Battlespace: Using AI to Understand Friendly vs. Hostile Decision Dynamics in MDO
Hare, J. Zachary, B. Christopher Rinderspacher, Sue E. Kase, Simon Su, and Chou P. Hung. “Battlespace: using AI to understand friendly vs. hostile decision dynamics in MDO.” In Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications III, vol. 11746, pp. 268-277. SPIE, 2021.
What is the motivation of this paper?
- Future Multi Domain Operation (MDO) wargaming will rely on AI / ML algorithms to aid and accelerate complex Command and Control decision-making.
- Complex MDO decision-making requires new algorithms that can
- operate in dynamic environments with
- changing rules
- uncertainty
- individual biases
- changing cognitive biases
- rapidly mitigate unexpected hostile capabilities
- rapidly exploit friendly technological capabilities
- operate in dynamic environments with
- Existing algorithms are inadequate to address the complexity of wargame modeling of MDO.
What is the hypothesis of this paper?
New algorithms for learning and reasoning under uncertainty, game theory with three or more players, and interpretable AI can aid in complex MDO decision-making.
What is the goal of this paper?
To develop a flexible wargaming platform for developing novel reinforcement learning algorithm for multi-player decision-aids with three or more adversarial players.
Research Questions:
- How can human decision-making be leveraged by and synergized with AI?
- How coordinated actions by the human teammates relate to known game theoretic principles?
- How may these actions be extended to three or more adversarial players?
- How does a simple agent mimicking these human action heuristics beat a random agent?
What are the main contributions of this paper?
- Battlespace, a new flexible MDO warfighter machine interface game.
- Experiments with human vs. random AI agents operating in a fixed environment with fixed rules, where the overall goal of human players is to collaboratively capture the opponents’ flags or eliminate all of their units.
- Analyses of the evolution of the games and identification of key features characterizing human players’ strategies and their overall goal.
- Modeling of the human strategies and development of heuristic strategies for a simple AI agent.
What are the main characteristics of Battlespace wargaming platform?
- twenty game plays
- two human players vs. two random adversarial AI agents
- two types of objectives:
- Capture-the-Flag: maneuver the ground units into the enemy territory to capture the opposing teams’ flag (flag locations are unknown)
- Annihilation: discover and attack all of the enemy units
- visualization of the wargame using the Augmented REality Sandtable (ARES) platform
What is the game design?
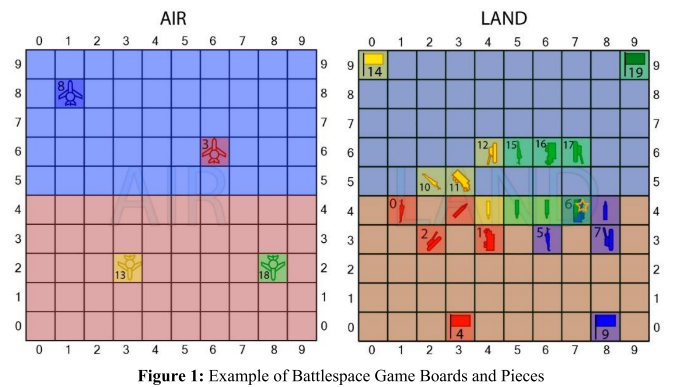
- 2 teams: red, blue
- multiple players per team
- each team is analogous to an alliance
- each player represents an actor
- two domains: “Air”, “Land”
- sa common battlespace designed as a set of boards for each domain
- board comprises square grids
- each player has a set of pieces (“Units”)
- 4 ground units: a Soldier, a Tank, a Truck, a Flag
- 1 air unit: an Airplane
- action spaces:
- Soldier, Tank, Truck:
- doNothing: stay in the current location and keep the current orientation
- turnH: rotate the orientation by
degrees, {-135, -90, -45, 0, 45, 90, 135} - advance1: move one cell forward in the cirection of the current orientation
- shoot: shoot a projectile in the direction of the current orientation, where the projectile continues to advance by one cell forward until it either collides with another unit or travels outside of the game board
- ram: advance the unit one cell forward in the direction of the current orientation, while perform shooting
- Airplane:
- doNothing: same as above
- turnH: same as above
- advanceX,Y: move
cells along the East-West axis and cells along the North-South axis - shoot: same as above
- bomb: shoot a projectile directly below the airplane onto the land game board
- Flag: unable to move and remain in the its location until the end of the game or it is captured
- Soldier, Tank, Truck:
What are the rules of the game?
Repeat until game completion:
- Each player places their pieces on the section (evenly divided) of the game board, where the location of each unit is unknown to the other players.
- Each unit observes if there are any other units within their visible range (one square of the current location).
- Onnce each unit observes, the players on the same team collaborate to identify the set of actions they would like to take for each of their units.
- Each player selects an action for each unit. The actions chosen are only known to the player and their teammates.
- After all players have selected an action, a game resolution is applied to move the pieces according to their actions and resolves whether any units have been attacked or collided with each other. If a unit is attacked by or collided with another unit, it is removed from the board.
Criteria for game completion:
- Capture-the-Flag game: Game is terminated once all of the enemy flags have been captured.
- Annihilation game: Game is terminated once all of the enemy units are eliminated.
High uncertainty due to limited visibility of enemy units and flags.
Game Visualization
Why is the development of a visualization component important?

Text-based formatted table:
- lack of understanding
- difficulty in interpretation
- general sustained confusion among human players during testing
- poor decision-making (same team unit collision, friendly fire unit destruction etc.)
Battle command and situational awareness require decision-making based on information visualization of the current and future operational states.
Goals:
- improve battlespace visualization
- provide a user-defined common operating picture
- increase decision-making capabilities
The Augmented REality Sandtable (ARES) Platform
- a system for visualizing a battlespace possessing key attributes such as customizability and interactivity of geospatial terrains
- a map of an area of operations based on available data from Google Maps, OpenStreetMaps, OpenTopoMap, or USGS
- 2D (top-down) or 3D view
- three visualization modes: virtual reality (VR), augmented reality (AR), mixed reality
- blue-colored symbols: Friendly team; red-colored symbols: Hostile team
- deployed on DoD Supercomputing Resource Center (DSRC)
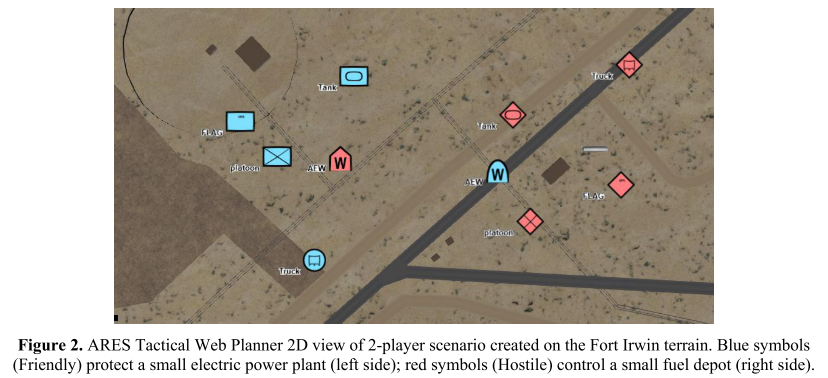

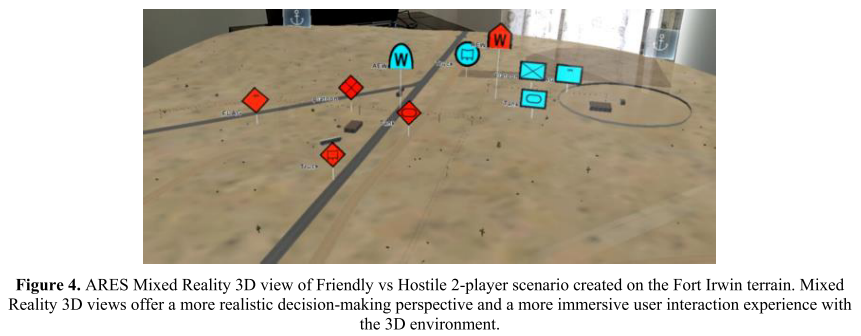
How are the experiments conducted?
- participants: 5 human subjects, 2 AI agents in total
- During each turn, each random agent selects an action for each unit
from a fixed categorical distribution. , - Each game consists of two human subjects vs. two random agents.
- 20 games, 10 for Capture-the-Flag, and 10 for Annihilation.
- Once all 20 games have been conducted, analyze the collected data to identify human strategies.
Game Data Analysis
Study the frequency of actions taken by the human players:
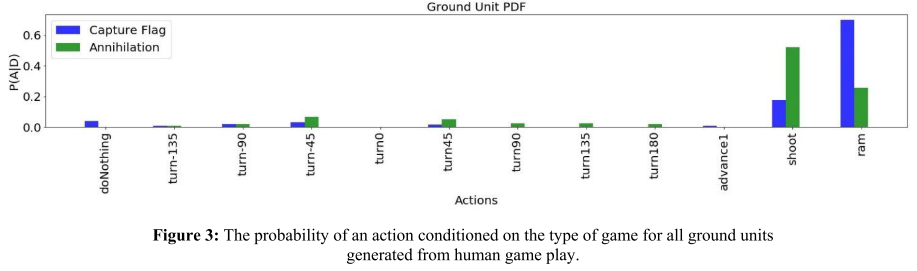
- For Capture-the-Flag game, ground units are more likely to choose an Advance and Attack approach via the ram action to search for the flag.
- The action doNothing is chosen relatively more frequently.
- Human subjects are more likely to choose the advance1, -2 action for the air unit to advance the unit into enemy territory to search for the flag.
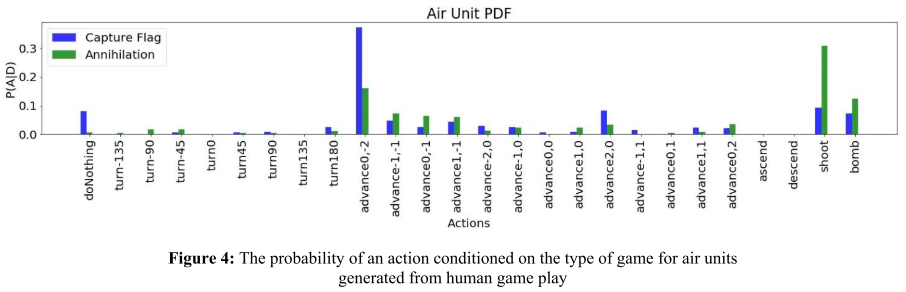
- For Annihilation game, human subjects are more likely to choose attack-related actions, i.e.
shoot for the ground units, as well as shoot and bomb for the air unit.
Differences in the results for the two game types:
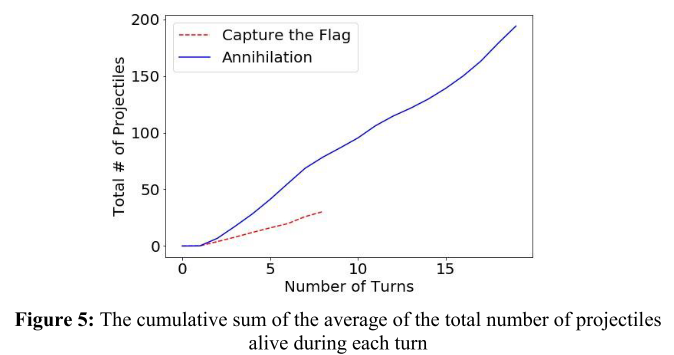
- number of projectiles: Annihilation > Capture-the-Flag
- total number of turns: Annihilation >> Capture-the-Flag
(Reason: Human agents are able to find the flag faster than to find the enemy units and eliminate them.)
Learning from Historical Game Data
Model the probability of taking an action as a categorical distribution:

Why does the simple frequentist approach to model
not work? - limited data
some action-state pairs may not exist in the collected game data epistemic uncertainty in must be incorporated
- limited data
How to incorporate the epistemic uncertainty in
instead? - By utilizing a prior on the distribution of
following a Bayesian approach.
- By utilizing a prior on the distribution of
How to identify the prior?
- Count the number of times a unit taking an action in a particular state, using the collected game data
: - Model the distribution of
according to a Dirichlet distribution: where
: a multivariate beta function - Why Dirichlet distribution?
- It is the conjugate prior of a categorical distribution.
- How to determine the hyperparameters
and ? - Using Bayesian Bootstrap and imprecise Dirichlet models.
- Count the number of times a unit taking an action in a particular state, using the collected game data
Compute the probability of taking an action
as the posterior predictive distribution (i.e. the expected value of the action probabilities conditioned on the posterior Dirichlet distribution, conditioned on the collected game data):
- Why using posterior predictive distribution instead of frequency distribution?
- The probability of an action-state pair is always positive, even if it is not collected in the game data.
- Why using posterior predictive distribution instead of frequency distribution?
Compute the probabilities of joint actions and states:
: number of times the joint actions and states are taken, : hyperparameter
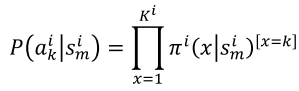
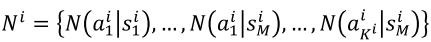
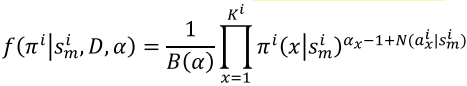 where
where
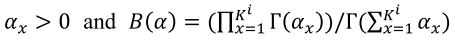
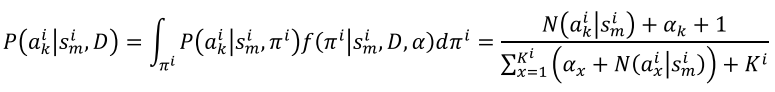
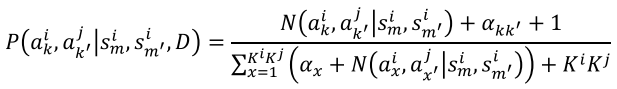
Performance of a Simple AI Agent
Algorithm for the AI agent:
Repeate during each turn until game terminates:
- Randomly place its units in the designated area of the board.
- Identify the state of each unit.
- Given the state and the goal of the game, draw an action for each unit from a predefined distribution
Winning proportion of the simple AI agent against two random agents:
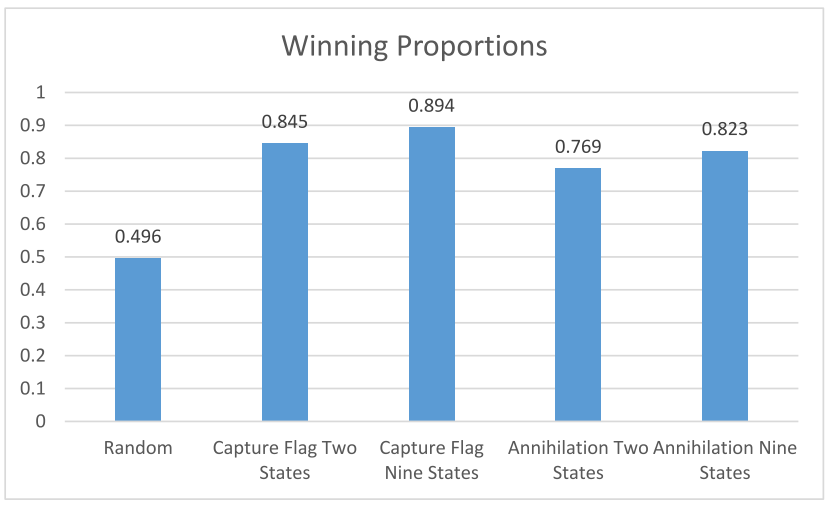
- In both two state distribution and nine state distribution, the Capture-the-Flag strategy outperforms the Annihilation strategy, since Annihiliation is more likely to select the shoot action which results in more frequent friendly fires due to random initial placement.
- The winning percentage increases when considering additional states of the units.
Future Work
- Collect additional game play data.
- Develop deep RL algorithms that integrate Theory-of-Mind to learn asymmetric reward expectations under 3+ player Nash equilibria.
- Study complex decision-making when the underlying rules of the Battlespace game change.
- Title: Battlespace: Using AI to Understand Friendly vs. Hostile Decision Dynamics in MDO
- Author: Der Steppenwolf
- Created at : 2025-01-16 09:40:45
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/01/16/Battlespace/
- License: This work is licensed under CC BY-NC-SA 4.0.