DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, Daya, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu et al. “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.” arXiv preprint arXiv:2501.12948 (2025).
What problem does this paper address?
Let LLMs emerge reasoning capabilities through pure reinforcement learning, without any supervised data.
What are the motivations?
Enhancing reasoning capabilities of LLMs
- The reasoning abilities of recent LLMs still lag behind human-level performance, especially in math, coding, and scientific reasoning.
- Existing models improve reasoning through longer Chain-of-Thought (CoT), but still struggle with effective test-time scaling.
Exploring reinforcement learning (RL) for LLM reasoning
- Post-training techniques have proven effective for alignment with human preferences, but RL has not been widely used for reasoning tasks.
- Prior works have explored process-based reward models, RL, and search algorithms such as Monte Carlo Tree Search (MCTS) and Beam Search, but none of them has achieved general reasoning performance comparable to OpenAI o1 series models.
Addressing challenges in RL-based LLM training
- Traditional RL for LMs requires a critic model, which increases the training cost and complexity.
- Neural reward models may suffer from reward hacking in large-scale RL process.
- Retraining the reward model requires additional training resources and complicates the training pipeline.
Improving the readability and language consistency in RL-based models
- Pure RL training (DeepSeek-R1-Zero) exhibits
- poor readability (outputs lack clear structure, hard to interpret)
- language mixing (multiple languages in a single response)
- slow convergence (long training time)
Enabling smaller models to gain reasoning ability
- High performance LLMs require significant computational resource, making them hard to deploy for many real-world applications.
What are the research questions of this paper?
- RQ1: Can RL alone enhance the reasoning capabilities of LLMs (without SFT)?
- RQ2: Is it possible to distill the reasoning capabilities of larger models into smaller ones?
- RQ3: Can reasoning performance be further improved or convergence acelerated by incorporating a small amount of high-quality data as cold-start?
- RQ4: How to train a user-friendly model that not only produces clear and coherent CoT but also demonstrates strong general capabilities?
- RQ5: Can model achieve comparable performance through the large-scale RL training without distillation?
What are the main contributions of this paper?
Post-training
- Directly apply large-scale RL to the base model, without SFT.
- Allow the model to explore CoT by itself.
- Model exhibits emerging self-verification, reflection, and long CoT generation capabilities.
- Two RL stages to discover improved reasoning patterns and align with human preference
- Two SFT stages as the seed for model’s reasoning and non-reasoning capabilities.
Distillation:
- Enable smaller dense models with the reasoning ability of larger models by fine-tuning them using the reasoning data generated by DeepSeek-R1.
Proposed approaches:
1. DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
- Take DeepSeek-V3-Base as the base model.
- Train the base model using Group Relative Policy Optimization (GRPO) with rule-based reward modeling and a specific template.
GRPO
For each question
, sample a group of outputs { , , … , } from the old policy . Compute their rewards {
, , … , }. Compute the Advantage
. Optimize the policy model
by maximizing the objective
$$
\mathcal{J}{GRPO}(\theta) = \mathbb{E}[q \tilde P(Q), {o_i}^{G}{i=1} \tilde \pi_{\theta_{old}}(O | q)]
= \frac{1}{G}\sum_{i=1}^{G} (min(\frac{\pi_{\theta}(o_i | q)}{\pi_{\theta_{old}}(o_i | q)}A_{i}, clip(\frac{\pi_{\theta}(o_i | q)}{\pi_{\theta_{old}(o_i | q)}}, 1-\epsilon, 1+\epsilon)A_{i}) - \beta\mathbb{D}_{KL})
$$,with KL-divergence (regularization, prevents the policy from deviating too much from the base model)
$$
\mathbb{D}{KL}(\pi{\theta} || \pi_{ref}) = \frac{\pi_{ref}(o_i | q)}{\pi_{o_i | q}} - log(\frac{\pi_{ref}(o_i | q)}{\pi_{\theta}(o_i | q)} - 1)
$$,
where(stabilizes the policy update) and are hyper-parameters.
Reward Modeling
How to design the reward function?
- a rule-based reward system
- Accuracy rewards: evaluate whether the response is correct
- For math problems: require the model to provide the final answer in a specified format
- For LeetCode problems: use a compiler to generate feedback based on predefined test cases
- Format rewards: evaluate whether the response format is correct
- enforce the model to put its thinking process between ‘<think>‘ and ‘</think>‘ tags
- Accuracy rewards: evaluate whether the response is correct
Why not using neural reward models?
- Neural reward models may suffer from reward hacking.
- Retraining the reward model needs additional training resources, complicating the whole training pipeline.
Training Template
- Design a straightforward template that guides the base model to adhere to the specified instructions:
- First produce a reasoning process.
- Then generate the final answer.
Why limiting the constraints to this specific format?
- To avoid potential content-specific biases, such as mandating reflective reasoning or promoting particular problem-solving strategies.
- This enables accurate observation of the model’s natural progression during the RL process.
“Aha Moment”

- The model’s complex reasoning capabilities is not explicitly programmed, but emerges through the model’s interaction with the RL environment (i.e. self-evolved).
- The model learns to allocate more thinking time to a problem by reevaluating its initial approach.
- RL can lead to unexpected and sophisticated outcomes.
Insight: Rather than explicitly teaching the model on how to solve a problem, simply providing it with the right incentives will let it autonomously develop advanced problem-solving strategies.
Limitations of DeepSeek-R1-Zero
- poor readability
- language mixing
2. DeepSeek-R1: Reinforcement Learning with Cold Start
- RQ3: Can reasoning performance be further improved or convergence acelerated by incorporating a small amount of high-quality data as cold start?
- RQ4: How to train a user-friendly model that not only produces clear and coherent CoT but also demonstrates strong general capabilities?
A pipeline to train DeepSeek-R1:
Cold Start
- Construct and collect a small amount of CoT data.
- few-shot prompting
- zero-shot prompting
- gathering DeepSeek-R1-Zero outputs in a readable format and manually refining them
- Fine-tune the DeepSeek-V3-Base model on the cold-start data as the initial RL actor.
What are the advantages of the cold start data?
- The cold start data is designed to keep a readable pattern, while the non-readable data are filtered out.
- The designed pattern leads to better performance than DeepSeek-R1-Zero.
Reasoning-oriented RL (first RL stage)
- Apply the same RL training process as in DeepSeek-R1-Zero.
- Enhance the model’s capability on reasoning-intensive tasks, e.g., coding, math, science, logic reasoning etc.
- Sum up reasoning accuracy with language consistency reward to form the final reward.
Rejection Sampling and Supervised Fine-Tuning
- When reasoning-oriented RL converges, utilize the resulting model checkpoint to collect SFT data for the subsequent round.
- Different from the cold start data, the collected SFT data incorporates multi-modain data to enhance the model’s capabilities in writing, role-playing, and other general purpose tasks.
- Reasoning data:
- Apply rejection sampling to curate reasoning prompts and generate reasoning trajectories.
- Expand the dataset by incorporating additional data, some of which use a generative reward model.
- Filter out CoT with mixed languages, long paragraphs, and code blocks.
- For each prompt, sample multiple responses and retain only the correct ones.
- Output: 600k reasoning related training samples
- Non-reasoning data:
- Adopt DeepSeek-V3 pipeline and reuse portions of the SFT dataset of DeepSeek-V3 to generate data of creative writing, factual QA, self-cognition, and translation.
- For certain tasks, prompt DeepSeek-V3 to generate a potential CoT before answering the question.
- Output: 200k training samples that are unrelated to reasoning
- Reasoning data:
- Fine-tune the DeepSeek-V3-Base with the reasoning and non-reasoning data for 2 epochs.
RL for all Scenarios (second RL stage)
- Goal:
- further align model with human preference,
- improve the model’s helpfulness and harmlessness, while refining reasoning capabilities
- Difficulty of general tasks compared to reasoning tasks like coding, math etc.: no standard answer, hard to assess them with rules
- Solution: capture human preference with reward model
- Train the model using a combination of reward signals and diverse prompt distributions:
- For reasoning data: GRPO with rule-based reward model (same as DeepSeek-R1-Zero)
- For general data: Adopt a similar distribution of preference pairs and training prompts.
- For helpfulness: Do not evaluate the reasoning process, but only assess the utility and relevance of the final summary.
- For harmlessness: Evaluate the entire response of the model (reasoning + summary) to avoid any potential risks, biases, and harmful content.
Distillation: Empower Small Models with Reasoning Capability
- Goal: Equip more efficient small models with DeepSeel-R1 level reasoning capabilities.
- Use DeepSeek-R1 as teacher model and generate 800k samples.
- Directly fine-tune (SFT) smaller models using the 800k samples curated with DeepSeek-R1, without RL.
- Small models (student models):
- Qwen2.5-Math-1.5B
- Qwen2.5-Math-7B
- Qwen2.5- 14B
- Qwen2.5-32B
- Llama-3.1-8B
- Llama-3.3-70B-Instruct
Experiments:
Benchmarks
Standard benchmarks:
- MMLU
- MMLU-Redux
- MMLU-Pro
- C-Eval
- CMMLU
- IFEval
- FRAMES
- GPQA Diamond
- SimpleQA
- C-SimpleQA
- SWE-Bench Verified
- Aider
- LiveCodeBench
- Codeforces
- Chinese National High School Mathematics Olympiad (CNMO 2024)
- American Invitational Mathematics Examination 2024 (AIME 2024)
Open-ended generation tasks:
- AlpacaEval 2.0
- Arena-Hard
For distilled models:
- AIME 2024
- MATH-500
- GPQA Diamond
- Codeforces
- LiveCodeBench
Experiment Settings
- input prompt length for all benchmarks: 32,768 tokens
- maximum generation length: 32,768 tokens
- greedy decoding
- pass@1 evaluation: sampling temperature 0.6, top-p value 0.95, generate
responses for each question , : correctness of the i-th response - cons@64: majority vote from 64 samples
Baselines
- DeepSeek-V3
- Claude-Sonnet-3.5-1022
- GPT-4o-0513
- OpenAI-o1-mini
- OpenAI-o1-1217
- QwQ-32B-Preview
What are the results and conclusions?
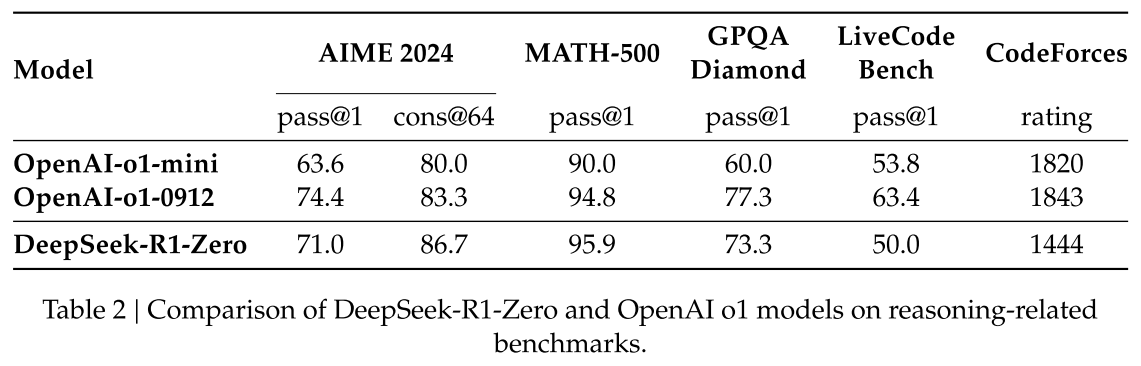
DeepSeek-R1-Zero:
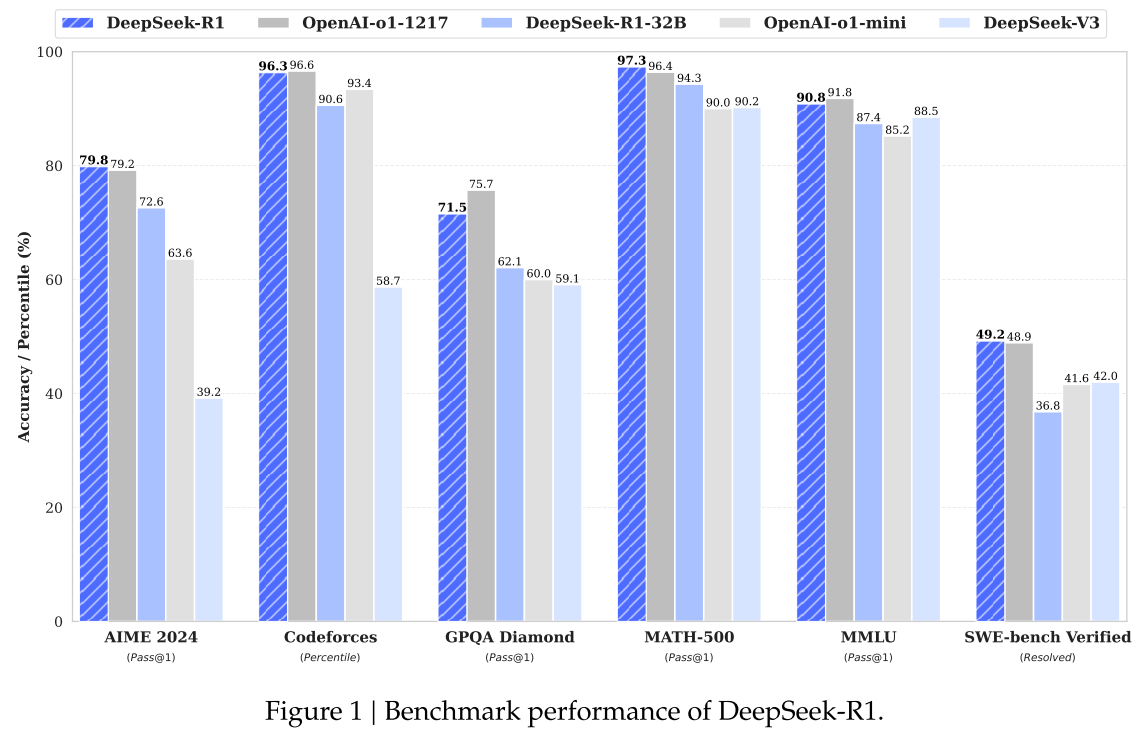
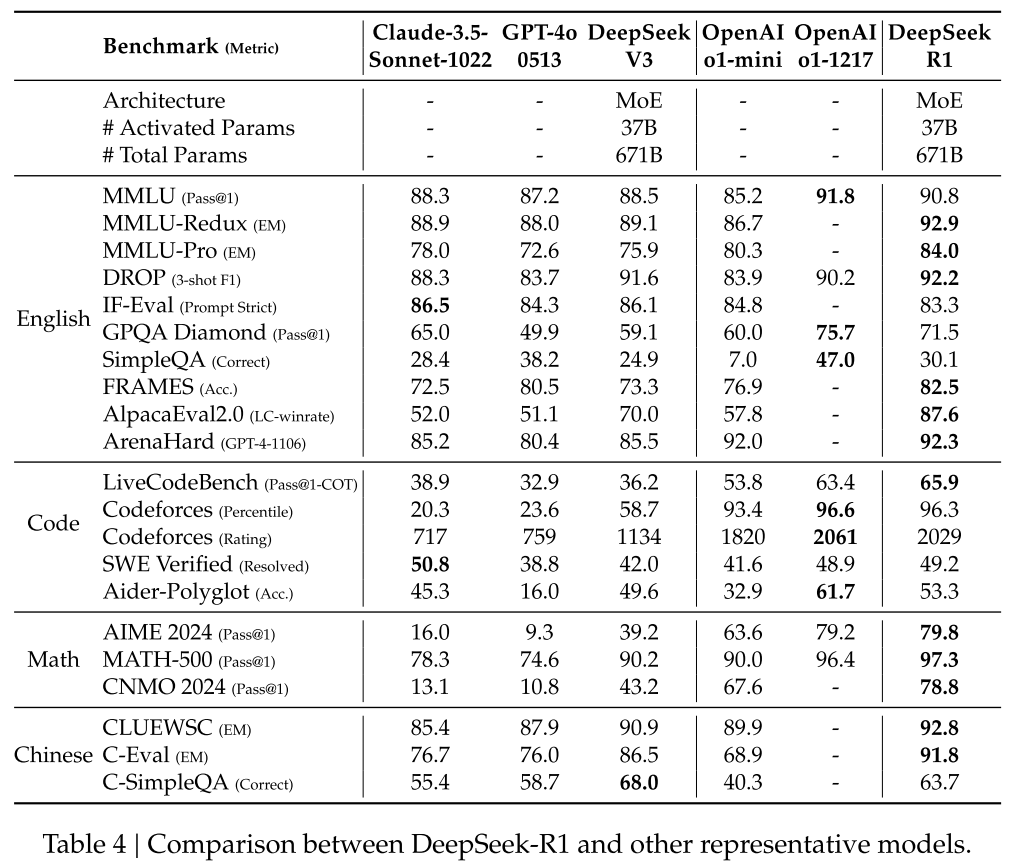
DeepSeek-R1:
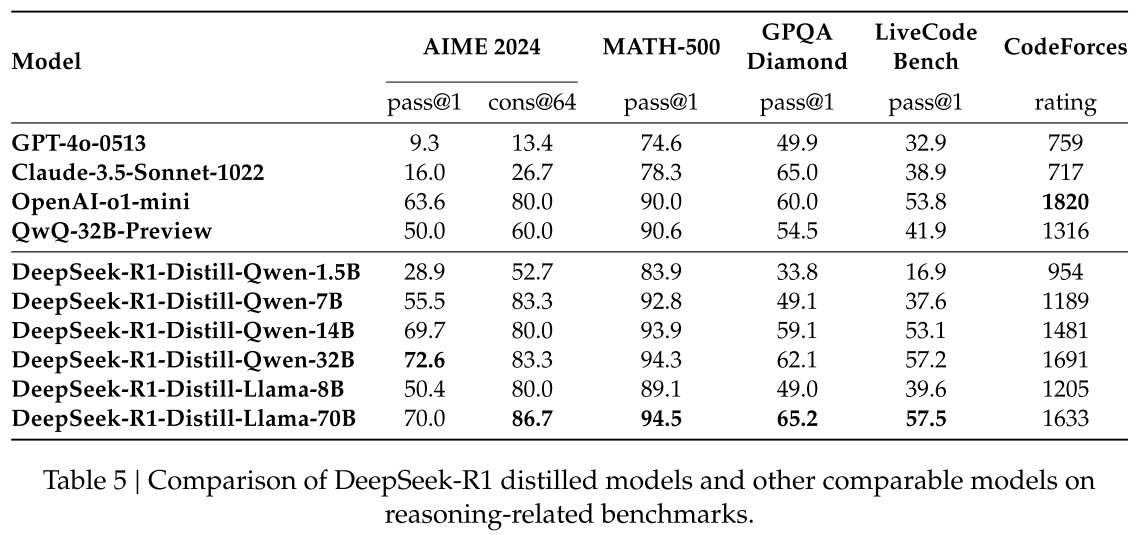
Distilled models:
Results:
Reasoning-intensive tasks:
- On AIME 2024: slightly surpass OpenAI-o1-1217.
- On MATH-500: on par with OpenAI-o1-1217, significantly outperform other models.
- On Codeforces: outperform most human participants.
- On engineering-related tasks: slightly better than DeepSeek-V3.
Knowledge-intensive tasks:
- On MMLU, MMLU-Pro, GPQA Diamond: significantly outperform DeepSeek-V3, slightly below OpenAI-o1-1217, surpass other closed-source models.
- On SimpleQA: outperform DeepSeek-V3.
Other tasks:
- creative writing, general question answering, editing, summarization etc.
- On AlpacaEval 2.0, ArenaHard: able to handle non-exam-oriented queries.
- long-context understanding
RQ5: Can model achieve comparable performance through the large-scale RL training without distillation?
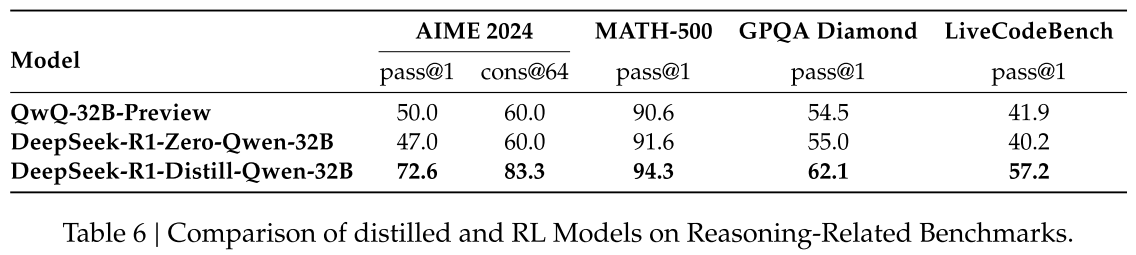
- Conduct large-scale RL training on Qwen-32B-Base using math, code, and STEM data for over 10K steps.
DeepSeek-R1-Zero-Qwen-32B - DeepSeek-R1-Distill-Qwen-32B >> eepSeek-R1-Zero-Qwen-32B
QwQ-32B-Preview
Conclusions:
- Reasoning capabilities of LLMs can be incentivized purely through RL, without the need for RL.
- Performance can be further enhanced with the inclusion of a small amount of cold-start data.
- The reasoning patterns of larger models can be distilled into smaller models.
- Distilling more powerful models into smaller ones yields excellent results.
- Smaller models relying on the large-scale RL require enormous computational power and may not even achieve the performance of distillation.
- Advanciong beyond the boundaries of intelligence may still require more powerful base models and larger-scale RL.
What are the advantages and limitations of this paper?
Advantages
Limitations
- Title: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- Author: Der Steppenwolf
- Created at : 2025-02-02 17:26:36
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/02/02/DeepSeek-R1/
- License: This work is licensed under CC BY-NC-SA 4.0.