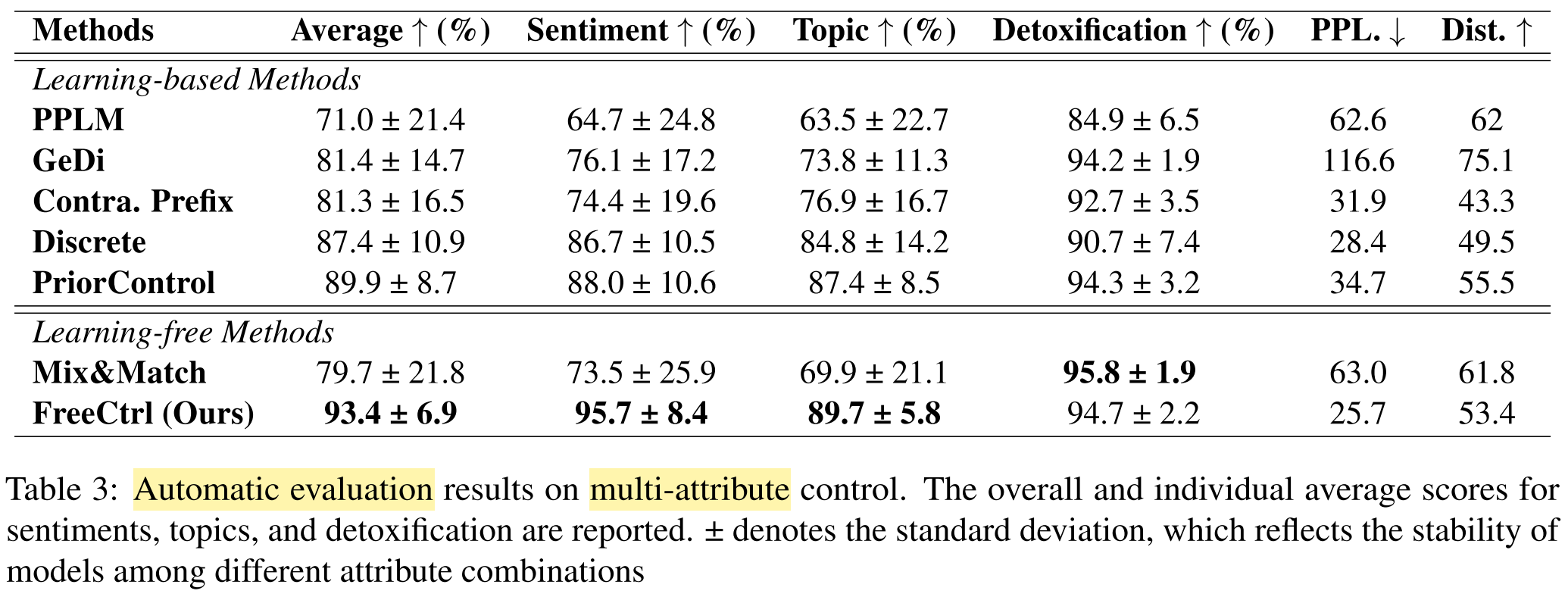
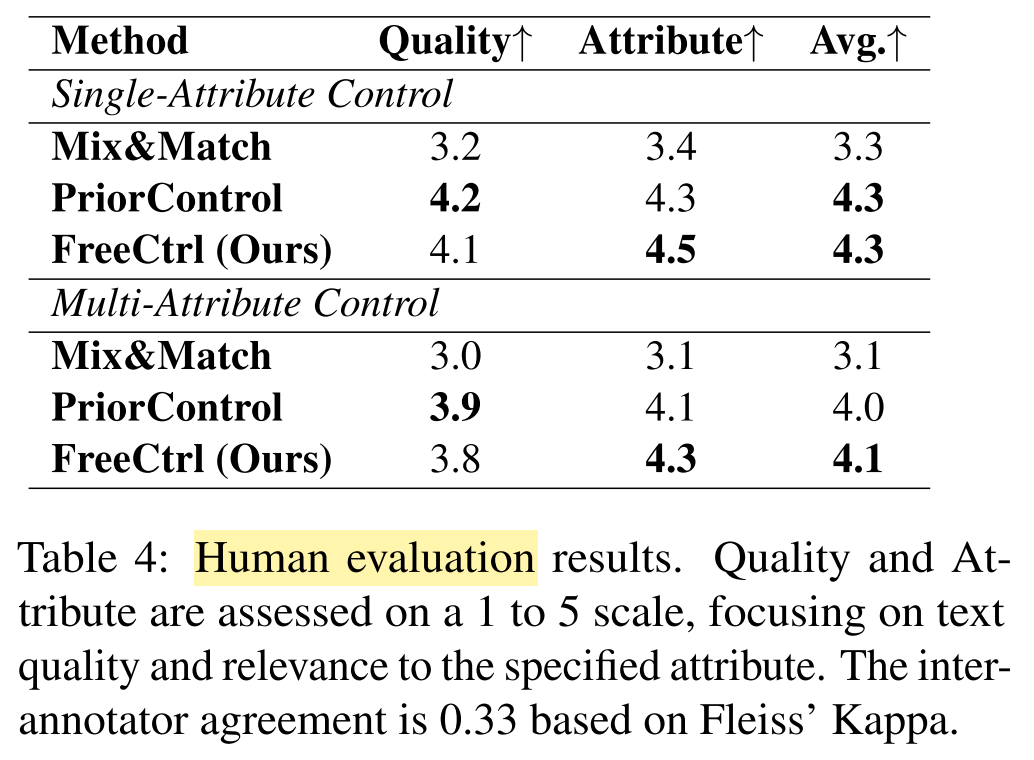
What are the strengths and weaknesses of this paper?
Strengths:
- learning-free, no training/fine-tuning/prefix-tuning, no collection of attribute-specific datasets
- inference-time dynamic adaptation
- high inference speed
- multi-attribute control capability
Weaknesses:
- Dynamics of value vectors are unclear, e.g., interactions between value vectors.
- Attributes are represented by semantically concrete words, such as “sports”.
- Need to collect attribute keywords.
- Only works on textual inputs.
- FreeCtrl was experimented on controlling only 3 attributes.
- Title: FreeCtrl: Constructing Control Centers with Feedforward Layers for Learning-Free Controllable Text Generation
- Author: Der Steppenwolf
- Created at : 2025-03-06 09:01:34
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/03/06/FreeCtrl/
- License: This work is licensed under CC BY-NC-SA 4.0.