Prompt Tuning for Audio Deepfake Detection
Oiso, H., Matsunaga, Y., Kakizaki, K., Miyagawa, T. (2024) Prompt Tuning for Audio Deepfake Detection: Computationally Efficient Test-time Domain Adaptation with Limited Target Dataset. Proc. Interspeech 2024, 2710-2714, doi: 10.21437/Interspeech.2024-81
What problems does this paper address?
Test-time domain adaptation with a labeled target dataset for audio deepfake detection (ADD).
Input: an audio waveform
Output: a binary label from Y = {Real, Fake}
Model: an ADD model
- pre-trained on a source dataset
with source distribution - maps the input waveform
to a binary label
Assumptions:
- There exists a discrepancy between
and . - The source data
is not accessible at the adaptation stage.
What’s the motivation of this paper?
- Audio deepfake can cause significant harm, e.g., spreading fake news, defaming people’s reputation, and copyright violation.
- ADD systems suffer from three challenges:
- domain gaps in source (training) and target (testing) data
- source of gaps: discrepancy in data generation methods, recording environments, languages
- necessitates effective domain adaptation
- limited target dataset size
- limited accessibility of additional target data
- risk of overfitting
- high computational cost
- foundation models as feature extractors
- domain gaps in source (training) and target (testing) data
Research Questions:
- How to bridge the domain gap between the source and target data?
- How to avoid overfitting on smaller target datasets?
- How to save the computational cost of using foundation models as feature extractors?
What are the main contributions of this paper?
This paper proposes a plug-in-style method based on prompt tuning, which
- is model-agnostic, fine-tuning-method-agnostic, and effectively improve the ADD performance.
- effectively counters overfitting to small target datasets by reducing the number of additional trainable parameters.
- requires minimal extra computational resources.
How does the proposed method work?

In short: Insert the soft prompt to the intermediate feature vectors of the first Transformer layer in the Front-End during both fine-tuning and inference. Either tune the soft prompt only (type A prompt tuning), or the prompt and the last linear layer in the Back-End (type B prompt tuning), or the prompt and all the parameters in Front-End and Back-End (type C prompt tuning). The model is tuned with a class balanced loss to handle the data imbalance in the ADD dataset.
Which pre-trained ADD models are used?
- W2V: Wav2Vec 2.0 + AASIST, SOTA on ASVspoof 2021 LA
- WSP: Whisper + MFCC + MesoNet, SOTA on the In-the-Wild dataset
Which datasets are used?

Source dataset: ASVspoof 2019 LA
Target datasets:
- an existing In-the-Wild dataset
- Hamburg Adult Bilingual LAnguage (HABLA)
- ASVspoof 2021 LA
- Voice Conversion Challenge (VCC) 2020
Target datasets cover 7 target domains (
to ) Domain gaps among the target datasets:
- deepfake generation methods (G)
- recording environments (E)
- languages (L)
Which evaluation metrics are used?
- Equal Error Rate (EER)
What are the baselines?
No baseline.
What are the results or conclusions of the experiments?
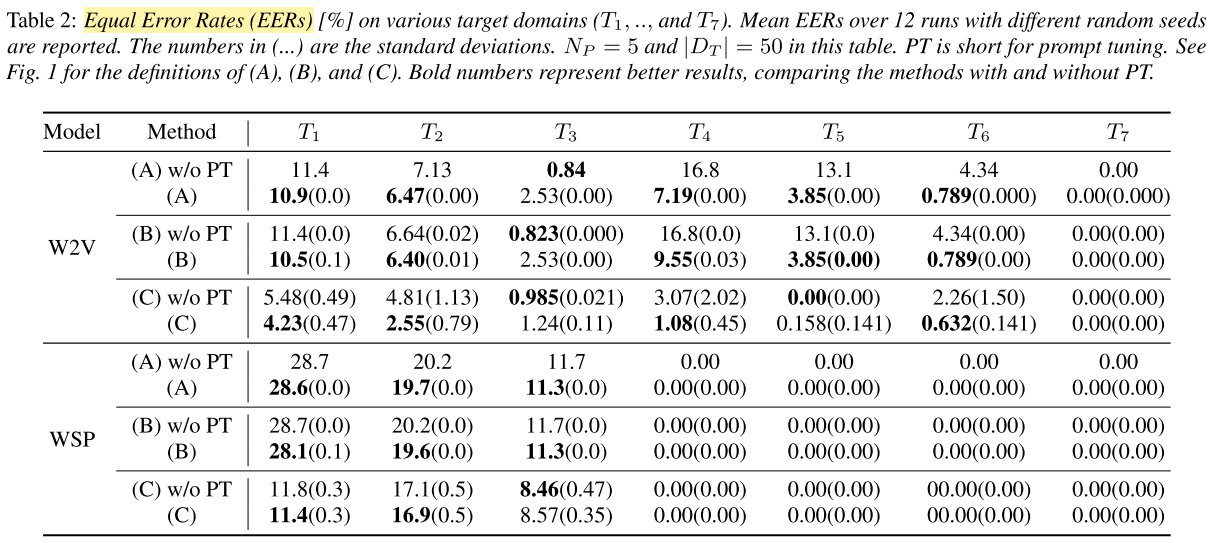
- Result: Prompt tuning improves or maintains the EERs across most target domains.
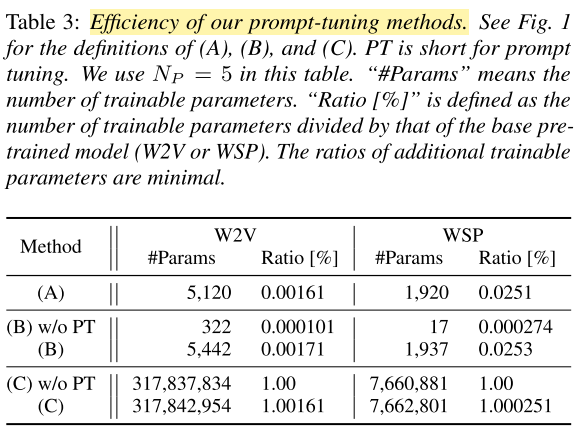
- Result: Prompt tuning of type A and B require only minimal additional trainable parameters.
Conclusion: Prompt tuning is superior to full-parameter fine-tuning (type C) which requires optimizing a huge number of parameters in the foundation model, providing viable alternatives under constrained computational budgets.

Ablation Study: target dataset sizes
Result: Prompt tuning reduces EERs in most scenarios.
Conclusion: The improvement is particularly notable when the target dataset size is limited to 10 samples.
(Does this conclusion match the results in Table 4? Fine-tuning on 1000 samples reduces the EER more significantly than on 10 samples for A and B…)Result: Prompt tuning of type A and B outperforms full-parameter fine-tuning (type C), with and without prompt tuning.
Conclusion: This superiority attributes to the tendency of full fine-tuning to overfit the small target dataset.

Ablation Study: prompt length
- Result: The performance saturates rapidly with the increase of the prompt length
.
Conclusion:
- The prompt length (i.e. number of prompts) should be limited to a small size.
- Prompt tuning requires only minimal additional trainable parameters.
What are the main advantages and limitations of this paper?
Advantages:
- The proposed prompt tuning method addresses the three challenges.
- The method can be combined with any model architecture (plug-in style).
Limitations:
- No comparison with baseline ADD systems.
- Details to the seven target domains are unclear, e.g., which exact target domains are covered.
- According to Table 2, all types of prompt tuning on domain
increases the EER by a large margin. There is neither discussion nor in-depth analyses on this result in the paper. - Ablation studies are conducted only on the In-the-Wild dataset. The results on other datasets are not reported.
What insights does this work provide and how could they benefit the future research?
- Title: Prompt Tuning for Audio Deepfake Detection
- Author: Der Steppenwolf
- Created at : 2024-12-06 10:09:56
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2024/12/06/Prompt-Tuning-for-Audio-Deepfake-Detection/
- License: This work is licensed under CC BY-NC-SA 4.0.