Generating Fluent Fact-Checking Explanations with Unsupervised Post-Editing
Jolly, Shailza, Pepa Atanasova, and Isabelle Augenstein. “Generating fluent fact checking explanations with unsupervised post-editing.” Information 13.10 (2022): 500.
What problem does this paper address?
Generating more readable, fluent explanations for fact-check veracity labels from ruling comments (RCs), and create a coherent story, while also preserving the information important for fact-checking.
Criteria:
- readable and fluent explanation generation
- story-telling
- preserving important information
What are ruling comments (RCs)?
In-depth explanations for predicted veracity labels given by human fact-checkers.
What is post-editing?
Edit the explanation after it has been completely generated.
What is the motivation of this paper?
Why is there a need for accurate, scalable, and explainable automatic fact-checking systems?
- Manual verification of the veracity label is time-consuming and labor-intensive, making the process expensive and less scalable.
What is the limitation of the veracity prediction mechanism of current automatic fact-checking systems?
- They are based on evidence documents or a long list of supporting ruling comments, which are challenging to read and less useful as explanations for human readers.
What is the limitation of using extractive summarization to generate explanations?
- Such methods cherry-pick sentences from different parts of a long RC, resulting in disjoint and non-fluent explanations.
What is the limitation of generating explanations using sequence-to-sequence models trained on parallel data?
- expensive since it requires large amount of data and computational resources
What is the limitation of using single short sentences and word-level / word-phrase-level edits? Why phrase-level?
- limited applicability for longer text inputs with multiple sentences
Research Questions:
- How to find the best post-edited explanation?
What are the main contributions of this paper?
- an iterative phrase-level edit-based algorithm for unsupervised post-editing
- combination of the algorithm with grammatical corrections and pharaphrasing-based post-processing for fluent explanation generation
How does the iterative edit-based algorithm work?
Select sentences from RCs as extractive explanations: (supervised vs. unsupervised)
Supervised Selection:
- Models: DistilBERT, SciBERT
- Train a multi-task model to jointly predict the veracity explanation and the veracity label, using the
greedily selected sentences from each claim’s RCs achieving the highest ROUGE-2 F1 score to the gold justification, where is the average number of sentences in the gold justifications.
Unsupervised Selection:
- Model: Longformer
- Train a model to predict the veracity of a claim, and select
sentences with the highest saliency scores.
Post-editing the extracted explanations: (completely unsupervised)
- Input: an source explanation
consisting of multiple sentences - Step 1: Candidate Explanation Generation
- Parse
into a constituency tree using CoreNLP’s syntactic parser. - Randomly pick one operation from {insertion, deletion, reordering}.
- Randomly pick a phrase from the constituency tree.
- Perform phrase-level edit:
- Insertion: Insert a <MASK> token before the selected phrase and predict a candidate word using RoBERTa.
- Deletion: Delete the selected phrase from the input explanation.
- Reorder: Take the selected phrase as the reorder phrase. Randonly select
phrases as anchor phrases. Reorder each anchor phrase with a reorder phrase, resulting in candidate sequences. Select the most fluent candidate based on a fluency score (See Step 2).
- Output: a candidate explanation sequence
- Parse
- Step 2: Candidate Explanation Evaluation
- Evaluate the fluency preservation and semantic preservation of
using three scoring functions. - Input: a candidate explanation sequence
- Fluency preservation evaluation:
- Model: GPT-2
- fluency score:

- Semantic preservation evaluation:
- Model: RoBERTa, SBERT
- word-level semantic similarity score:
- explanation-level semantic similarity score:
- overall semantic score:
, : hyperparameter weights
- Length control:
- length score:
- encourages generating shorter explanation sentences
- reject sentences with less than 40 tokens to control over-shortening
- length score:
- Meaning preservation evaluation:
- named entity (NE) score:
- insight: NEs hold the key information within a sentence
- identify NEs using Spacy entity tagger
- count the number of NEs in a given explanation
- named entity (NE) score:
- Overall scoring:
, , : hyperparameter weights
- Evaluate the fluency preservation and semantic preservation of
- Step 3: Final Explanation Selection
- Iterative Edit-Based Algorithm:
- Given the input explanation
, iteratively perform edit operations for steps to search for the candidate with the highest overall score , i.e. . - At each search step, compute the overall score for the previous sequence
and the candidate sequence . - Select a candidate sequence if its score is larger than the previous one by a multiplicative factor
, i.e. - The threshold value
controls the exploration of selecting operations vs. the overall score of the selected candidates stemming from the particular operation. - higher
selecting candidates with higher overall scores, but - higher
none or only a few operations of specific type being selected - Thus, tune
on the validation set of LIAR-PLUS and pick the one that result in selecting candidates with high scores, while also leading to a similar number of selected candidates per operation type. - Output: the best candidate explanation
- Given the input explanation
- Iterative Edit-Based Algorithm:
- Step 4: Grammar Check and Paraphrasing
- Grammatical Correction:
- Input: the best candidate explanation
- Detect grammatical errors in
using a language toolkit. - Remove sentences without verbs.
- Output: a corrected version of the explanation
- Input: the best candidate explanation
- Paraphrasing:
- Input: the corrected version of the explanation
- Model: Pegasus (pre-training objective: abstractive text summarization)
- Use Pegasus to summarize the input semantics in a concise and more readable way.
- Output: fluent, coherent, and non-redundant explanations
- Input: the corrected version of the explanation
- Grammatical Correction:
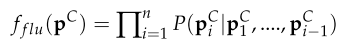
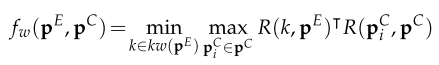
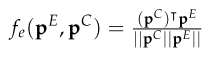
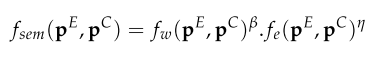
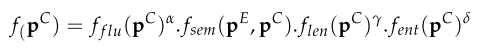
On which datasets is the proposed approach evaluated?
- LIAR-PLUS
- train/val/test: 10,146/1278/1255
- domain: politic
- labels: {true, false, half-true, barely-true, mostly-true, pants-on-fire}
- 2 fact-checking data sources
- PubHealth
- train/val/test: 9817/1227/1235
- domain: health
- labels: {true, false, mixture, unproven}
- 8 fact-checking data sources
Which models are used in the experiments?
- Unsupervised/Supervised Top-N: extract sentences from RCs as explanations
- Unsupervised/Supervised Top-N + Edits-N: generate explanations with the proposed algorithm and grammar correction
- Unsupervised/Supervised Top-N + Edits-N + Para: paraphrase the explanations generated by the second model
- Atanasova et al. [20]: reference model, extractive
- Kotonya and Toni [7]: baseline model, extractive
- Lead-K: lower-bound baseline, pick the first K sentences from RCs
What are the results and conclusions?


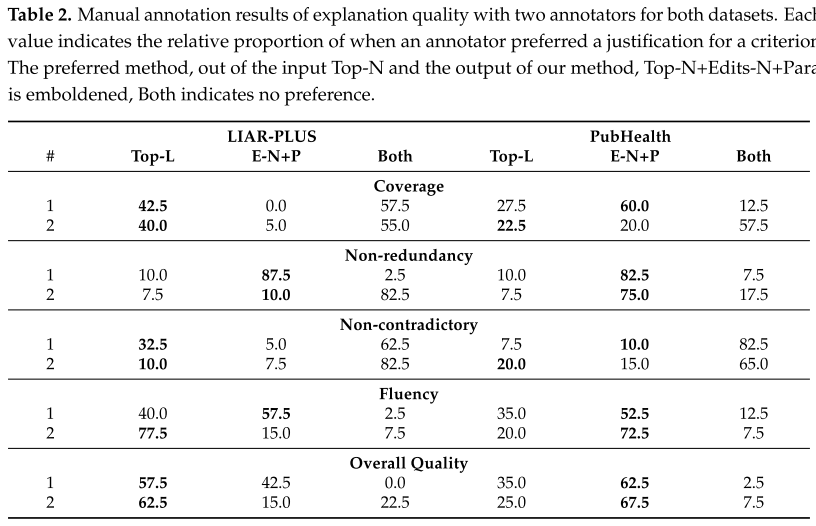
Conclusion: In both the manual and automatic evaluation on two fact-checking benchmarks, the proposed method generates fluent, coherent, and semantically preserved explanations.
- Title: Generating Fluent Fact-Checking Explanations with Unsupervised Post-Editing
- Author: Der Steppenwolf
- Created at : 2025-01-10 09:59:37
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/01/10/Generating-Fluent-Fact-Checking-Explanations-with-Unsupervised-Post-Editing/
- License: This work is licensed under CC BY-NC-SA 4.0.