VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning
Wu, Xueqing & Ding, Yuheng & Li, Bingxuan & Lu, Pan & Yin, Da & Chang, Kai-Wei & Peng, Nanyun. (2024). VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning. 10.48550/arXiv.2412.02172.
What problems does this paper address?
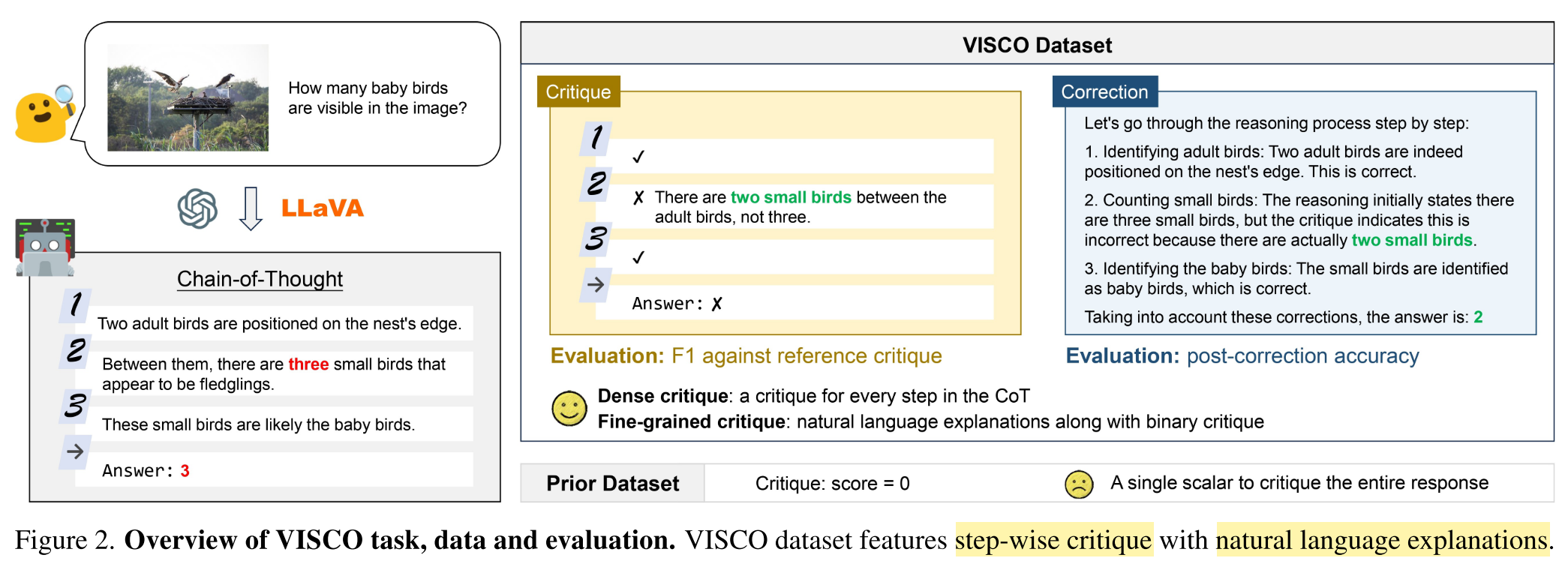
Fine-grained critique and correction of LVLMs for self-improvement in visual perception- and reasoning tasks with Chain-of-Thought (CoT).
What’s the motivation of this paper?
- Even with Chain-of-Thought (CoT), LVLMs remain prone to hallucination and reasoning errors, raising concern about the trustworthiness of LVLMs and highlights the need for more reliable visual reasoning abilities.
- It lacks a systematic analysis of the critique and correction capabilities of LVLMs for self-improvement.
- Existing work typically use a single scalar to critique the entire model response.
What is self-improvement?
LVLMs critique their initial reasoning and make corrections accordingly to enhance performance.
What related work have & have not been done in previous studies?
- The effectiveness of self-improvement has been proved in
- text-only tasks, such as code generation [5, 29] and multi-hop question answering [34].
- vision-language tasks, such as video understanding [30] and region-of-interests identification [45].
- Previous work evaluate the critique capability and enhance it through specialized training strategy, but using LVLMs as evaluators [15] or reward models [42] only to assess the output quality, rather than for further self-correction and self-improvement.
What are the main contributions of this paper?
- This work makes an initial exploration in self-improvement of visual reasoning.
- This paper releases VISCO, the first benchmark for VIsual Self-Critique and cOrrection, to extensively analyze fine-grained critique and correction capabilities of LVLMs.
- This paper conducts extensive evaluation of 24 LVLMs on 18 datasets across 8 tasks, and summarizes 3 failure patterns for the critique task.
- This paper proposes the LookBack strategy to enhance the critique capability of LVLMs and benefit their correction performance.
What is the task?
Given an image
Critique Task
- Input: an image
+ a question - Output: a dense fine-grained critique
: a binary critique for each CoT reasoning step ; : a natural language explanation for ; : a binary critique for .
Data statistics:
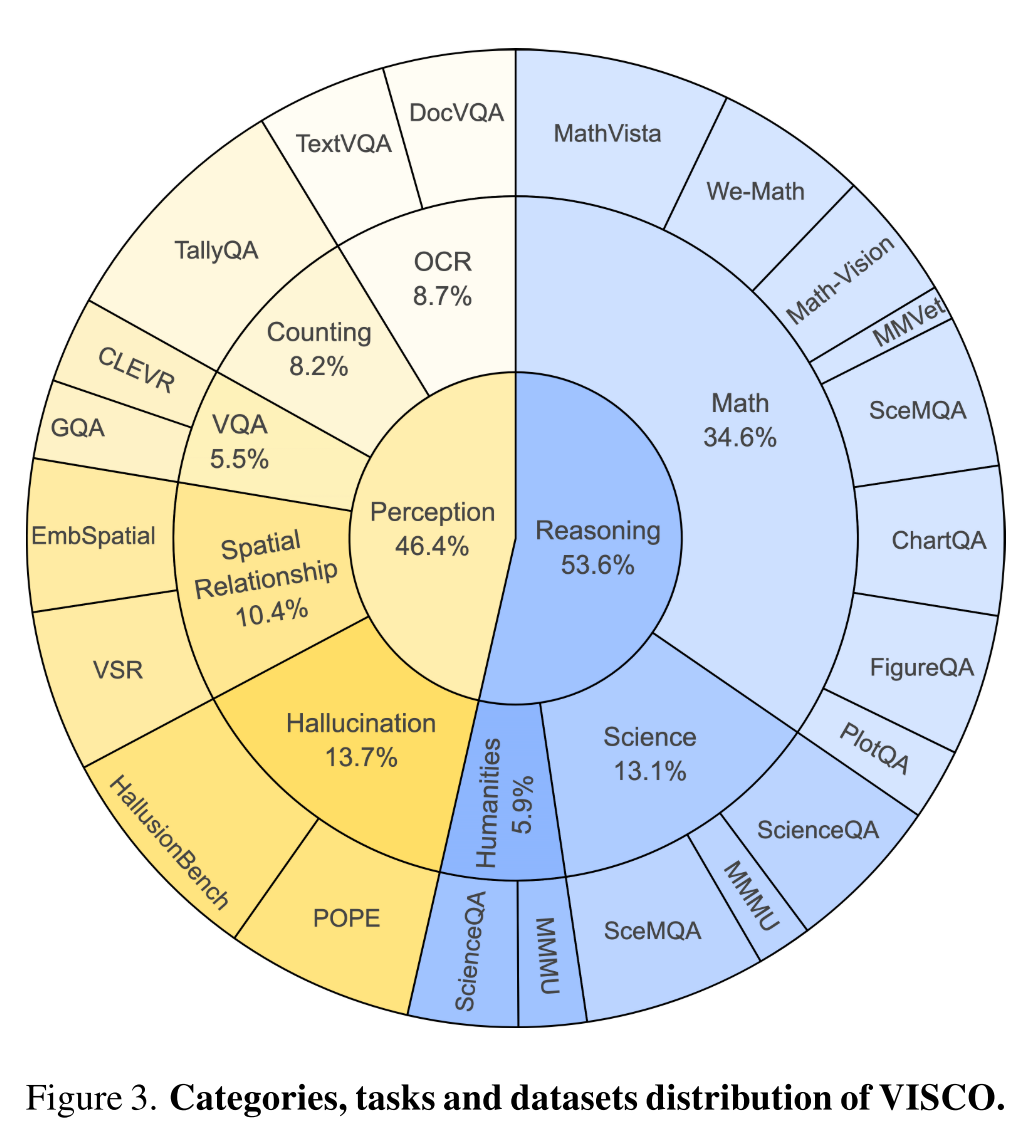
- 1645
-pairs, generated by LVLM, each pair with step-wise binary labels and natural language explanations - 18 datasets across 8 tasks
- two task categories:
- perception tasks, such as reducing hallucinations
- reasoning tasks, such as math reasoning
How is the dataset created?
Which systems and models are employed for the evaluation? What are their key differences?
Which evaluation metrics are used?
What are the results and conclusions of the experiments?
What are the main advantages and limitations of this paper?
Advantages:
Limitations:
What insights does this work provide and how could they benefit the future research?
- Title: VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning
- Author: Der Steppenwolf
- Created at : 2024-12-08 22:25:08
- Updated at : 2025-06-22 20:46:51
- Link: https://st143575.github.io/steppenwolf.github.io/2024/12/08/VISCO/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments