MMSci: A Dataset for Graduate-Level Multi-Discipline Multimodal Scientific Understanding
Li, Zekun, Xianjun Yang, Kyuri Choi, Wanrong Zhu, Ryan Hsieh, HyeonJung Kim, Jin Hyuk Lim et al. “Mmsci: A dataset for graduate-level multi-discipline multimodal scientific understanding.” arXiv preprint arXiv:2407.04903 (2024).
Other literature: https://hub.baai.ac.cn/paper/04ea5a09-4349-458e-b33b-5195ad2d571e
What problem does this paper address?
Benchmarking multimodal multi-discipline scientific document comprehension.
What is the motivation?
Current datasets and benchmarks on multimodal scientific understanding primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines.
What are the main contributions of this paper?
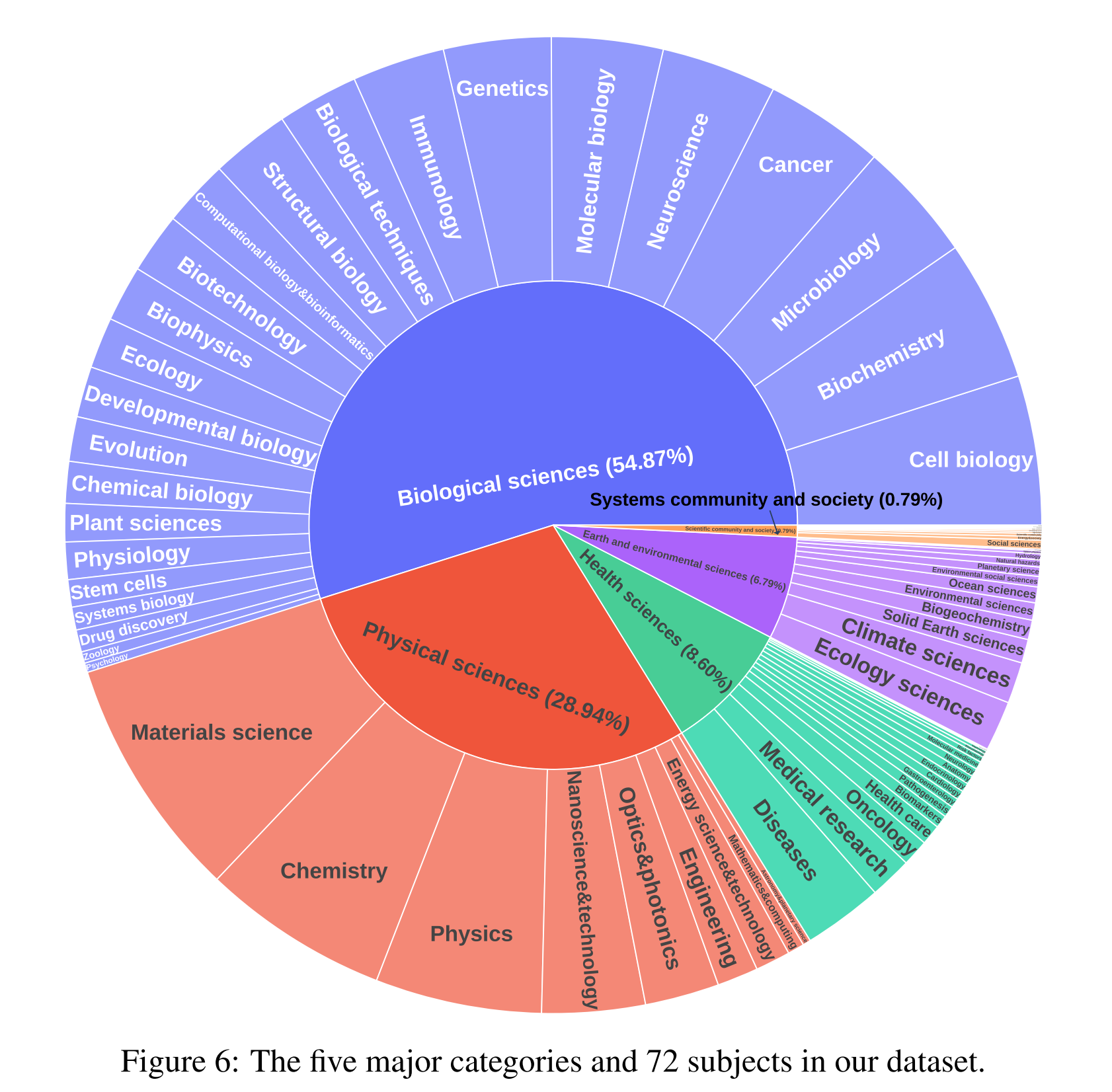
- This paper releases MMSci, a multimodal multi-discipline dataset spanning across 5 major scientific categories and 72 subjects.
- This paper benchmarks with various tasks and settings for the evaluation of LLM’s (and VLM’s) capabilities in understanding scientific figures and content.
- This paper constructs visual instruction-following data with discussions about figure content, structured as single or multi-turn interactions.
What tasks are included in the benchmark?
- Scientific Figure Captioning (SFC)
- Multi-Choice Visual Question Answering (VQA)
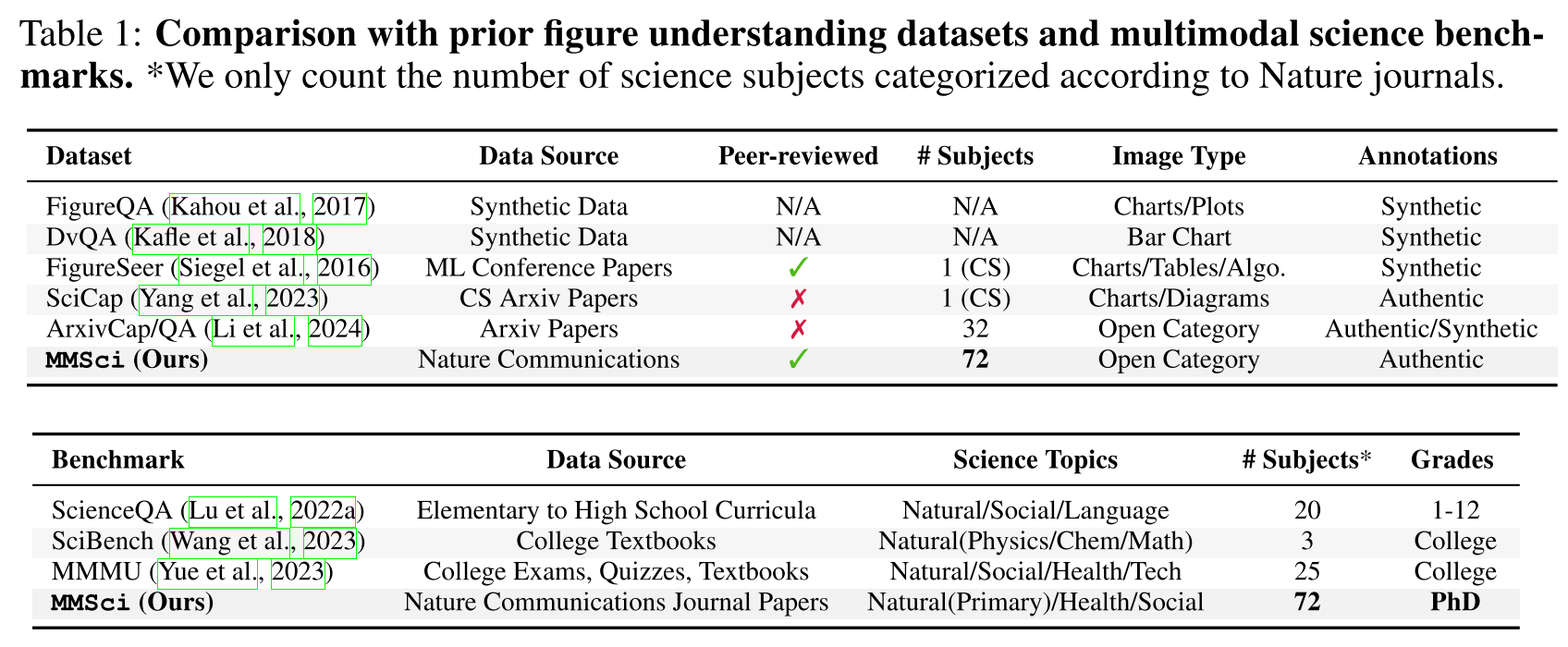
How does MMSci differ from existing datasets?
For scientific figure understanding:
- Previous:
- limited range of subjects
- not peer-reviewed
no guarantee of quality
- MMSci:
- emphasizes natural science disciplines
- high-quality, peer-reviewed articles and figures
- data sources from Nature Communications journals
For multimodal science problems:
- Previous:
- from elementary to high school levels
- limited range of subjects
- MMSci:
- Ph.D.-level scientific knowledge
- diverse subjects
Data Statistics
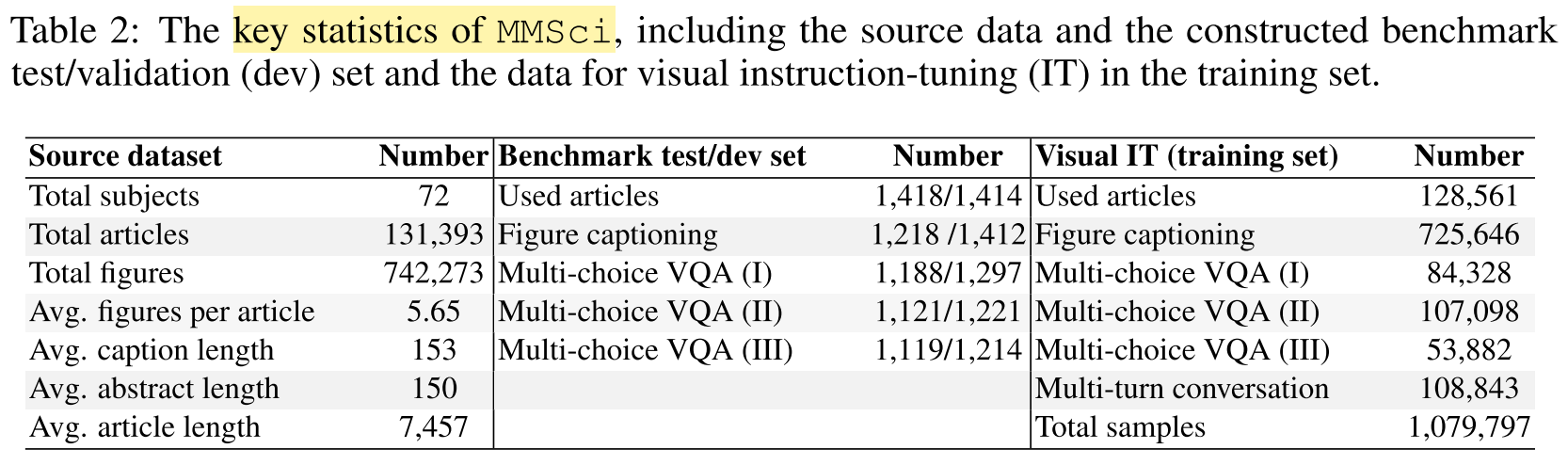
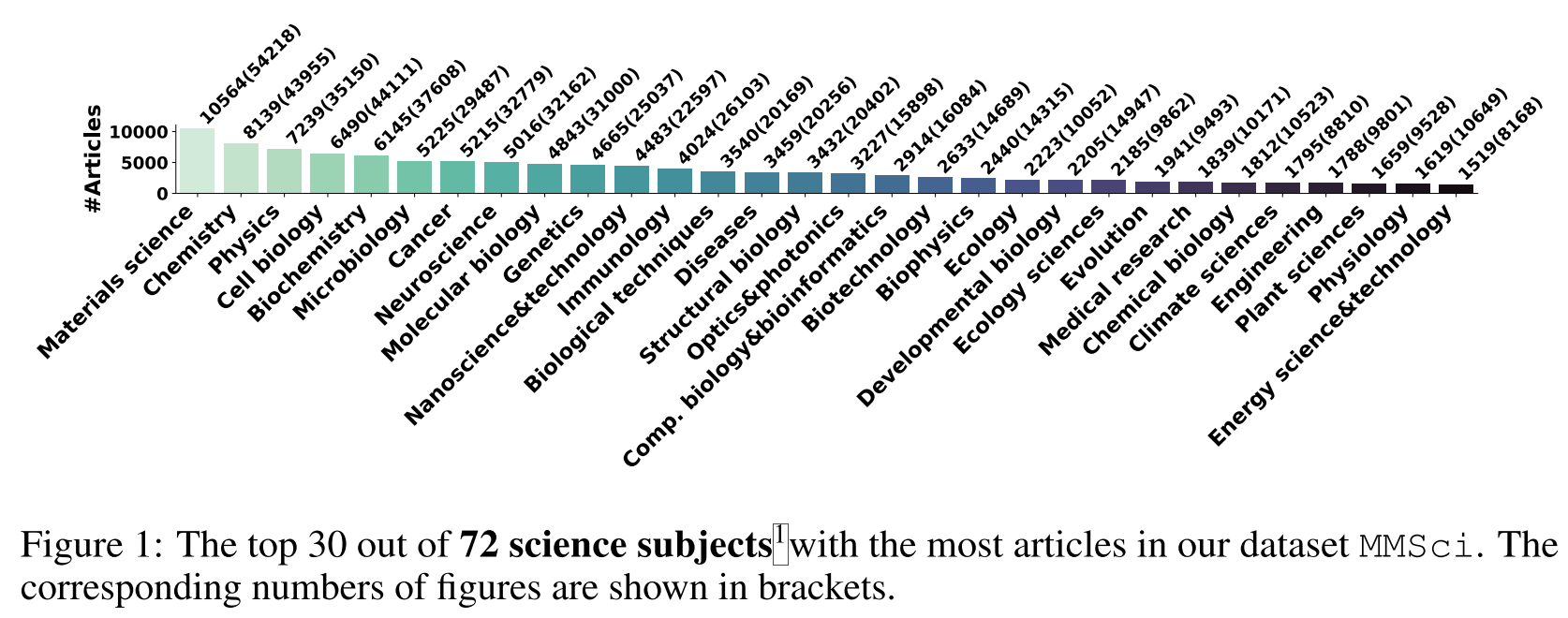
How is the data curated?
1. Source Data Collection
- Data source: Nature Communications website, open-access, peer-reviewed papers, 5 major categories and 72 subjects
- Input: an article page and its dedicated figure page up to the date of 15.04.2024.
- For each article, collect its
- title
- abstract
- main body content
- references
- figures and captions
- Convert LaTeX expressions of mathematical formulas in article text and figure captions into plain text using pylatexenc.
- Output: a source dataset comprising 131,393 articles and 742,273 figures
2. Sub-caption Extraction
- Motivation: Many figures in the source dataset consist of multiple sub-figures in a single image, with captions that include a main caption and multiple sub-captions.
- Input: the source dataset
- Develop a regular expression matching function to identify sub-figure indices at the beginning of sentences in alphabetical order (a-z).
- Output: 514,054 sub-captions and sub-figures
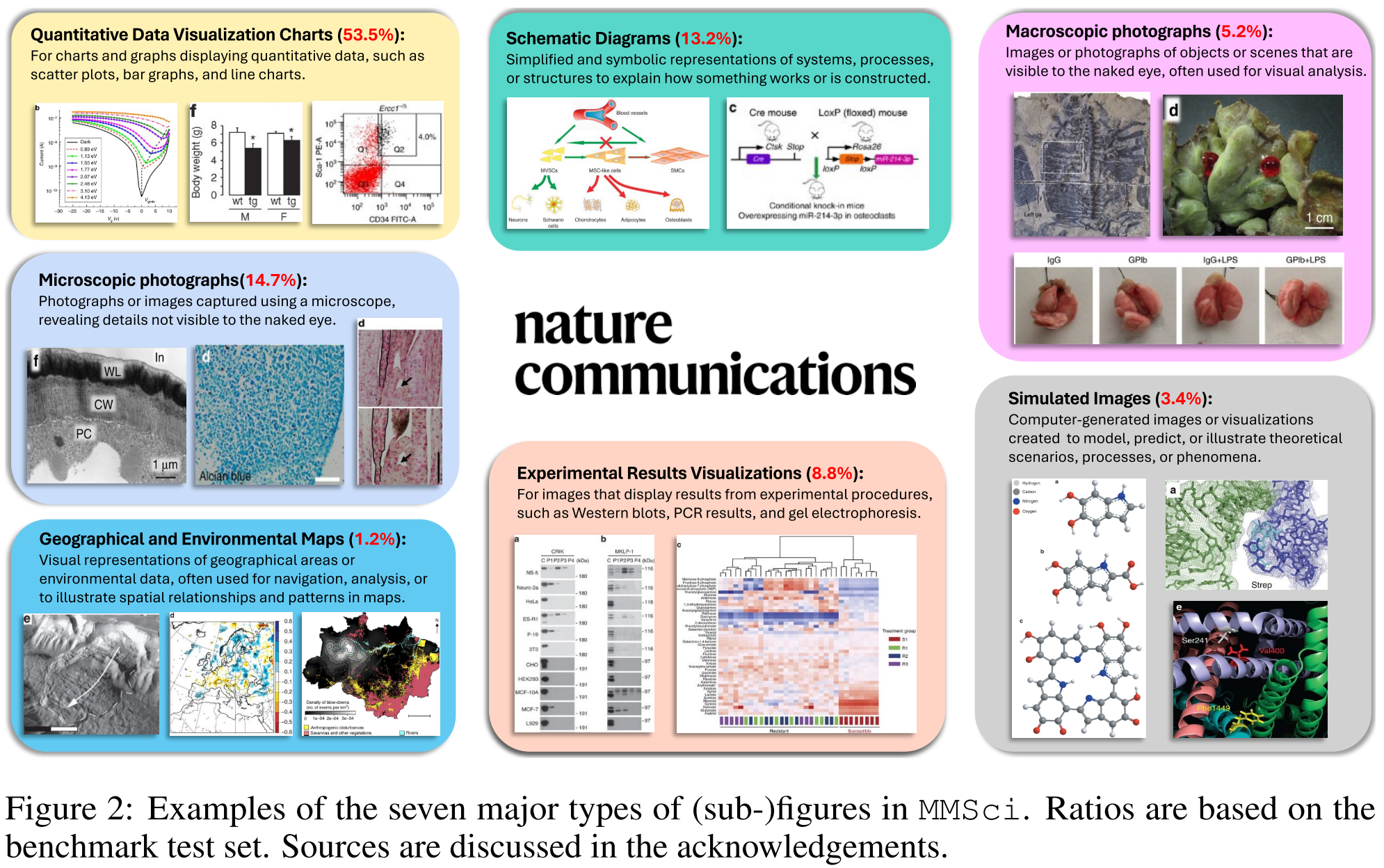
3. Exploring Figures in MMSci
- Manually summarize and categorize the potential figure types into 7 major categories, based on the subfigures in a subset of all the figures.
- Classify the images within the benchmark test set into the 7 categories using GPT-4o.


Benchmark

Scientific Figure Captioning (SFC) Task
Why is SFC harder than natural image captioning?
- requires grouding and understanding the article’s content with background knowledge
- significantly more details, providing rich complementary information to the article
- much longer captions (avg. 153 words)
Three captioning settings:
- Ungrounded figure captioning: Model generates captions without any article content.
- Abstract-grounded figure captioning: Model generates captions conditioned on the paper abstract.
- Full content-grounded figure captioning: Model generates captions conditioned on the entire article content.
Multi-Choice Visual Question Answering (VQA) Task
- Given a (sub-)figure, select the (sub-)caption that best describes it, from either
- (Setting
) the correct main caption of the figure, and three main captions from other figures within the same article, or - (Setting
) the correct sub-caption of the sub-figure, and three sub-captions from other sub-figures within the same article, or - (Setting
) all sub-captions from the same sub-figure.
- (Setting
Setting
Setting
Setting
Data Split
- Allocate 1% of articles from each subject to the test set, and another 1% of articles to the dev set.
- Each subject contains 5 to 50 articles.
- 1,418 articles for test set, 1,414 articles for dev set.
- Each test sample is derived from a single article, ensuring no reuse of content.
- Captions are ensured to contain more than 50 words.
- Each task and setting contains approx. 1,200 samples, balancing coverage, diversity, and cost for benchmarking.
Training Resources
Visual Intruction-Following Data
- Data source: articles that are not used for creating the benchmark (dev & test sets)
- Conversations discussing figure content, in the form of
- SFC (single-turn, abstract-grounded)
- VQA (single-turn)
- Multi-Turn Conversation (multi-turn)
In each turn:- human asks about content in a sub-figure
- assistant responds with the corresponding sub-caption
- 108,843 multi-turn conversations
- over 1 million visual instruction-following conversations
Interleaved Text and Image Data for Pre-training
- Insert the figures into the article content at the location of their first mention.
Which models are used for evaluation?
Open-source VLMs:
- Kosmos-2
- BLIP-2
- Qwen-VL-Chat
- LLaVA1.5-7B
- LLaVA-Next (LLaVA1.6-Vicuna-7B)
- LLaVA-Next-Mistral (LLaVA1.6-Mistral-7B)
Closed-source VLMs:
- GPT-4V
- GPT-4o
LLaVA-Next-MMSci: Fine-tune a LLaVA-Next model using visual instruction-following data (~1080k training samples, one epoch)
Which evaluation metrics are used?
SFC Evaluation
Reference-based metrics: comparing the generated captions with the oracle captions
- BLEU
- ROUGE
- METEOR
- BERTScore
Reference-free metrics: directly comparing the generated captions with the images
- CLIPScore
- RefCLIPScore
What are the results and conclusions?
Scientific Figure Captioning (SFC)
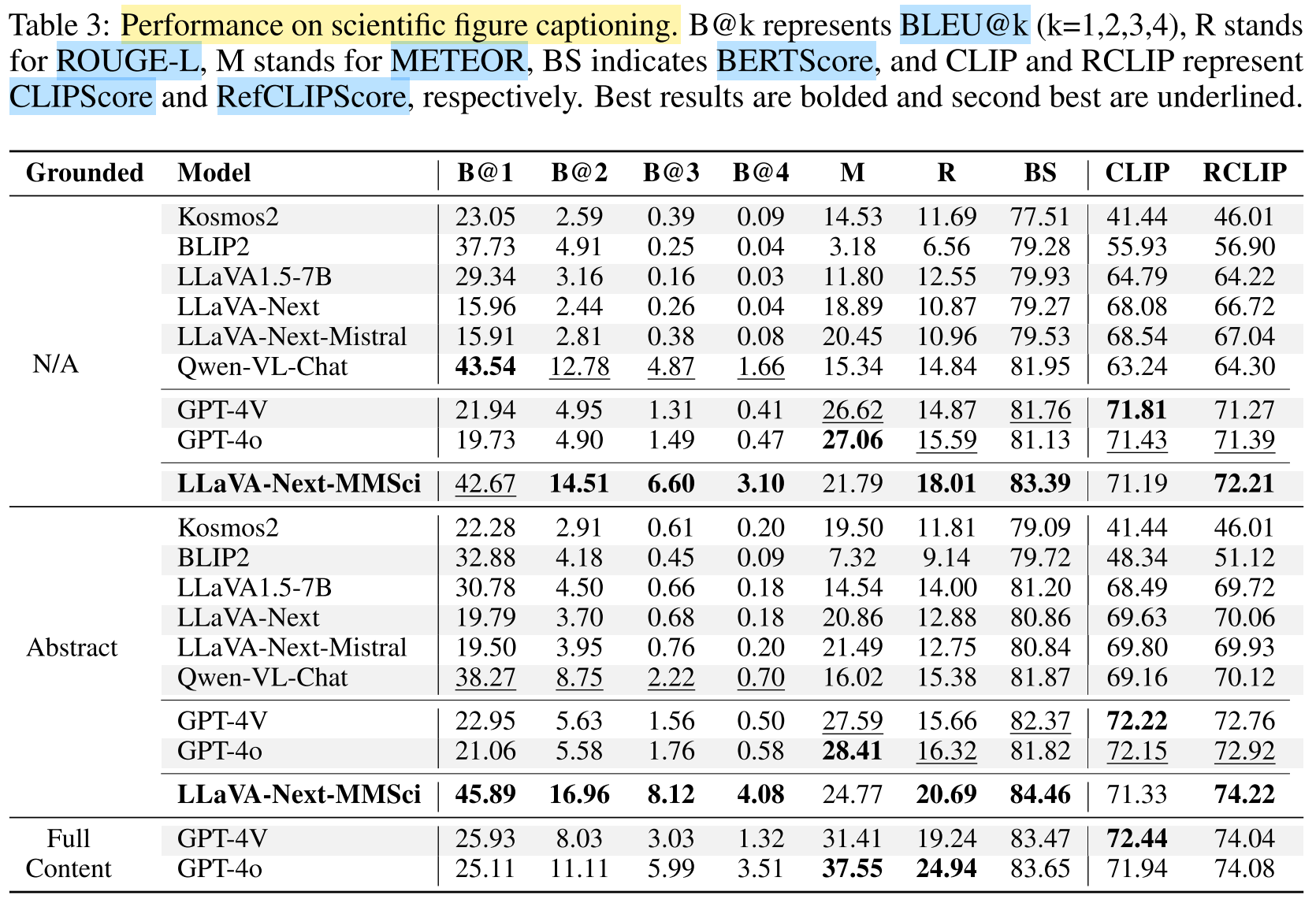
- Results:
- Providing the full article content, GPT-4o achieves the highest METEOR and ROUGE scores.
- Providing only the abstract content or no article information, open-source models show significantly lower performance, instruction-tuned model (LLaVA-Next-MMSci) achieves achieves the best results across most metrics.
- Conclusions:
- Grounding the captions to article information improves generation quality.
- Open-source models struggle to generate accurate and relevant captions without sufficient context (i.e. full article) in zero-shot manner.
- Fine-tuning open-source models with instruction-following data helps improve their performance.
- Proprietary models (GPT-4V/o) perform well on METEOR and CLIPScore.
Visual Question Answering (VQA)
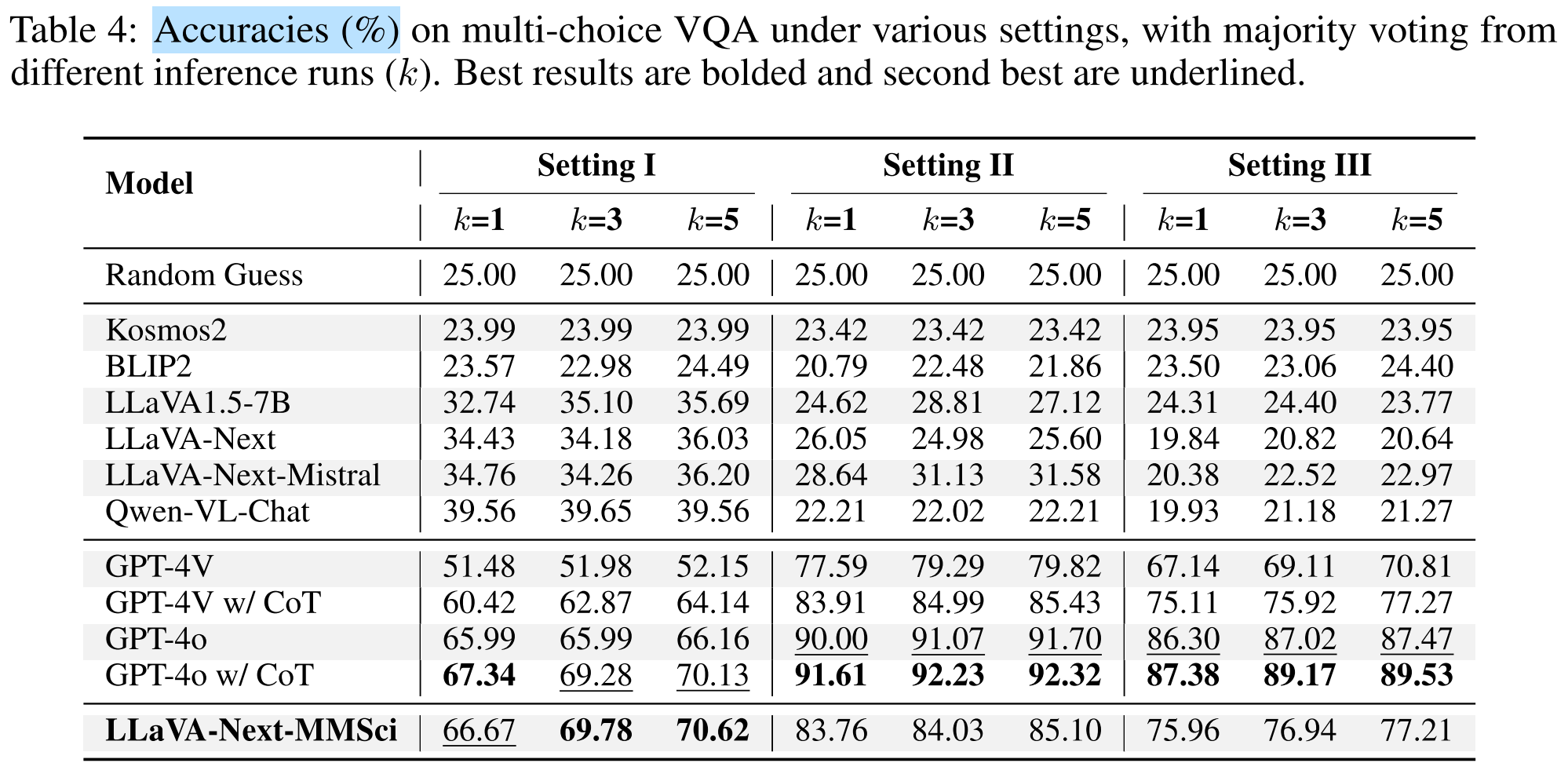
- Results:
- Open-source models slightly outperforms random guess only in Setting
. In Setting and , all open-source models perform worse than random guess. - The instruction-tuned model excells in Setting
, and achieves performance comparable to or even better than GPT-4V. - GPT-4o performs best in Setting
and . - CoT consistently improves accuracy for GPT-4V and GPT-4o.
- Open-source models slightly outperforms random guess only in Setting
- Conclusions:
- GPT-4o is better at locating and distinguishing specific areas or sub-figures within the whole figure.
- The instruction-tuned model is better at summarizing the entire figure.
- This task requires reasoning ability (reasoning-intensive task).
- The visual instruction-following data is effective.
A Case Study in Material Science
Motivation:
- Material science is highly interdisciplinary, requiring knowledge from various subjects.
- Material science is the subject with the most articles and figures in MMSci.
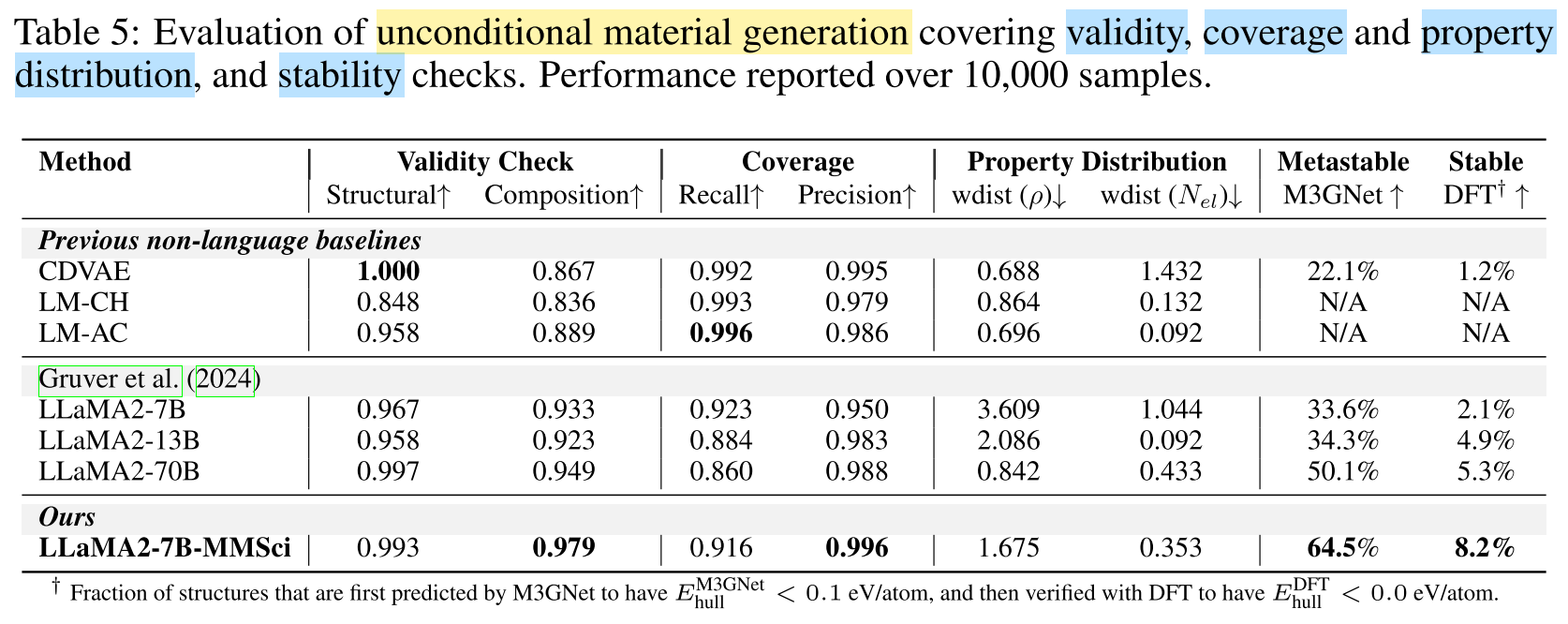
Recent study (Gruver at al., 2024)
- achieved promising results using LLaMA2 on material generation task
- represent material crystal structures as text strings
- train the model to generate these structure strings
Limitation: LLaMA2 may lack sufficient scientific knowledge to fully comprehend the principles of material generation.
Solution: Adopt continuous pre-training for LLaMA2-7B using the interleaved text and image data.
Continuous Pre-training
- Equip LLaMA2-7B with a pre-trained CLIP ViT-L/14-336 as the visual encoder and a 2-layer MLP as the projector (i.e. leveraging LLaVA’s architecture), in order to inject multimodal knowledge from MMSci into LLaMA2-7B.
- Freeze LLaMA2-7B and initialize the MLP projector using data from general domains provided by Liu et al., 2024.
- Continuously pre-train the model on the interleaved text and image data from general domains in MMC4 dataset (Zhu et al., 2024) to further develop its image perception abilities.
- Continuously pre-train the model on the interleaved text and figures within the Physical Science major category of MMSci, which includes materials science and other eight related subjects.
- Use only the LLM part of the model (LLaMA2-7B-MMSci) for the text-only material generation.
Fine-tuning for Materials Generation
- Further fine-tune the LLM part of the model for material generation task (Gruver et al., 2024).
- Prompt:
- blue part: conditions, such as formula, space group, energy above hull, etc.
- red part: the generated representation of the crystal structure
- text in black: the prompt
- Results:

Appendix
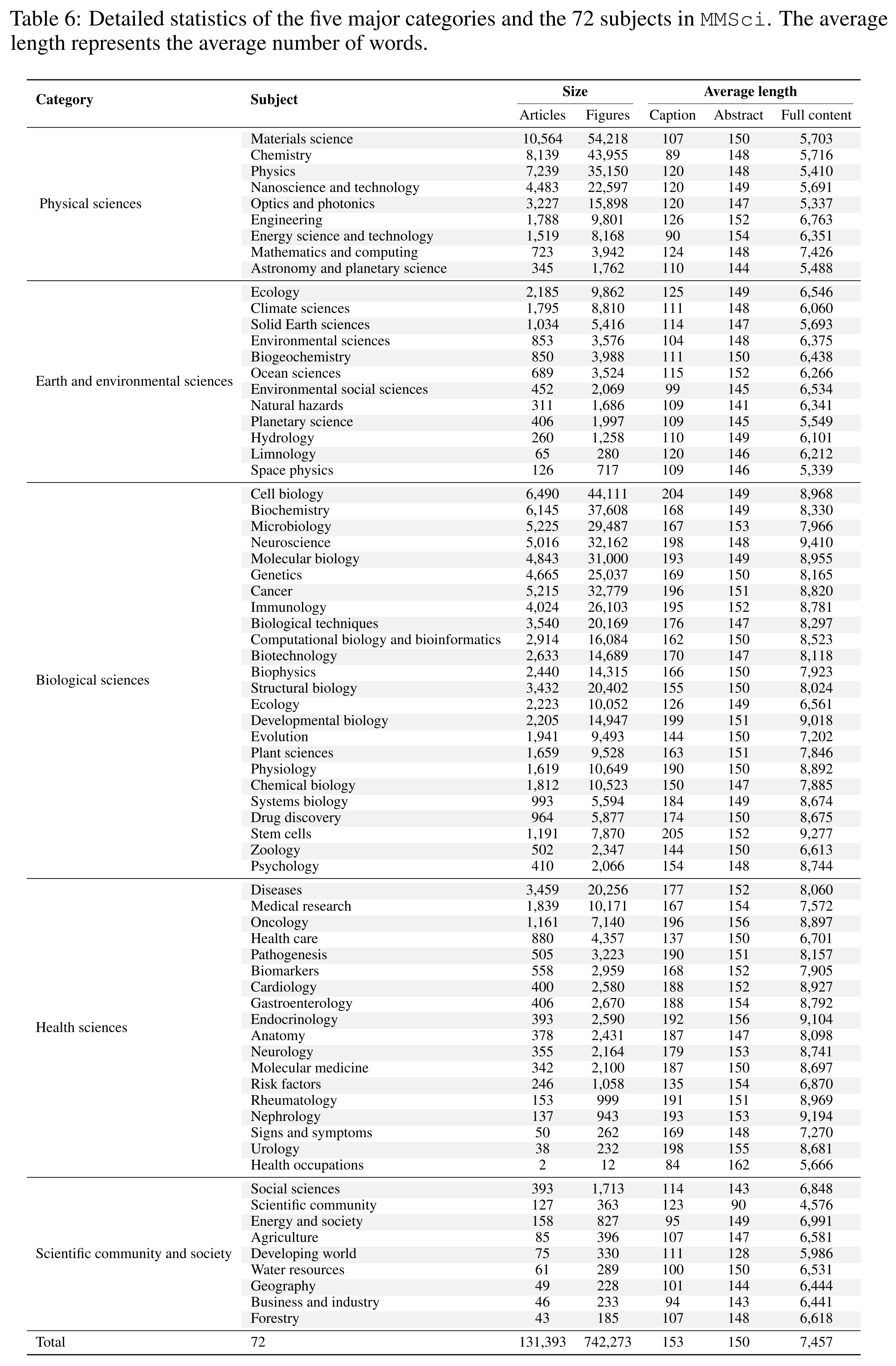
Full List of 5 Major Categories and 72 Subjects
- Title: MMSci: A Dataset for Graduate-Level Multi-Discipline Multimodal Scientific Understanding
- Author: Der Steppenwolf
- Created at : 2025-01-18 11:16:55
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/01/18/MMSci/
- License: This work is licensed under CC BY-NC-SA 4.0.