MACT: Efficient Multi-Agent Collaboration with Tool Use for Online Planning in Complex Table Question Answering
Zhou, Wei, Mohsen Mesgar, Annemarie Friedrich, and Heike Adel. “Efficient Multi-Agent Collaboration with Tool Use for Online Planning in Complex Table Question Answering.” arXiv preprint arXiv:2412.20145 (2024).
What problem does this paper address?
Complex table question answering
What is the motivation of this paper?
- Fine-tuning LLMs requires high-quality training data, which is costly and hard to obtain.
- Prompting closed-source commercial LLMs can be costly and poses challenges to accessibility and reproducibility.
- A single LLM struggles with performing different types of reasoning, especially if it does not excel at specific tasks due to lack of domain knowledge.
What are the main contributions of this paper?
- MACT (Multi-Agent Collaboration with Tool use), a novel framework for complex TableQA that requires neither closed-source models nor fine-tuning
- an efficiency optimization module that allows MACT to take shortcuts during reasoning
How does the MACT framework work?
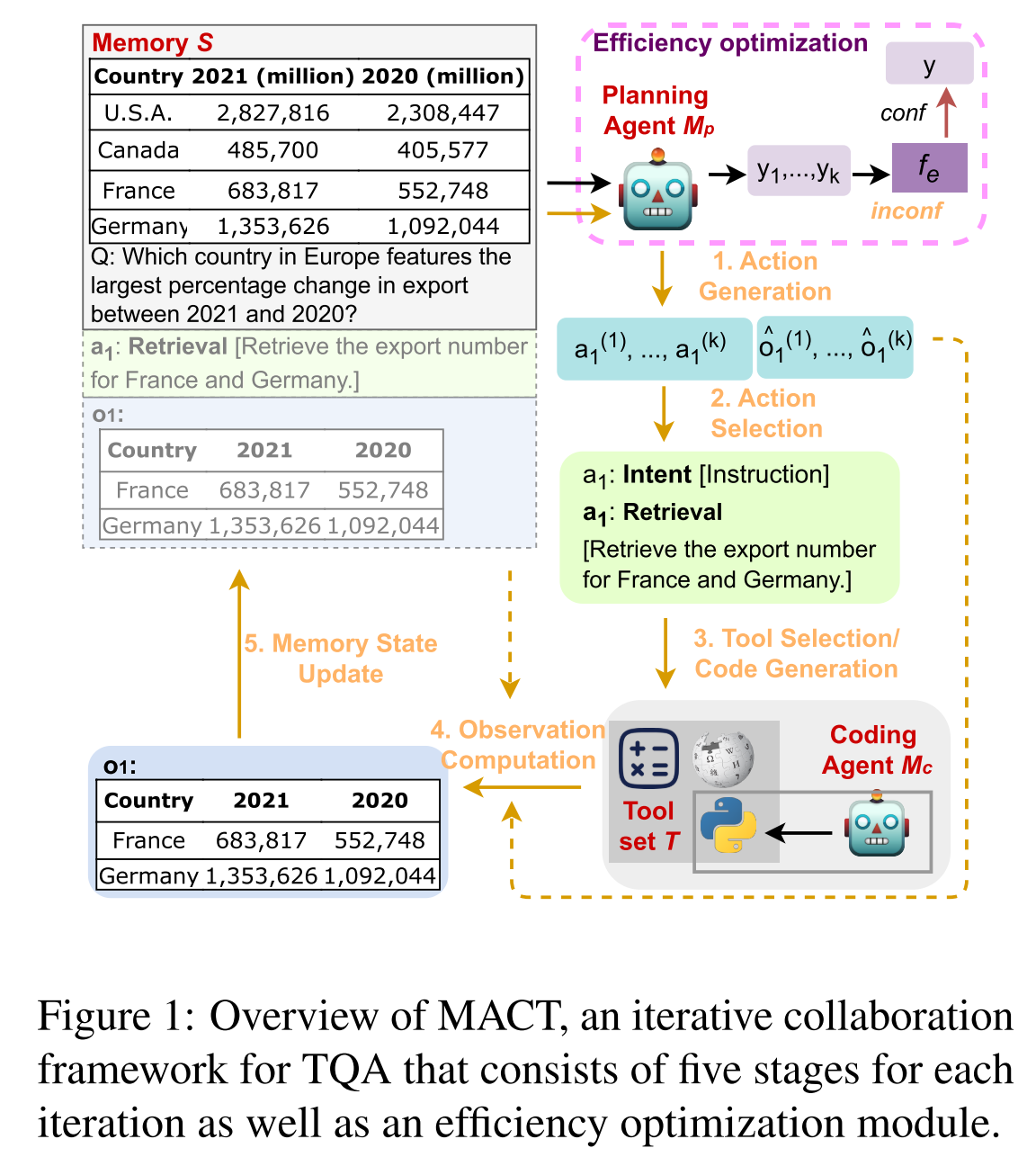
In short: Given a table, a question, and optionally some textual context as the input, a planning agent performs online planning (i.e. generates a plan iteratively), breaking down the complex problem and addressing multi-step reasoning, while the coding agent and the tool set assist with generating faithful intermediate results. This process is iterated for specific times to yield the final answer.
Components:
- a memory
- a planning agent
- a coding agent
- a tool set
Initialization
Initialize the memory state
1. Action Generation
At each iteration
Intent: purpose of an action

6 types of intents:
- Retrieval: any operations extracting information from a table (direct querying, filtering, grouping)
- Calculation: calculation, counting, comparison
- Search: call Wikipedia API on an entity to extract external (factual) knowledge
- Read: retrieve information from the textual context
- Finish: stop
from generating more actions and ends the iteration - Ask: retrieve an answer based on the internal knowledge from the planning agent
Instruction: detailed specifications of the intent
2. Action Selection
From the set of
3. Code Generation and Execution
Given the instructions of the selected action
Sample
Run a Python interpreter on each
4. Observation Computation
If the selected tool is the Wikipedia API or the calculator, then that tool will return a deterministic result.
If the selected tool is the Python interpreter, then select the most frequent element from the joint set of the output of Step 1 (estimated observations of the
5. Memory State Update and Iteration
After obtaining
Then, continue with the next iteration.
Efficiency Optimization
- Motivation: Questions that do not require multi-step or multi-category reasoning can be answered directly by
. - Goal: trade-off between performance and computation time
- For a whole reasoning trace generated by
for a given until the output of the intent Finish, approximate the confidence of by the degree of self-consistency of the estimated predictions , where is the instruction of the action with intent Finish. - “degree of self-consistency” == number of occurrences of the most frequent prediction in
- Introduce a hyperparameter
. - If the degree of self-consistency >
, outputs its most frequent answer. Otherwise, adopt the collaborative framework as usual.
Hyperparameter selection:
- smaller
: more often to use the shortcut - larger
: more confident needs to be in order to take the shortcut
On which TQA datasets is MACT evaluated?

WTQ
- general domain
- no multi-step or multi-category reasoning
TAT
- hybrid data (table + text)
- numerical reasoning
CRT
- Wikipedia tables
- complex reasoning
SCITAB
- claim verification
- converted to TQA format
Which systems (models) are evaluated?
Systems for Comparison
- Systems that require fine-tuning:
- OmniTab (BART)
- TableLlama (Llama-7b)
- ProTrix (Llama-7b)
- TAT-LLM (Llama-7b)
- TableLLM (Llama-7b)
- Systems that do not require fine-tuning:
- Dater (GPT-3.5-turbo)
- Binder (GPT-3.5-turbo)
- Chain-of-Table (GPT-3.5-turbo)
- ReAcTable (GPT-3.5-turbo)
- TabSQLify (GPT-3.5-turbo)
- Plan-then-Reason (GPT-3.5-turbo)
- Mix-SC (GPT-3.5-turbo)
- ARC (GPT-3.5-turbo)
Systems for MACT
- Qwen-72B (planning agent, quantized to int4)
- CodeLlama-34B (coding agent, full precision)
- GPT-3.5-turbo (planning agent + coding agent)
Hyperparameters
= 0.6 = 0.6 = 5 = 7 = 1
What are the results and conclusions?
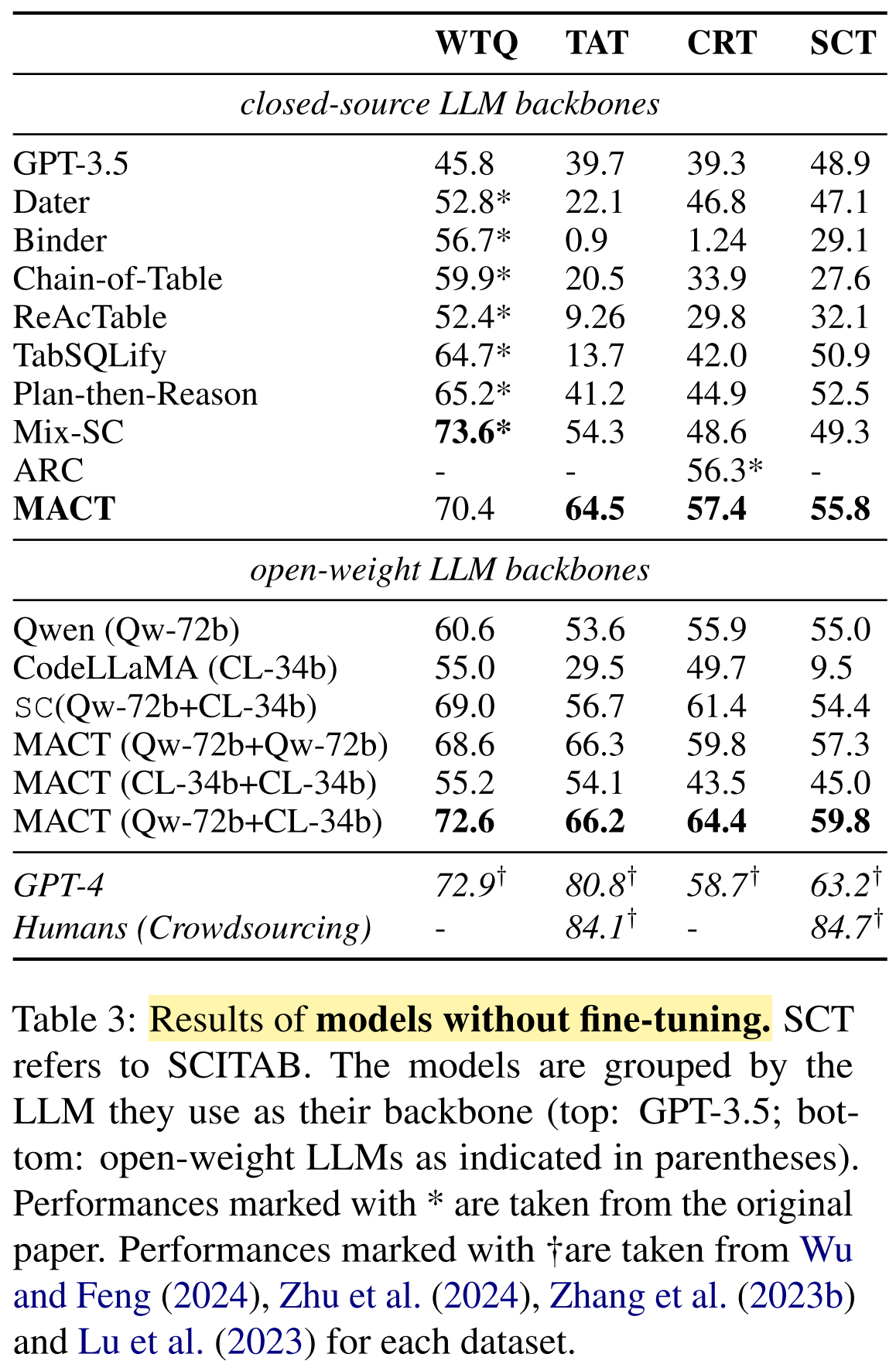
- MACT (GPT-3.5-turbo) outperforms TQA models on TAT, CRT, and SCT.
- MACT outperforms out-of-the-box open-weight LLMs on all datasets.
- MACT with open-source models delivers comparable performance as closed-source systems.
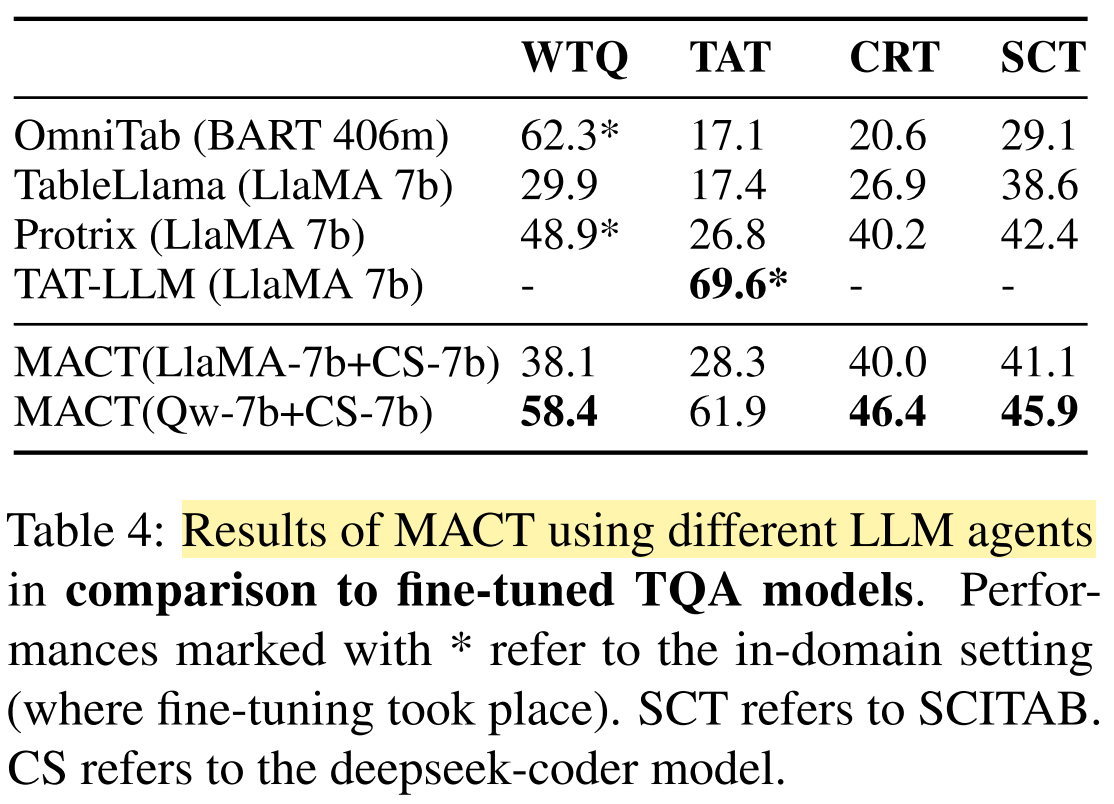
- MACT generalizes better across datasets than fine-tuned TQA systems.
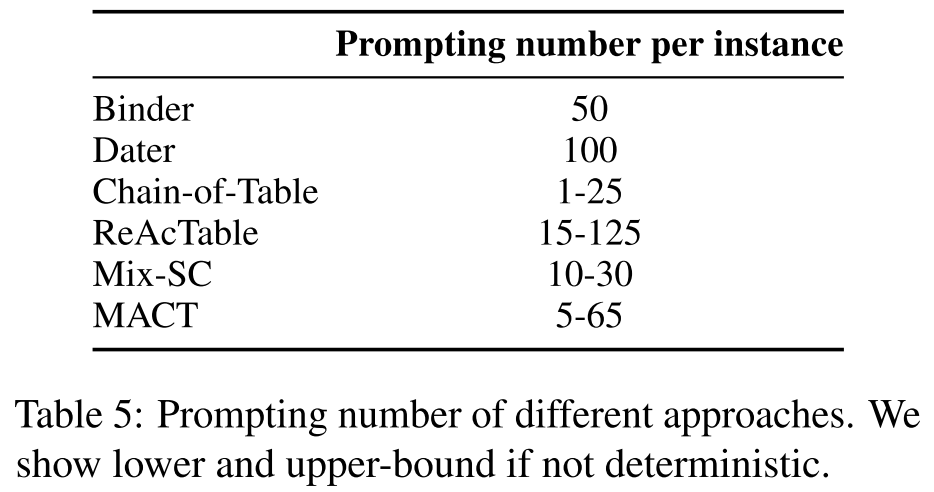
- MACT is moderately efficient.
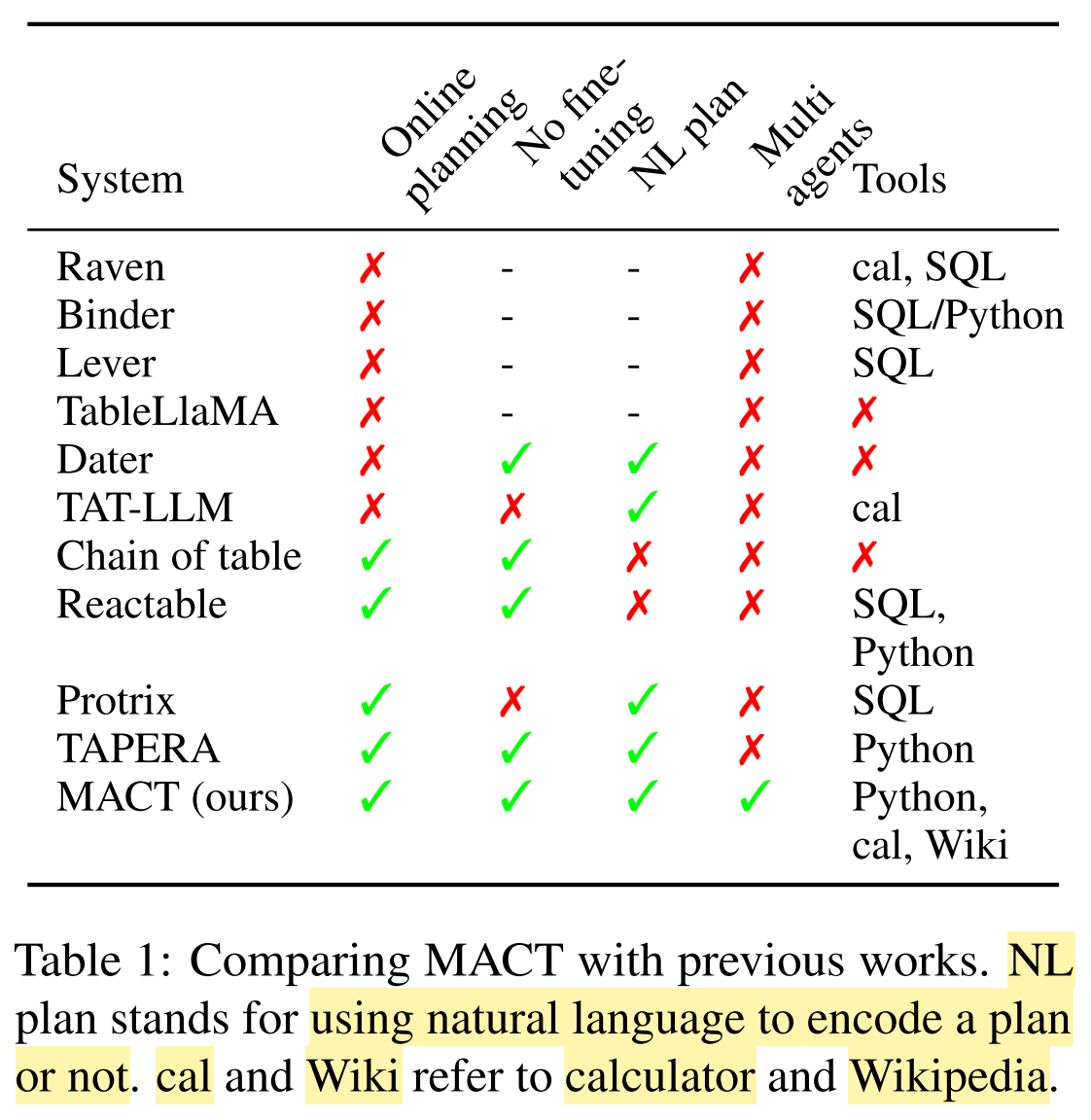
What are the differences of MACT compared to previous methods?
- Title: MACT: Efficient Multi-Agent Collaboration with Tool Use for Online Planning in Complex Table Question Answering
- Author: Der Steppenwolf
- Created at : 2025-01-13 10:18:59
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/01/13/MACT/
- License: This work is licensed under CC BY-NC-SA 4.0.