Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Lewis, Patrick, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler et al. “Retrieval-augmented generation for knowledge-intensive nlp tasks.” Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
What problem does this paper address?
Combining parametric and non-parametric memory for knowledge-intensive tasks.
What is the motivation of this paper?
- Pre-trained LMs
- have limited ability to access and precisely manipulate knowledge
- cannot update the knowledge stored in their memory
- cannot provide insight into their predictions
hallucination
- Hybrid models with a differentiable access mechanism
- have been only investigated for open-domain extractive QA
Research Questions:
- How can non-parametric memory be integrated into pre-trained language models that possess parametric memory?
- Which approach is better: conditioning all tokens in the generated sequence on the same retrieved passage (“per-output basis”) or conditioning each token on different retrieved passages (“per-token basis”)?
What are knowledge-intensive tasks?
Tasks that human could not reasonably be expected to perform without access to an external knowledge base (KB).
What are the main contributions of this paper?
- This paper proposes Retrieval-Augmented Generation (RAG), a new general-purpose fine-tuning approach.
- This new approach combines the model’s parametric knowledge obtained during pre-training with non-parametric knowledge stored in an external KB.
- This paper proposes an end-to-end training paradigm for RAG.
- This paper evaluates RAG on generative knowledge-intensive tasks.
How does RAG work?
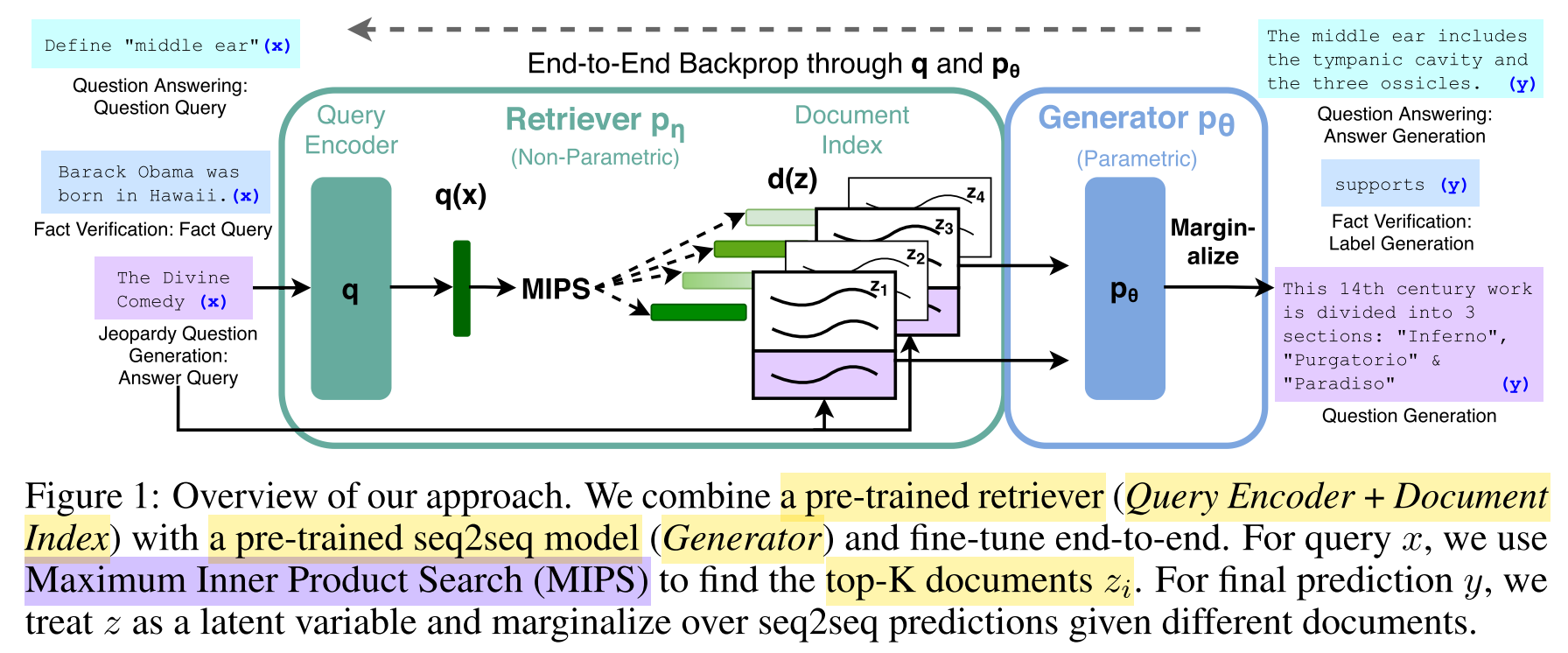
Given a natural language query
RAG-Sequence model vs. RAG-Token model
The generation process can rely on two different types of models: RAG-Token and RAG-Sequence.
RAG-Token:
- a standard auto-regressive sequence-to-sequence generator
- generates each target token in the output conditioned on a different latent document
- generator iteratively produces a distribution for the next output token for each document
- decoding using a single beam search
- advantage: incorporate the information from multiple documents to compose the answer
RAG-Sequence:
- generates the complete output sequence conditioned on a single document
- generator produces the output sequence probability for each document via beam search and yield a score for each hypothesis
- some of the hypotheses may not appeared in the beams of all documents
- Thorough Decoding:
- run an additional forward pass for each document for which the hypothesis does not appear in the beam,
- compute
, and - sum up the probabilities across beams
- suitable for shorter output
- Fast Decoding:
- assume
if was not generated during beam search - avoid the need to run additional forward passes once the candidate set of hypotheses has been generated
- suitable for longer output
- assume
How is the retriever
- a Dense Passage Retriever (DPR) with a bi-encoder architecture
- a query encoder
and a frozen document encoder , both implemented with BERT takes the query as input and produces a query representation takes a document as input and produces a dense document representation - use Maximum Inner Product Search (MIPS) to retrieve the top-k document indices mostly similar to the query
- document index == non-parametric memory
- DPR is pre-trained to retrieve documents on TriviaQA and Natural Questions datasets
How is the generator
- encoder-decoder architecture
- implemented with BART
- parameters
of BART == parametric memory
How are the retriever and generator trained?
- Jointly train the retriever and generator in an unsupervised manner.
- training data: (
, ), : query, : ground-truth response - training objective: minimizing the negative marginal log-likelihood of each target:
- stochastic gradient descent with Adam optimizer
- Freeze the document encoder, only fine-tune the query encoder and the generator.
On which tasks and datasets is RAG evaluated?
Task 1: Open-domain Question Answering
- Input: a question
- Output: a generated text span that should exactly match a text span in the document
- Task type: open-domain generative question answering
- Datasets:
- Natural Questions (NQ)
- TriviaQA (TQA)
- WebQuestions (WQ)
- CuratedTrec (CT)
- Evaluation metric: exact match
- Baselines:
- an extractive QA paradigm using REALM and DPR
- text spans extracted from retrieved documents as answer
- rely primarily on non-parametric knowledge
- a Closed-Book QA approach using T5
- no retrieval
- rely purely on parametric knowledge
- an extractive QA paradigm using REALM and DPR
Task 2: Abstractive Question Answering
- Input: a question
- Output: a generated text that should meaningfully answer the question
- Task type: free-form, open-domain abstractive text generation
- Dataset: MSMARCO NLG Task v2.1
- Evaluation metrics: Rouge-L, BLEU-1
- Baseline: BART
Task 3: Jeopardy Question Generation
- Input: a factual statement about an entity as the answer
- Output: a non-trivial question to that answer
- Task type: open-domain question generation
- Dataset: SearchQA
- Evaluation metrics:
- Q-BLEU-1
- human evaluation:
- factuality: whether a statement can be corroborated by trusted external sources
- specificity: mutual dependence between the input and output
- Baseline: BART
Task 4: Fact Verification
- Input: a natural language claim + a Wikipedia dump as KB
- Output: a label from {supports, refutes, unverifiable}
- Task type: multi-class classification (2-way & 3-way)
- Dataset: FEVER
- Evaluation metric: label accuracy
- Baseline: BART
What are the results and conclusions?
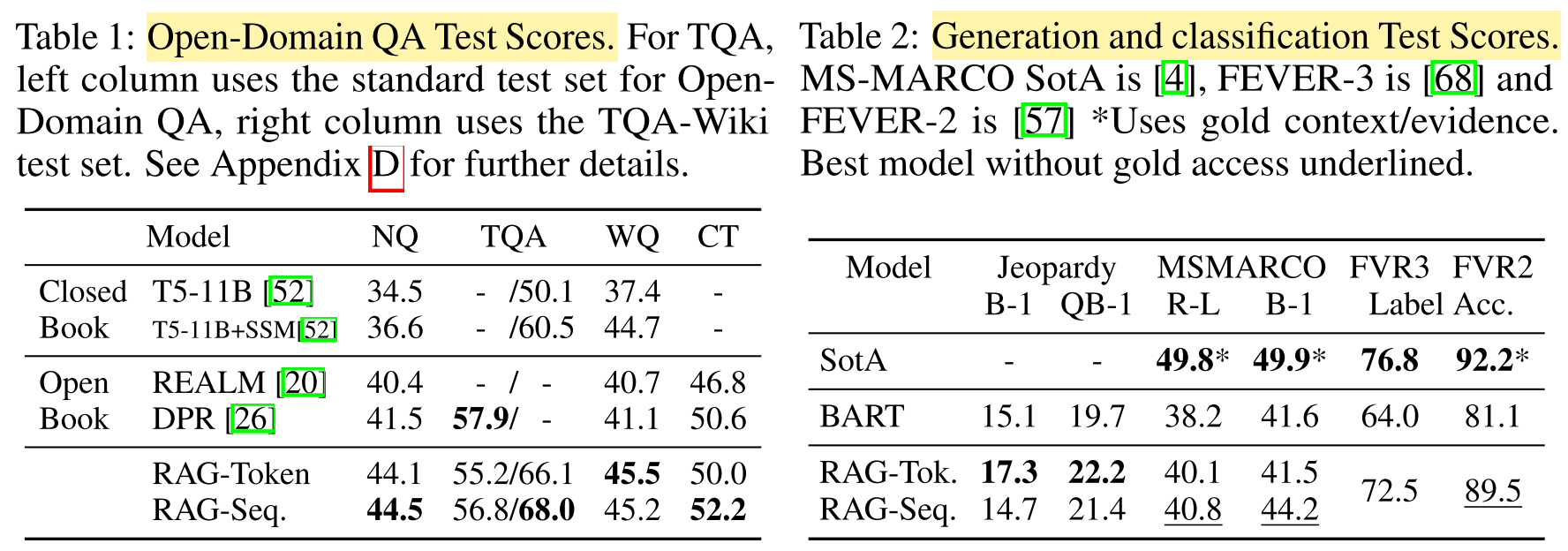
Task 1: Open-domain Question Answering
- Result: RAG achieves SOTA on all four datasets.
- Conclusion:
- RAG combines the generation flexibility of the “closed-book” (parametric only) approaches and the performance of “open-book” retrieval-based approaches.
- Unlike REALM and T5+SSM, RAG enjoys strong results without expensive, specialized “salient span masking” pre-training.
- Neither a re-ranker nor extractive reader is necessary for SOTA performance.
- Advantages of generative QA over extractive QA:
- Documents with clues about the answer but do not contain the answer verbatim can still contribute towards a correct answer being generated, leading to more effective marginalization over documents.
- RAG can generate correct answers even when they are not in any retrieved document.
Task 2: Abstractive Question Answering
- Result: Palm (SOTA) > RAG > BART
- Conclusions:
- Models adopting RAG hallucinate less and generate factually correct text more often than BART.
- RAG generations are more diverse.
Task 3: Jeopardy Question Generation
- Result: RAG-Token > RAG-Sequence > BART
- Conclusions:
- RAG generations are more factual most of the time.
- RAG generations are more specific by a large margin.
- The non-parametric memory helps to guide the generation, drawing out specific knowledge stored in the parametric memory.
Task 4:
- Result: SemGraph (FEVER3) / EWC (FEVER2) > RAG > BART
- Conclusion: RAG is competent in classification tasks.
What are the main advantages and limitations of this paper?
Advantages:
- RAG combines the flexibility of parametric memory and the performance of non-parametric memory.
- No pre-training necessary to obtain ability to retrieve non-parametric knowledge.
Limitations:
- DPR was trained on Natural Questions and TriviaQA (potential train-test-overlap).
- Chunking is crucial since it could cause information loss and inconsistency. This paper only applies one chunking method. More approaches to do the chunking should be investigated.
- Title: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Author: Der Steppenwolf
- Created at : 2025-01-06 21:35:06
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2025/01/06/RAG-for-Knowledge-Intensive-NLP-Tasks/
- License: This work is licensed under CC BY-NC-SA 4.0.