MultiModalQA: Complex Question Answering over Text, Tables and Images
What problem does this paper address?
Multimodal multi-hop question answering over text, tables and images.
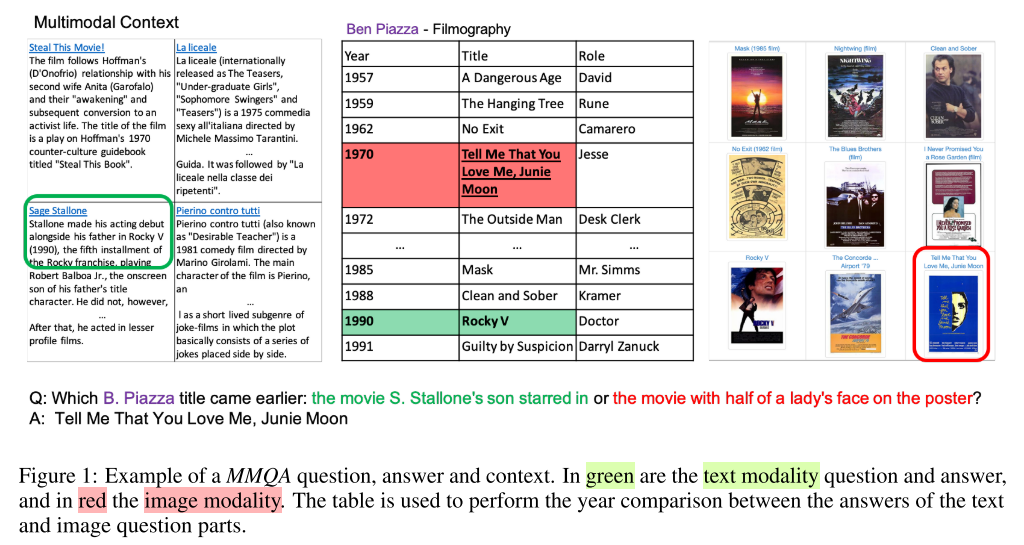
What’s the motivation of this paper?
- Answering complex questions may require integrating information across multiple modalities from the source.
- There exists little work on question answering models that reason across multiple modalities.
- ManyModalQA: question context involve multimodality, but no cross-modality reasoning needed
- HybridQA: tabule and text, but no visual modality


What are the main contributions of this paper?
- MMQA, the first large-scale QA dataset that requires integrating information across unstructured text, semi-structured tables, and images.
- ImplicitDecomp, a multi-hop model that predicts a program specifying the required reasoning steps over different modalities, and executes the program with dedicated text, table, and image models.
- A methodology for generating complex multimodal questions over text, tables and images at scale.
How is the dataset created?
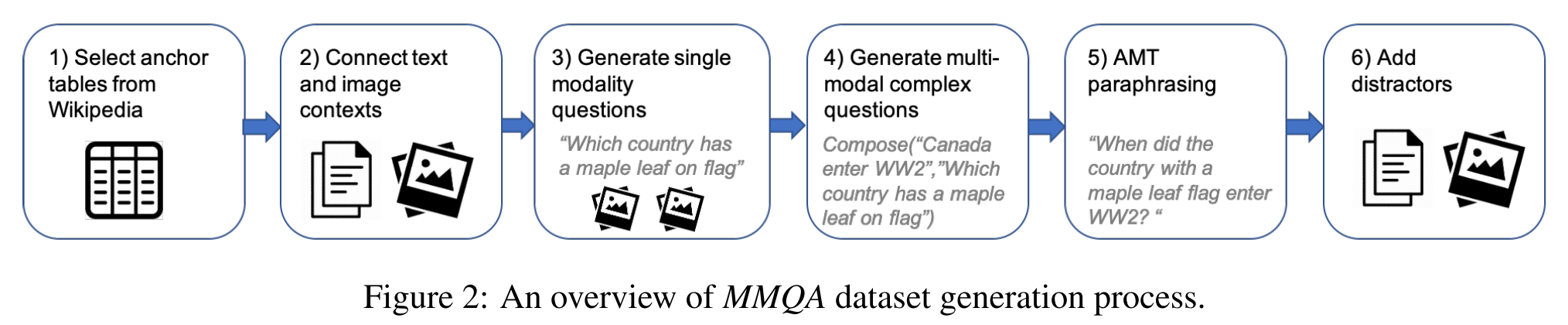
- Context Construction: Harvest tables from Wikipedia and connect each table to images and paragraphs that appear in existing Reading Comprehension datasets.
- Select an anchor table from English Wikipedia that contains 10-25 rows and is associated with at least 3 images.
- Connect text and images to tables:
- Images:
- In-table images: featured inside the table cells
- Table contains a column of WikiEntities that potentially have images: map WikiEntities and their profile images to their Wikipedia pages
- Text:
- build on texts from contexts appearing in reading comprehension datasets
- Images:
- Question Generation: Automatically generate questions that require multiple reasoning operations using the linked structure of the context.
- Generate single-modality questions
- questions over a single image
- questions over a list of images
- Generate multimodal complex compositional questions
- i.e. questions that require answering a sequence of subquestions to conclude the final answer
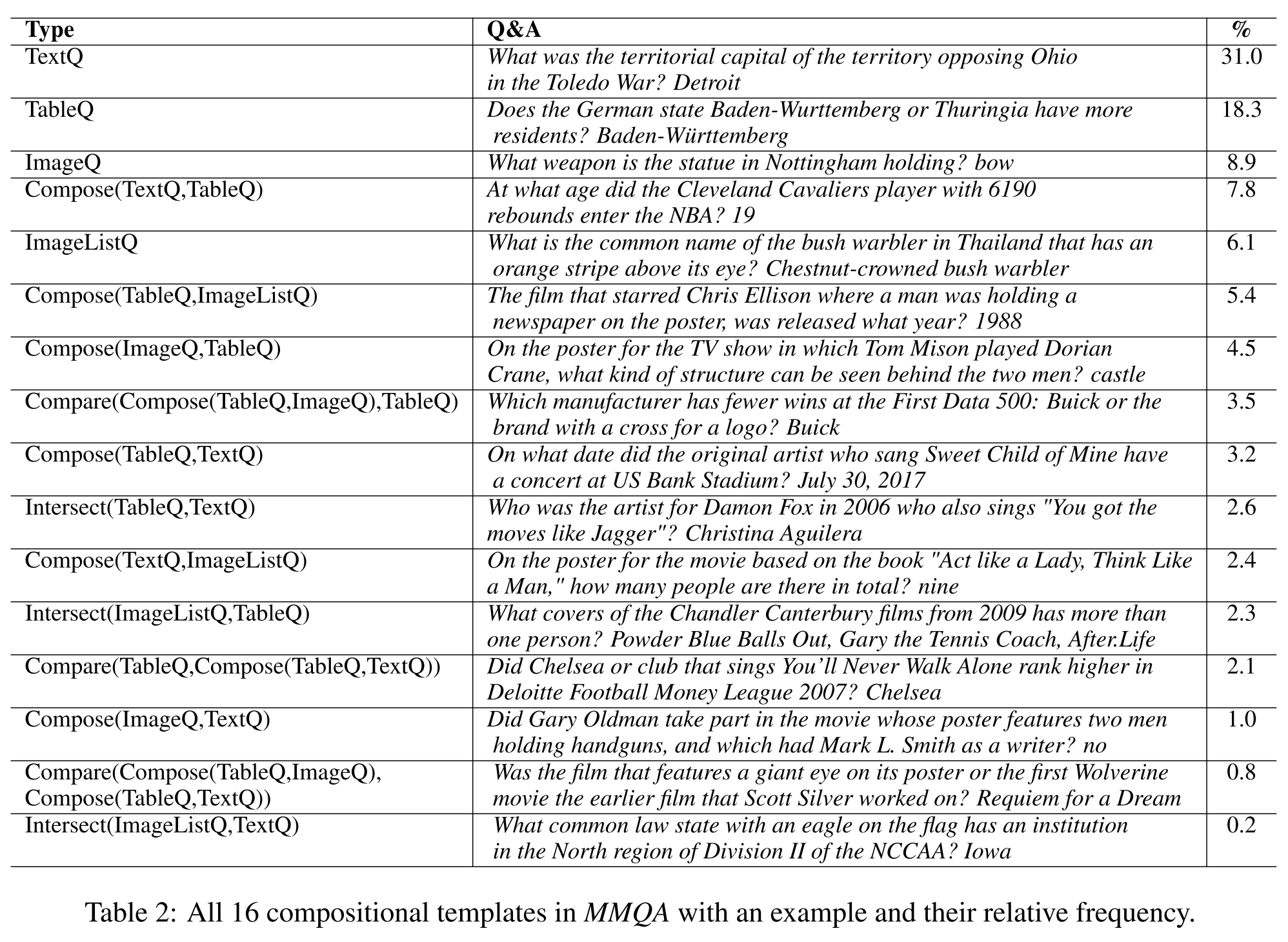
- Logical operations used to generate pseudo-language (PL) questions:
- TableQ
- TextQ
- ImageQ
- ImageListQ
- Compose(
, ) - Intersect(
, ) - Compare(
, )
- Generate single-modality questions
- Paraphrasing: Paraphrase the pseudo-language questions into more fluent English by crowdsourcing workers.
- AMT workers paraphrase automatically generated PL questions into natural language.
- Each PL question is paraphrased by 1 worker and validated by 1-3 other workers.
- To avoid annotator bias, the number of annotators who worked on both the training and evaluation set was kept to a minimum.
- feedback mechanism
- Add Distractors:
- For ImageQ questions (single-image): 15 distractors per question.
- Encode the first 2 paragraphs of each Wikipedia article with an IR model, DPR, and use the paragraphs with the highest dot product to the question as the distractor.
Dataset Statistics:
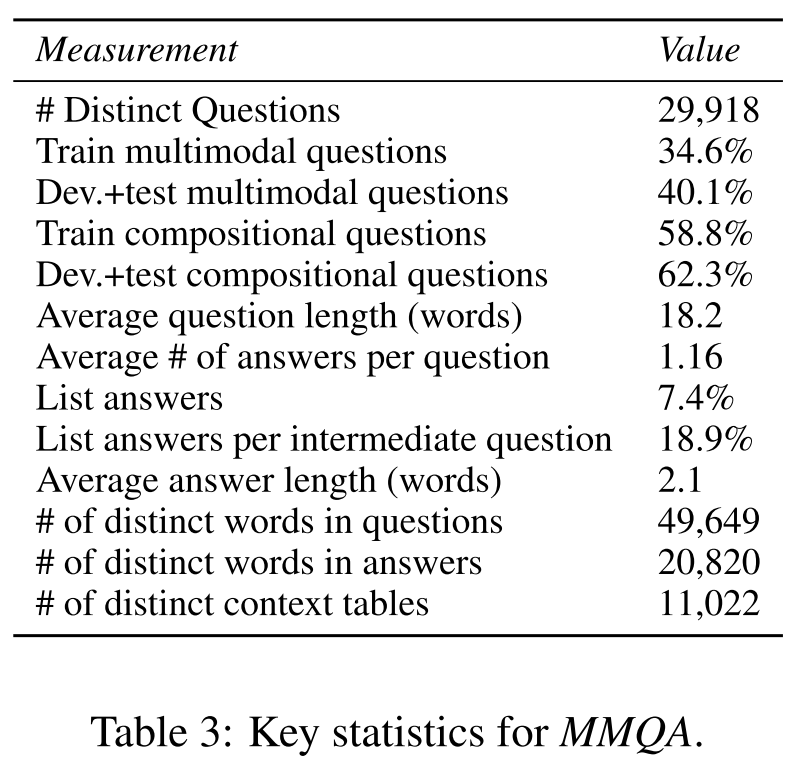
Key statistics:
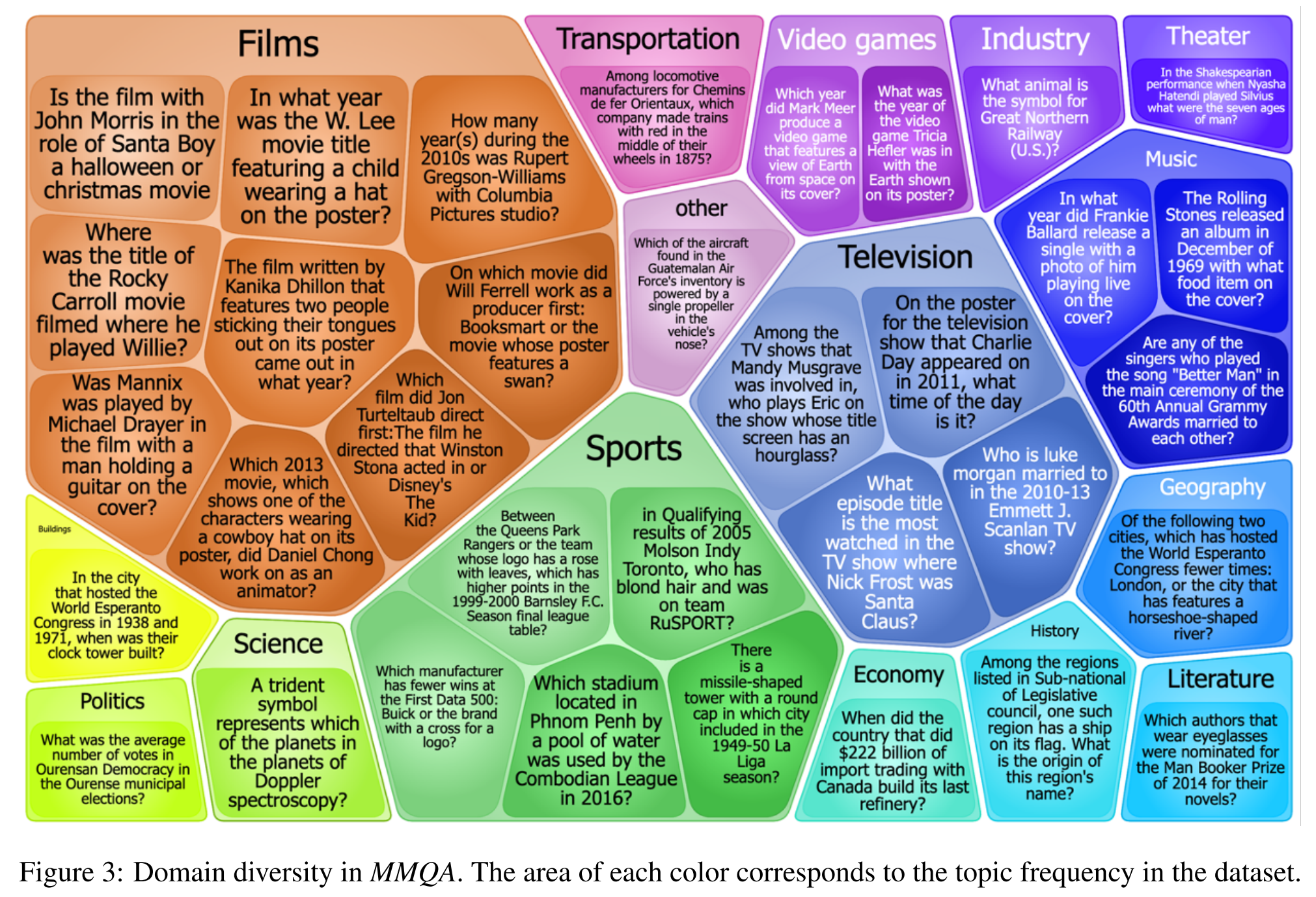
Domain diversity:
Which baseline models are evaluated?
Unimodal QA Modules
Text QA Module:
- Input: a question
+ a paragraph - Output: a score for each of the following claim + the paragraph with the lowest score for claim 4
- the answer is a span in
- the answer is “yes”
- the answer is “no”
- the answer is not in
- the answer is a span in
- Model: RoBERTa-large
- Method: fine-tune
Table QA Module:
- Input: a question
+ a linearized table - Output: an answer extracted from the table cells
- Model: RoBERTa-large
- Method:
- Concatenate
and . - Embed it using RoBERTa-large.
- Compute the probability of each token in the table cell being selected, using a linear classifier.
- Compute the score of each cell being selected as the average of its tokens.
- Select cells with score > 0.5
- Predict an aggregation operation from
, , , , , . - Answer: sum of cell values / mean value of cell values / count of cell values / “yes” / “no” / all selected cells
- Concatenate
Image QA Module:
- Input: a question
+ a set of images + WikiEntities associated with each image - Output: an answer from a fixed vocabulary
- Model: ViLBERT-MT
Multimodal QA Models
Multi-Hop Implicit Decomposition (ImplicitDecomp):
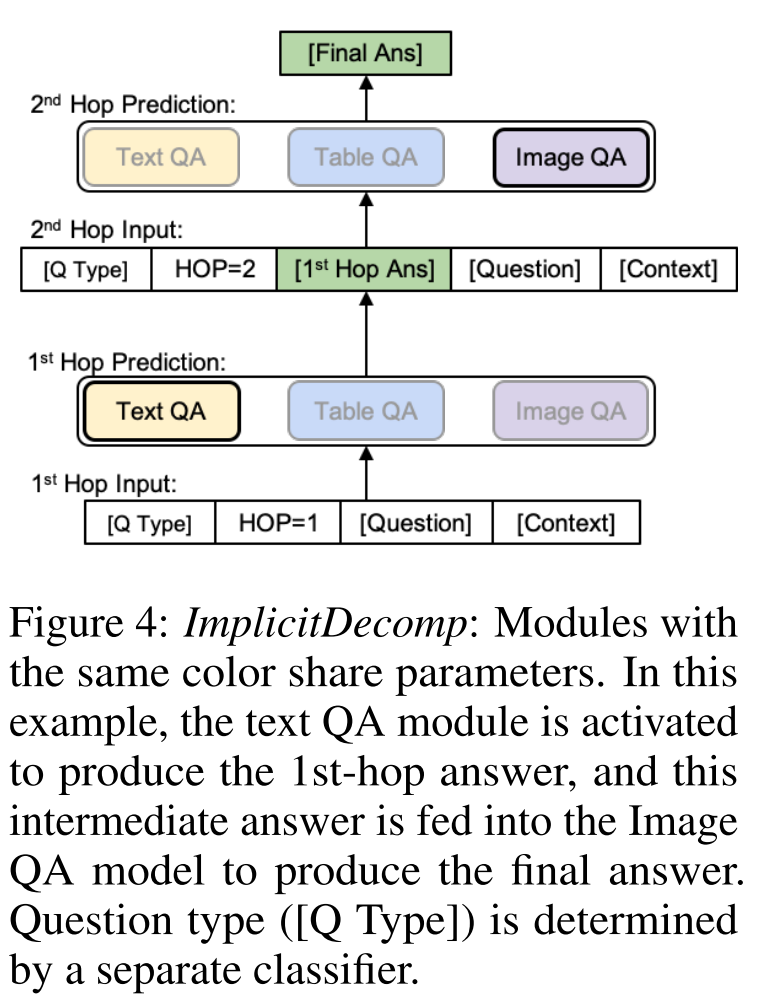
- 2-hop implicit decomposition baseline
- Train a RoBERTa-large model that classifies a question
into one of the 16 possible question types. - The question type can be viewed as a program, specifying the relevant modalities, their order, and the logical operations.
- The model takes the question
, the question type, the hop number, and the context of the corresponding modality as input, and identifies which part of is relevant at the current hop, while avoiding explicitly decompose the question into sub-questions. - Answers from the previous hops are given as input in the subsequent hops to compose the final answer.
Single-Hop Routing (AutoRouting):
- Determine the modality where the answer would appear using the question type classifier.
- Route the question and the context for the predicted modality into the corresponding module.
- Use the output as the final answer.
Question-only Baseline: Directly generate the answer given the question using BART-large.
Context-only Baseline: Predict the question type to select a target module, then feed the relevant context to the target module, replacing the question with an empty string.
How are the models evaluated?
Three settings:
- questions that require a single modality to answer
- questions that require reasoning over multiple modalities
- all questions
What are the evaluation metrics?
- average
- exact match (EM)
What are the results and conclusions?
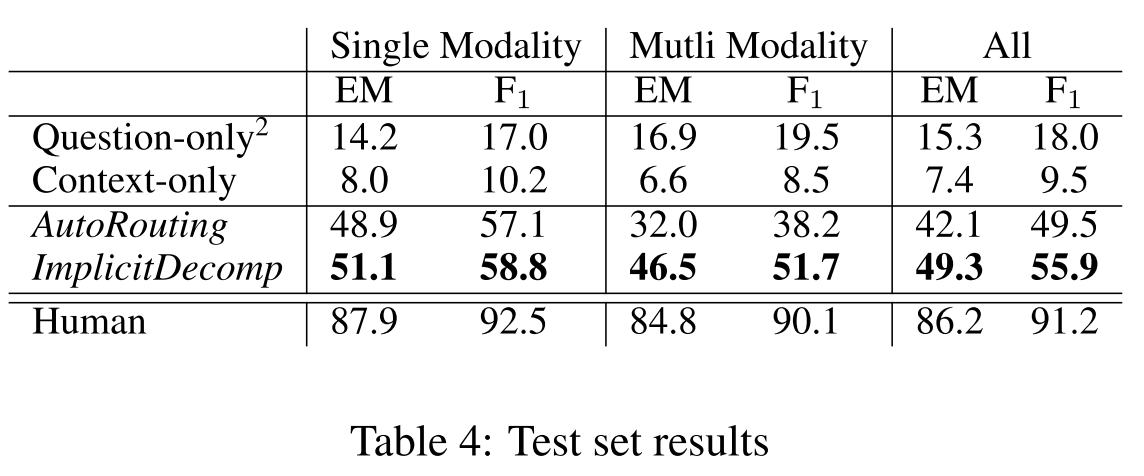
- Result 1: ImplicitComp significantly surpasses other baselines, but underperforms human.
- Result 2: On the Multi Modality subset, ImplicitComp substantially outperforms the single-hop AutoRouting.
- Result 3: 94.5% human answers are identical or semantically equivalent the gold answer.
- Title: MultiModalQA: Complex Question Answering over Text, Tables and Images
- Author: Der Steppenwolf
- Created at : 2024-12-13 13:01:50
- Updated at : 2025-06-22 20:46:51
- Link: https://st143575.github.io/steppenwolf.github.io/2024/12/13/mmqa/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments