AAAR-1.0: Assessing AI's Potential to Assist Research
Lou, Renze, Hanzi Xu, Sijia Wang, Jiangshu Du, Ryo Kamoi, Xiaoxin Lu, Jian Xie et al. “AAAR-1.0: Assessing AI’s Potential to Assist Research.” arXiv preprint arXiv:2410.22394 (2024). https://openreview.net/pdf/f0d5138537d20c3cef0e3185e203cdc6e582e4b2.pdf
What problem does this paper address?
Evaluation of LLMs/VLMs in assisting expertise-intensive research.
What are the background and motivation of this paper?
- Researchers face challenges and opportunities in leveraging LLMs for scientific research, e.g., brainstorming research ideas, designing experiments, and writing and reviewing papers.
- Existing works mostly focus on addressing highly subjective problems that require a high degree of expertise, making evaluation laborious and hard to reproduce.
- Most current LLMs struggle with processing diverse, extensive information from scientific documents.
- Many LLM-designed experiments are trivial, lack feasibility, and deviate from the original research objectives.
- LLM-generated weaknesses often lack sufficient domain knowledge, making them vague, general, and useless.
- It lacks systematic evaluations and quantitative analyses on LLM’s (intermediate) output of each single-step research task.
- Existing benchmarks mainly focus on the implementation and execution part of the research pipeline.
Research Questions:
- How effectively can AI assist in domain-specific, expertise-demanding and knowledge-intensive tasks, such as assisting research?
- For EquationInference:
- Do more contexts help the model better identify the correct equation?
- For ExperimentDesign:
- Can self-contained experiments enhance the explanation of motivation?
- Do human evaluation results align with automatic metriccs for explanation?
- Do more contexts help the model generate better experiment design?
- Does multi-modal input boost performance?
- For PaperWeakness:
- Is the split-combine effective?
- Does multi-modal input boost performance?
What are the main contributions of this paper?
- AAAR-1.0, a novel benchmark aiming to comprehensively assess the capacity of LLMs/VLMs on 3 distinct expert-level AI research tasks:
- [Task 1] EquationInference: infer the equation correctness based on the paper context
- [Task 2] ExperimentDesign: design reliable experiments for a research idea
- [Task 3] PaperWeakness: generate weakness criticism
- a dataset
- several task-specific metrics
Which tasks does the benchmark cover?

- [Task 1] EquationInference:
- Task Type: multi-class classification
- Input: task instruction + paper context + 4 candidate equations
- Output: the correct equation
- [Task 2] ExperimentDesign:
- Task Type: text(+image)-to-text generation
- Input: task instruction + pre-experiment paper context
- Output: experiment plan + motivation explanation
- [Task 3] PaperWeakness:
- Task Type: text(+image)-to-text generation
- Input: task instruction + full (yet splitted) paper context
- Output: a list of weaknesses
How is the benchmark created?

[Task 1] Equation Inference
- Data crawling and cleaning
- LLM-based equation synthesis
- LLM-based filtering
- Expert-based examination
[Task 2] Experiment Design
- Data crawling
- Domain-expert annotation
- Multi-round peer discussion
[Task 3] Paper Weakness
- Data crawling
- LLM-based weakness extraction
- Input-data processing
Data statistics:
- [Task 1] EquationInference:

- [Task 2] ExperimentDesign:
- [Task 3] PaperWeakness:
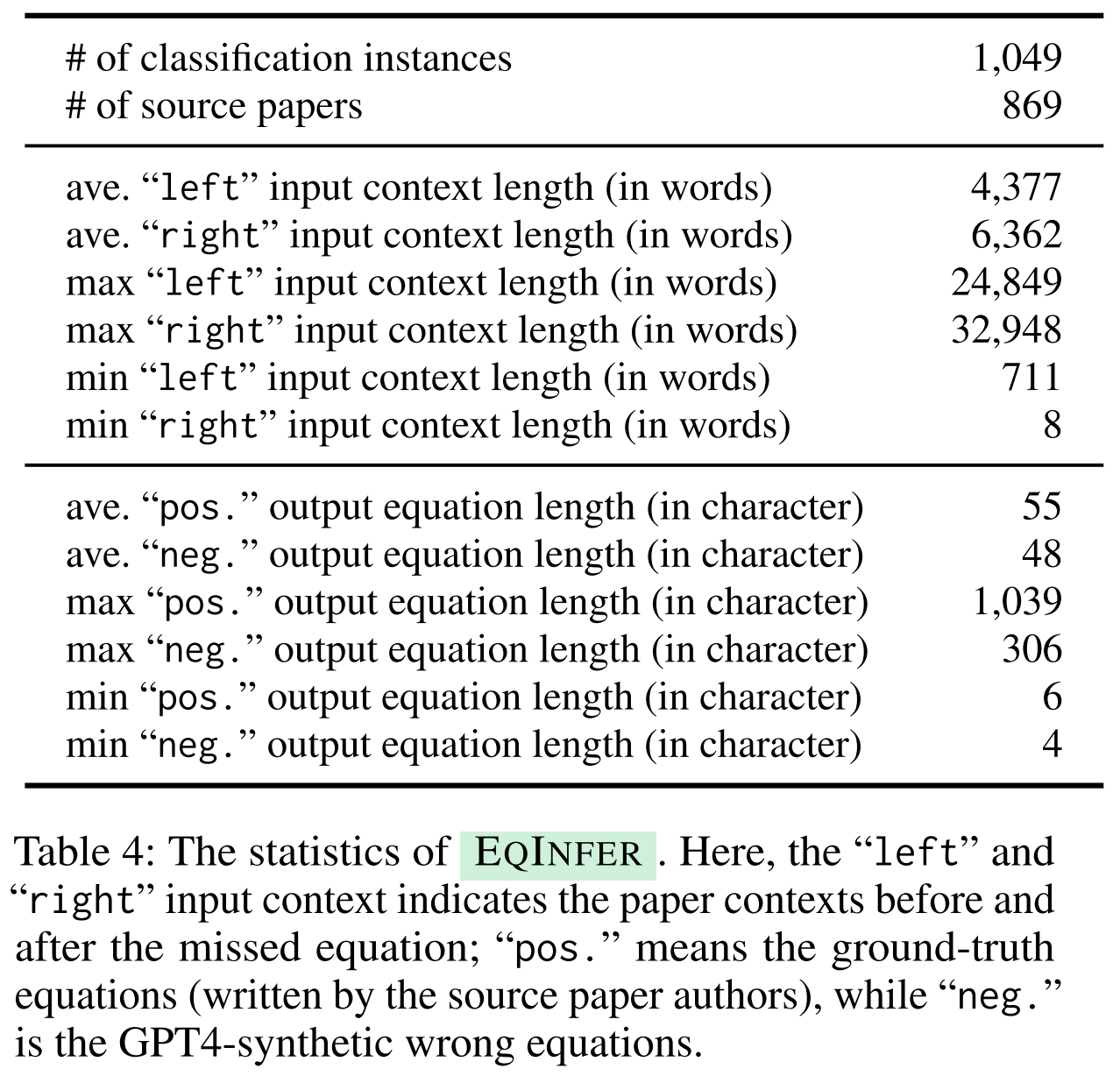
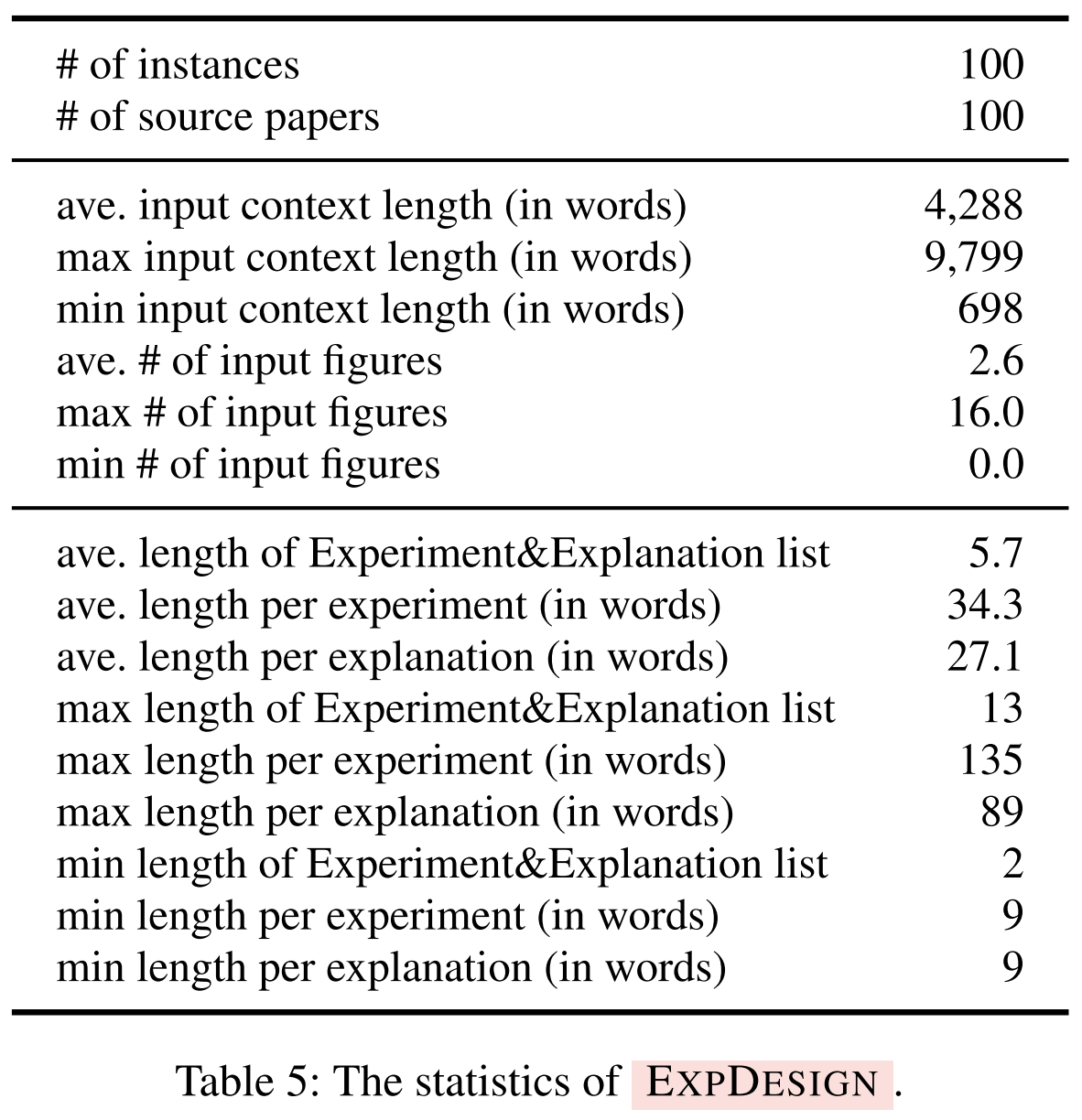
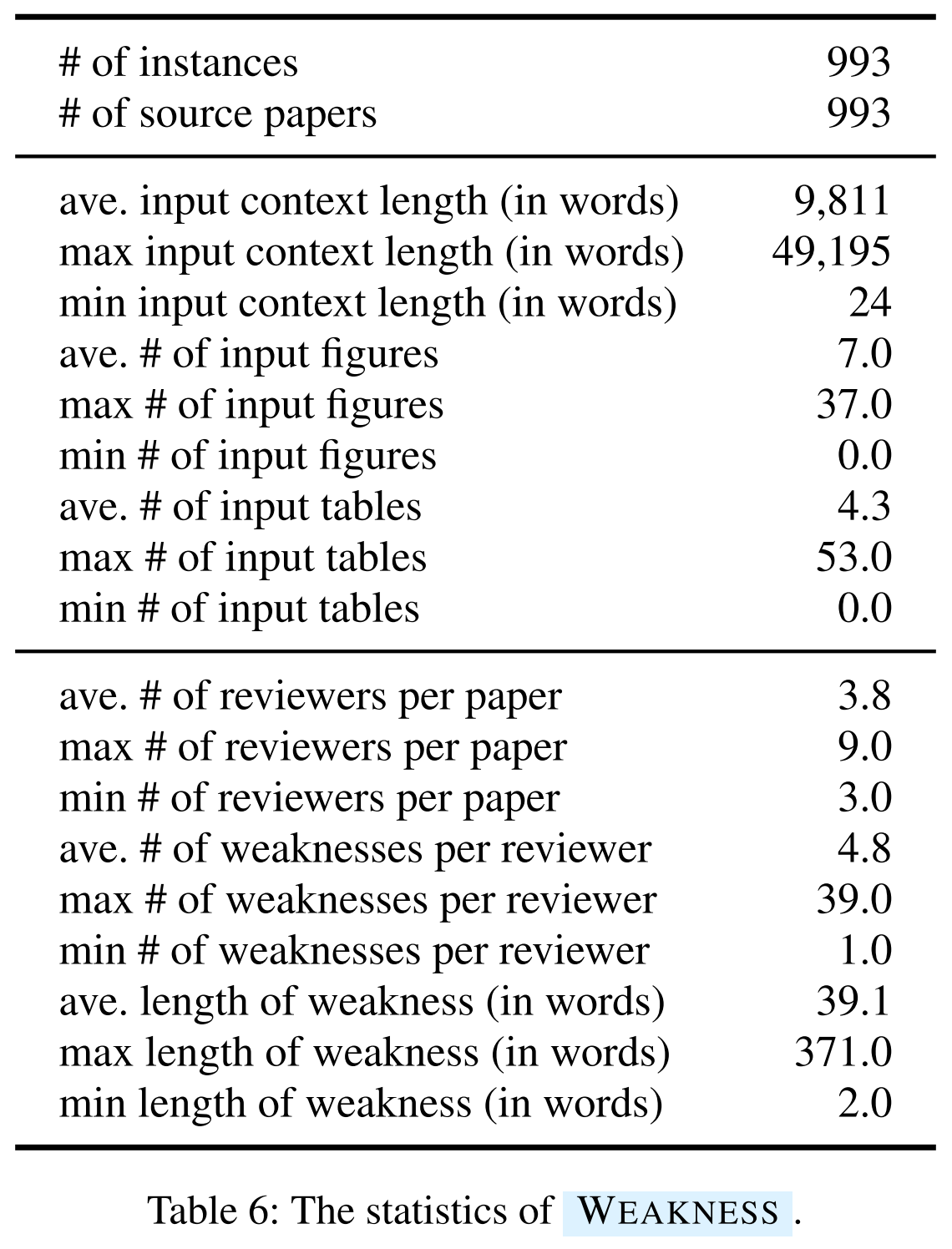
How does AAAR-1.0 differ from previous benchmarks?
What are the evaluation metrics?

, where : LLM-generated experiment plan, of length (number of experiment steps) : ground-truth plan, of length , where : number of reviewers for the given paper : length of the weakness list given by the -th reviewer : the -th item in the weakness list given by the -th reviewer : total number of papers in the dataset : the -th paper’s prediction weakness list : the -th weakness in calculates the intra-paper occurrence frequency of , measures informativeness is the “soft” number of papers that also contain , measures specificity
Which models are used for the evaluation?
LLMs (including VLMs used for text-only setting):
- Open-source:
- OLMo-7B
- Falcon-40B
- Gemma 2-27B
- Mistral-7B
- Mixtral-8x22B-MoE
- Llama 3.1-70B
- Qwen 2.5-72B
- Closed-source:
- gpt-4o-2024-08-06
- gpt-4-1106-preview
- o1-preview-2024-09-12
- gemini-1.5-pro-002
- claude-3-5-sonnet-20240620
- Open-source:
VLMs:
- GPT-4
- GPT-4o
- InternVL2-26B
Implementation Details to Experiment:
- Metrics are calculated using SentenceBERT (SBERT), taking 1GB on a single A100.
- Use VLLM to unify the inference points of all open-source models, using PyTorch 2.4.0 with CUDA 12.1, on 8 A100.
- Use LiteLLM to unify the API calling of all closed-source models.
- Run each model 3 times and select the median result.
What are the results and conclusions?
Text-only Results



Multi-modal Results


What are the main advantages and limitations of this paper?
What insights does this work provide and how could they benefit the future research?
- Title: AAAR-1.0: Assessing AI's Potential to Assist Research
- Author: Der Steppenwolf
- Created at : 2025-01-22 10:21:38
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/01/22/AAAR-1-0/
- License: This work is licensed under CC BY-NC-SA 4.0.