Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. 2024. Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 257–279, Mexico City, Mexico. Association for Computational Linguistics.
What’s the motivation of this paper?
- In real-world scenarios, e.g. creative industries, there is a need to incorporate diverse information from different domains.
- LLMs still encounter challenges in various knowledge-intensive and reasoning-intensive tasks due to factual hallucination and lack of slow-thinking.
- Although CoT prompting and Self-refinement have successfully enhanced the reasoning abilities of LLMs by simulating slow-thinking, factual hallucination remains a challenge for LLMs on knowledge-intensive tasks.
- Standard prompting suffers from missing essential information and factual errors (hallucinations).
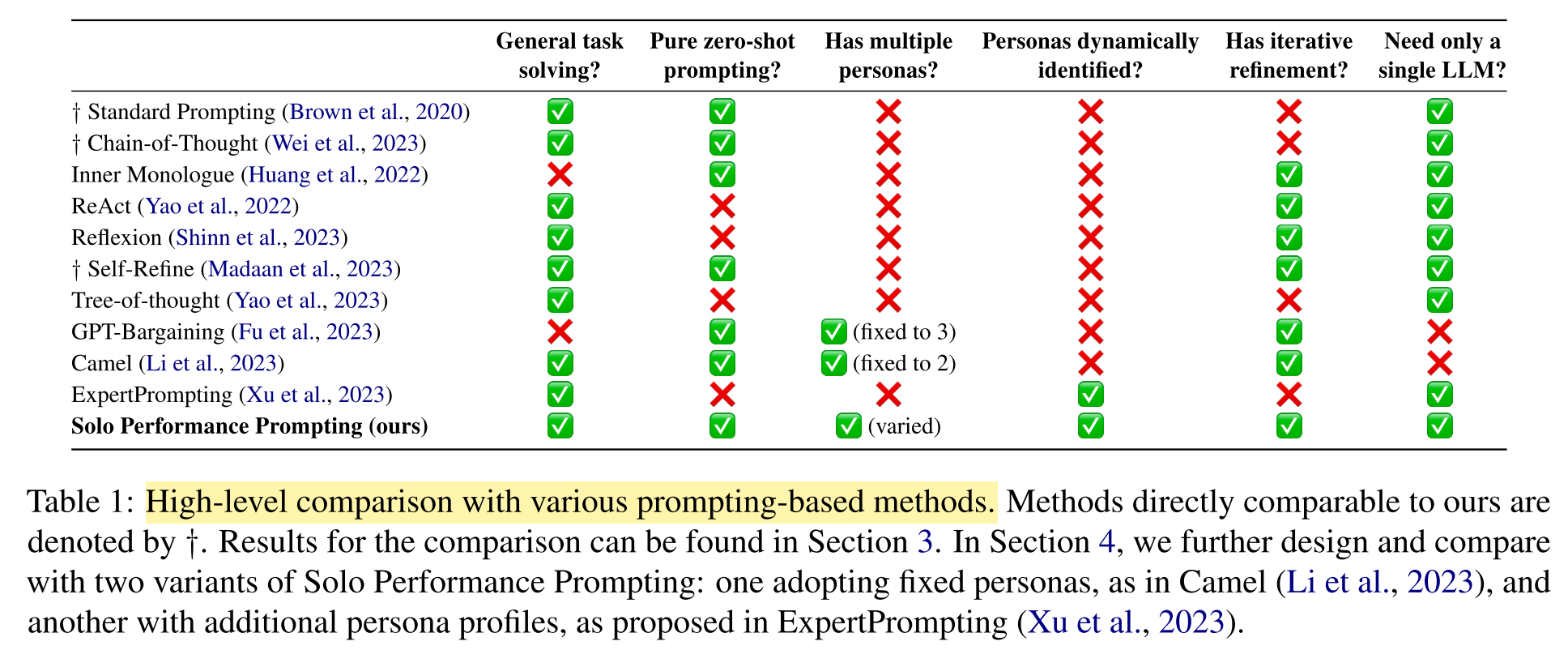
- Previous works on persona-based role-playing are limited by fixed or task-specific personas, the need of additional fine-tuning, and increased inference costs due to the employment of multiple LLM instances.
What problems does this paper address?
Transforming a single LLM into a cognitive synergist to solve complex, knowledge- and reasoning-intensive tasks.
What is cognitive synergy?
- A dynamic in which multiple cognitive processes, coorporating to control the same cognitive system, assist each other in overcoming bottlenecks encountered during their interal processing (Goertzel, 2017).
- The power of collaboration and information integration among different cognitive processes and individuals (defined by this paper).
What is a cognitive synergist?
An intelligent agent that collaborates with multiple minds to enhance problem-solving and efficacy in complex tasks.
Research Questions:
RQ1: Can LLMs leverage cognitive synergy for general task-solving?
RQ2: Why are dynamic, fine-grained personas necessary, as opposed to fixed, coarse-grained personas?
- RQ2.1: Why is dynamic personas better than fixed ones?
- RQ2.2: Why is fine-grained personas better than coarse-grained ones?
What are the main contributions of this paper?
- Solo Performance Prompting (SPP), the first zero-shot prompting method that transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas, thus enhancing both knowledge and reasoning abilities on GPT-4.
- In-depth analyses of the impact of the identified personas and the SPP prompt design.
How does the proposed method (SPP) work?
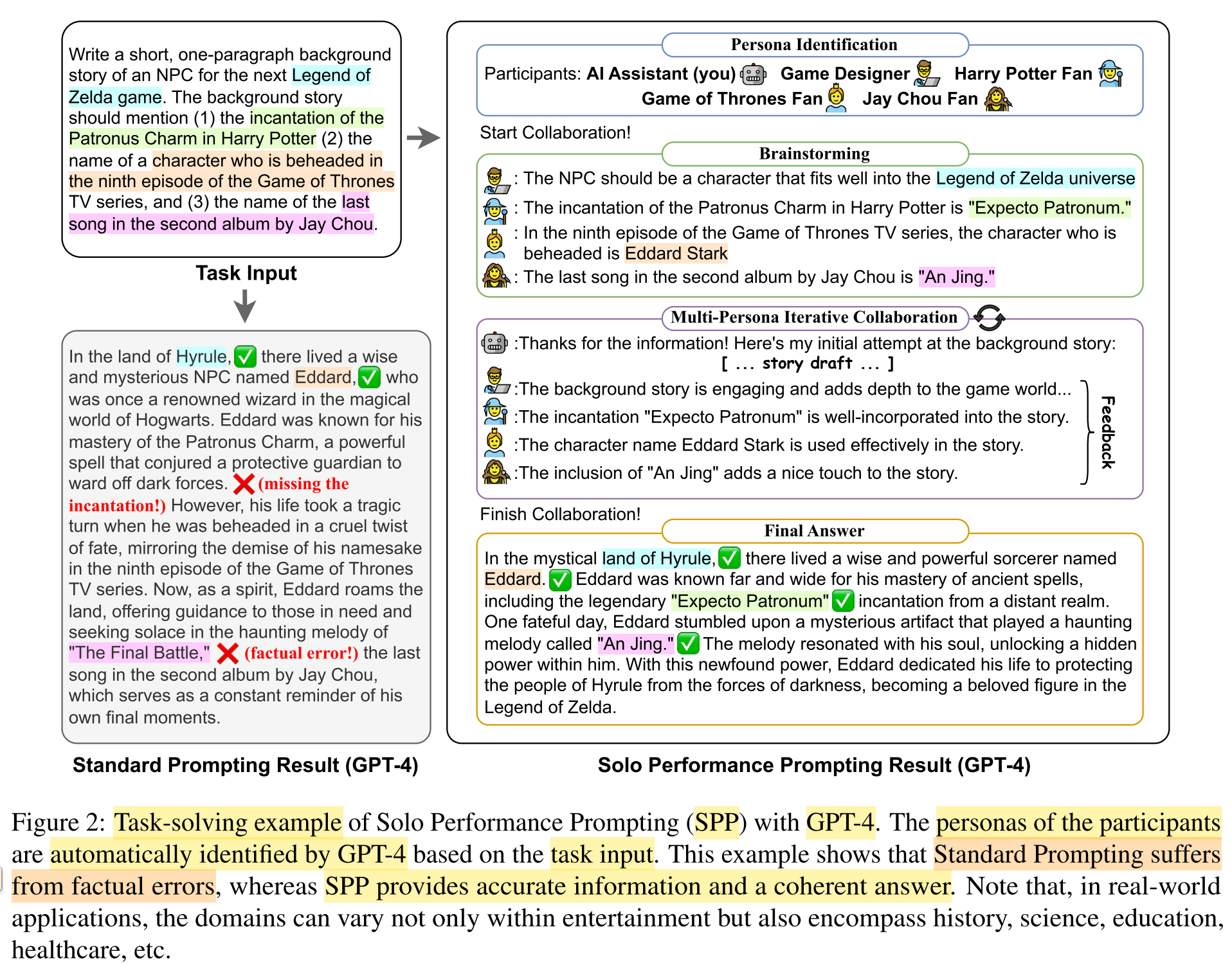
In short: Prompt a single LLM to dynamically simulate multiple personas (e.g., domain expert, target audience etc.), elicit the domain knowledge of each persona, and engage in a multi-turn self-collaboration with self-revision and self-feedback for solving knowledge-intensive and reasoning-intensive tasks.
Persona Identification
- Goal: Identify multiple participants with special personas that are essential for solving the particular task.
- Input: a sequence of text describing the task + two demonstration examples
- Output: a list of participants with different personas, including an AI-assistant and other task-relevant personas.
- Model: GPT-4
- Note: Let the LLM identify the personas dynamically, instead of manually defining them.
Brainstorming
- Goal: Let the participants share knowledge and provide suggestions on how to approach the task based on their own expertise.
- Input: /
- Output: intermediate generations of personas’ brainstorming results on how to approach the task from their own perspectives
Prompt:
Start collaboration!
<persona_1>: <brainstorming results>
<persona_2>: <brainstorming results>
…
<persona_m>: <brainstorming results>
Multi-Persona Iterative Collaboration
- Goal: The leader persona, i.e. the AI Assistant, proposes intitial solutions, consults other participants for feedback, and revise the answer iteratively.
- Input: /
- Output: initial solution + {feedback from other participants + revised solution} × n + final solution
Prompt:
AI Assistant (you): Thanks for the guidance! Here is my initial solution: <initial solution>
<persona_1>: <suggestion>
…
<persona_m>: <suggestion>
AI Assistant (you): Thanks for the hints!/Thanks for pointing out the mistake. Here is a revised solution: <revised solution>
<persona_1>: <suggestion>
…
<persona_m>: <suggestion>
AI Assistant (you): Thanks for the hints!/Thanks for pointing out the mistake. Here is a revised solution: <revised solution>
… (loop until all participants agree with the solution)
<persona_1>: Everything looks good to me.
<persona_2>: Looking good!
…
<persona_m>: I like this version!Finish collaboration!
Final answer: <final solution>
How does SPP differ from previous prompting methods?
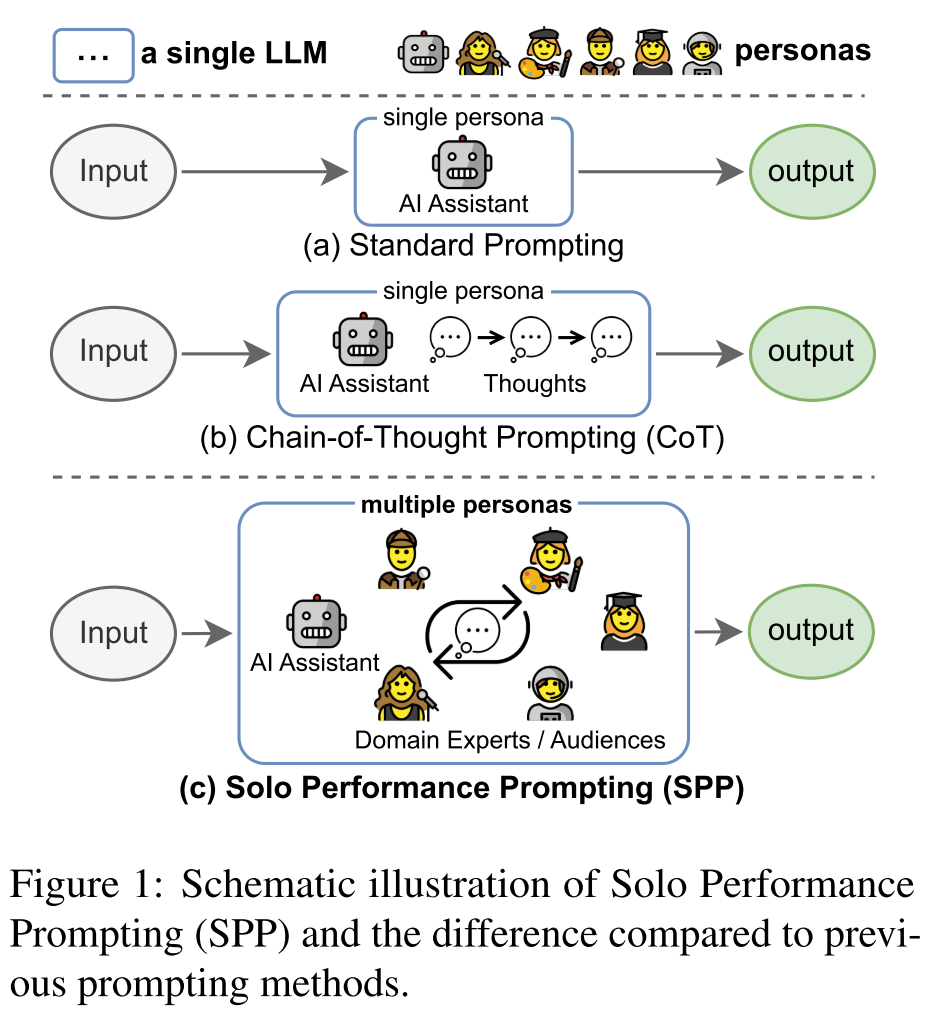
Given an LLM M and an input sequence x specifying the task to be solved,
- Standard Prompting: y = M(x)
- CoT Prompting: y = M(pcot || x || {z1, … , zn})
- pcot: the CoT prompt, e.g., “Solve the task step by step.”
- {z1, … , zn}: the intermediate reasoning steps.
- Solo Performance Prompting (SPP):
y = M(pspp || x || zp || {zb1, … , zbi, … , zbm} || {zs0, zf1, … , zf i, … , zfm}j=1,…,n)- pspp: the SPP prompt, including a high-level instruction describing the SPP mechanism, and two demonstration examples.
- zp: a list of personas identified by the LLM.
- {zb1, … , zbi, … , zbm}: intermediate generation for the brainstorming.
- zs0: initial solution generated by the AI assistant persona.
- zf1, … , zf i, … , zfm: feedback from other participants.
- {zs0, zf1, … , zf i, … , zfm} is iteratively repeated n times until reaching the final answer. Here, j is the index of the iteration.
Which models are evaluated?
- GPT-4
- GPT-3.5-turbo
- Llama2-13b-chat
On which tasks and datasets is the SPP method evaluated? How are they evaluated?
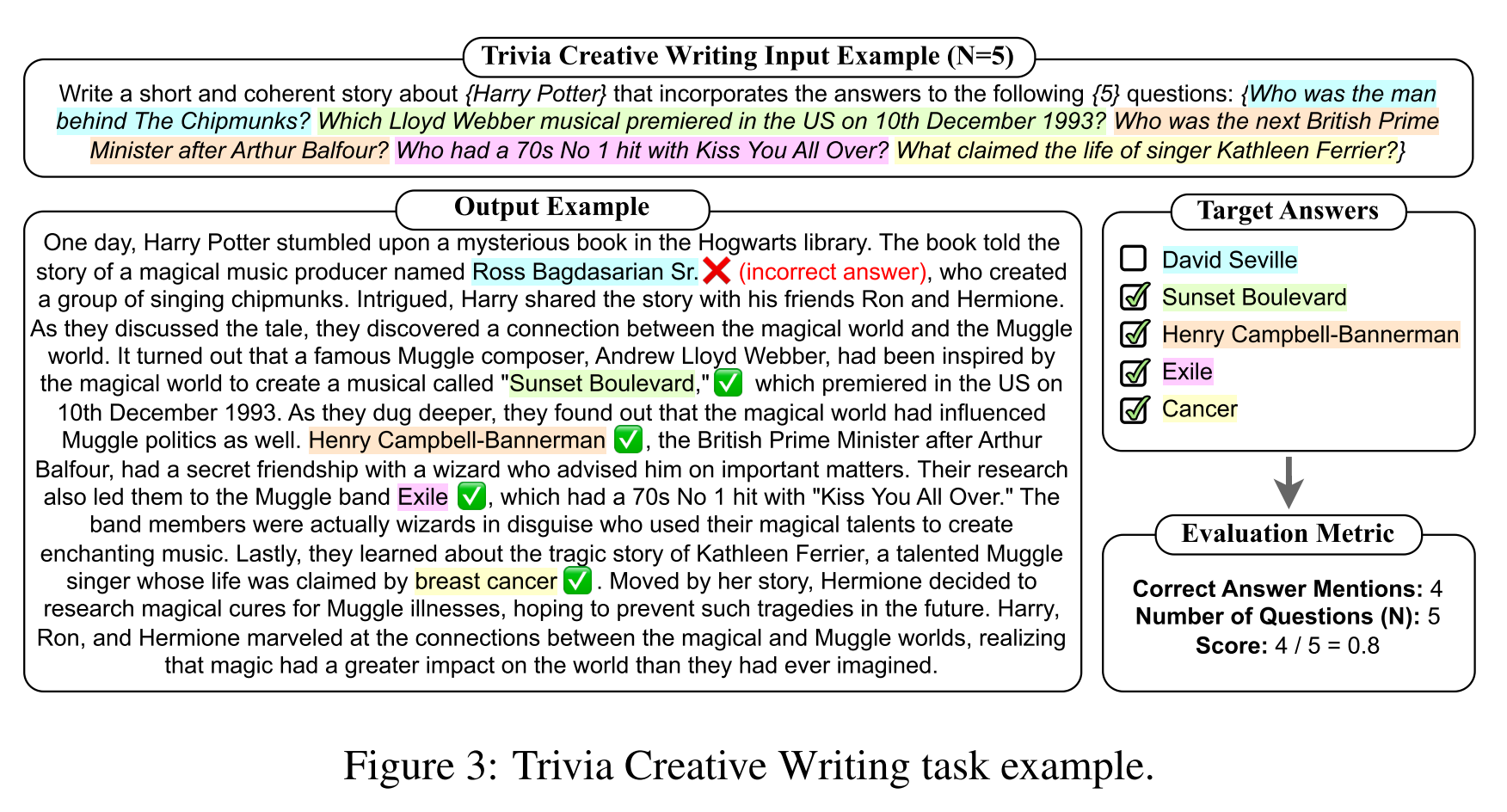
- Trivia Creative Writing (琐事创意写作)
- knowledge-intensive task
- task: write a coherent story while incorporating the answers to N trivia questions
- challenge: requires the model to internally acquire and integrate diverse information from various fields
- preliminary study: a sufficiently large N can effectively challenge GPT-4 to demonstrate factual knowledge across diverse domains (insight)
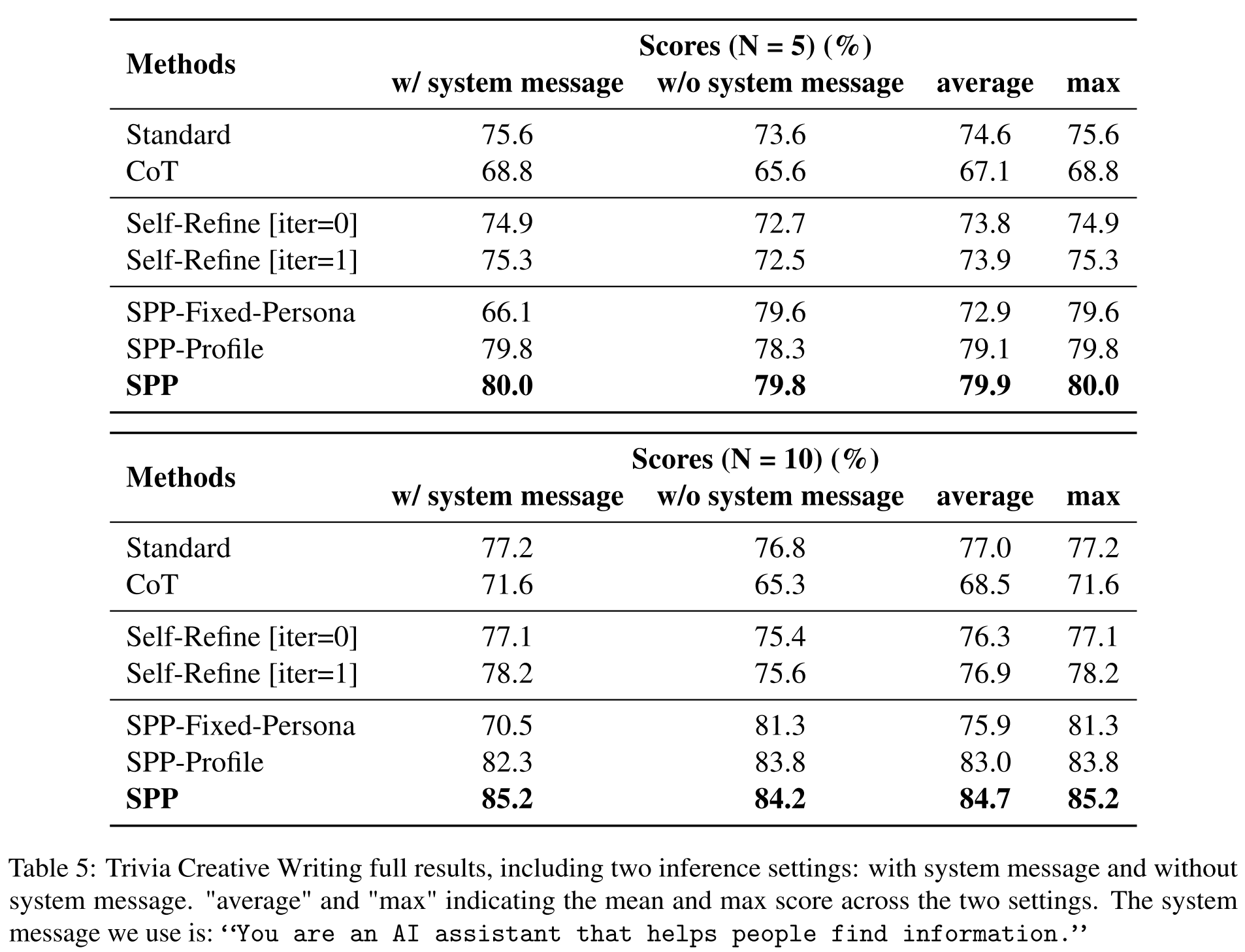
- two evaluation settings: N = 5 and N = 10
- dataset: 100 data instances for each N, covering a total of 1000 questions extracted from TriviaQA
- evaluation metric: factual hallucination score =
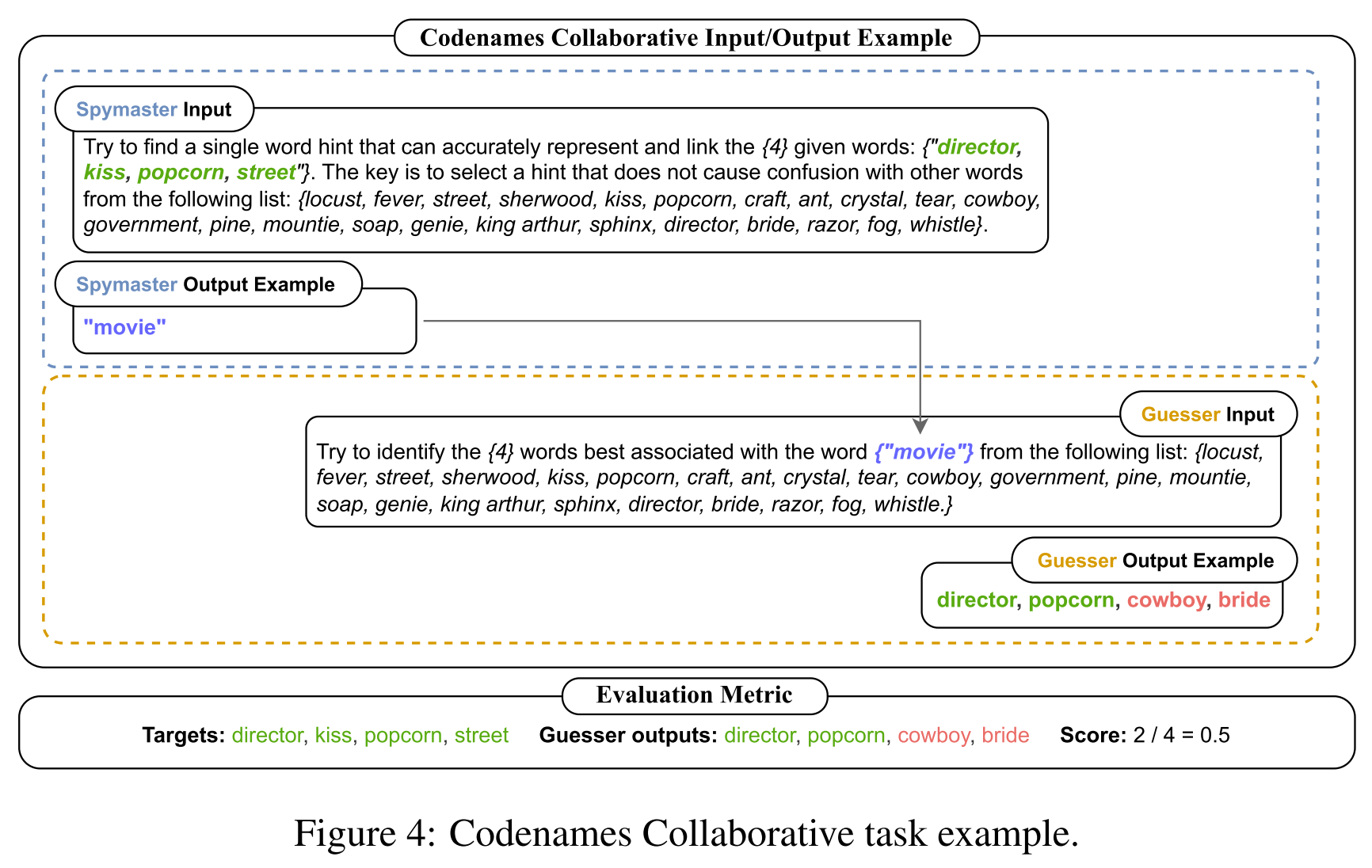
- Codenames Collaborative (机密代号协作)
- knowledge + reasoning + theory of mind
- task: two-role collaboration:
- Spymaster: provides a hint word related to the target words and other distractor words
- Guesser: identifies the target words based on the given hint and the full list of words
- challenge: demands creative reasoning across a broad range of related knowledge and challenges the model’s theory of mind skills
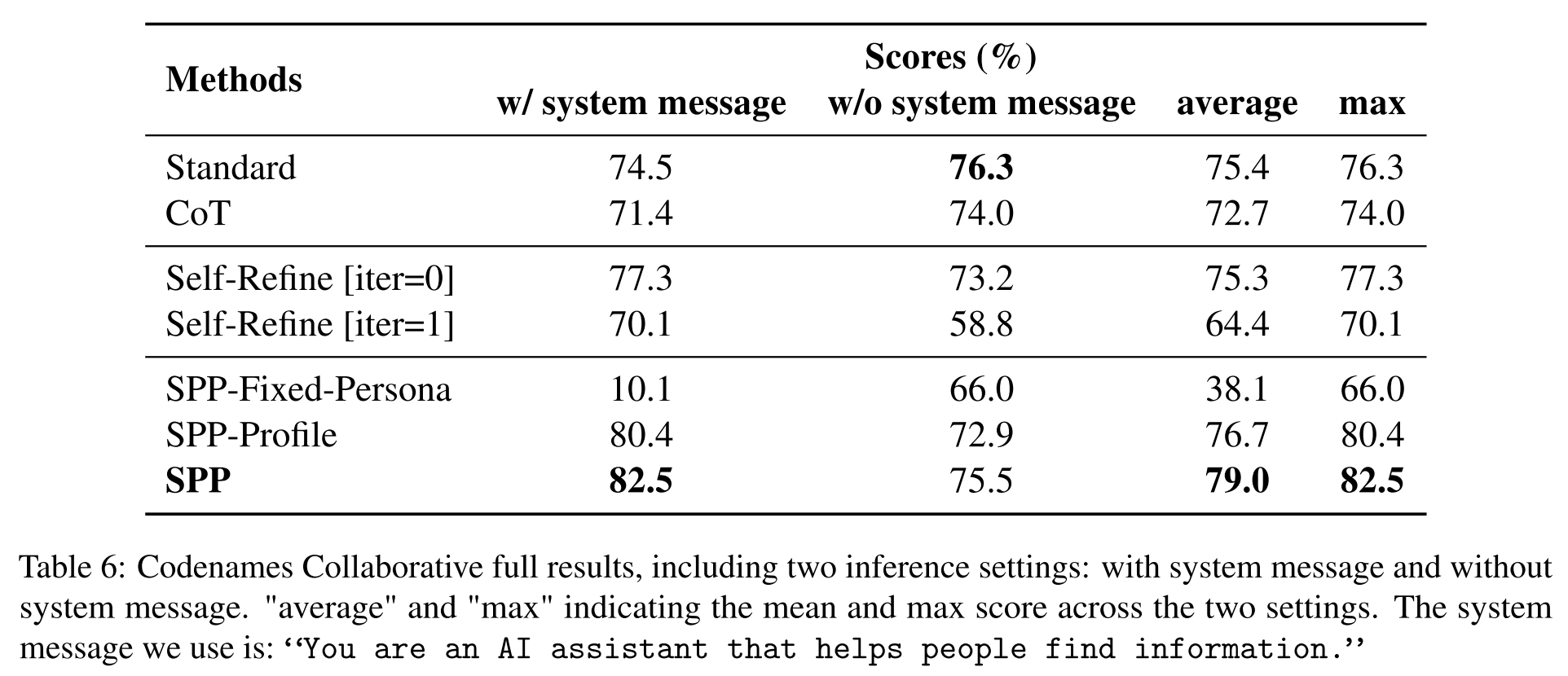
- dataset: 50 data instances constructed based on BigBench’s Codenames task data
- evaluation metric: overlapping ratio between predicted words (Guesser) and target words (Spymaster)
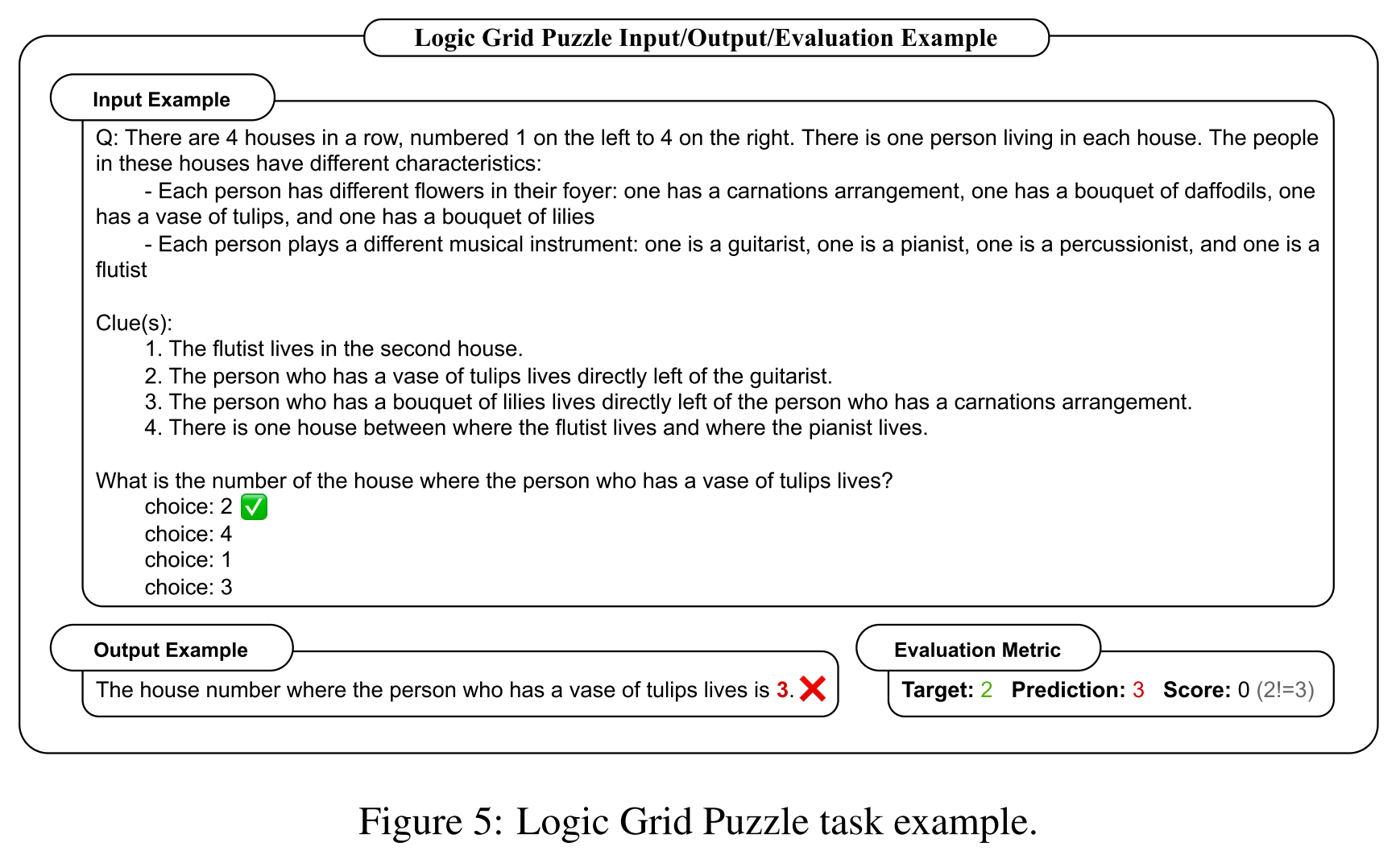
- Logic Grid Puzzle (逻辑网格谜题)
- reasoning-intensive task
- task: answer questions about house numbers based on given clues
- challenge: multi-step reasoning and selection of relevant information
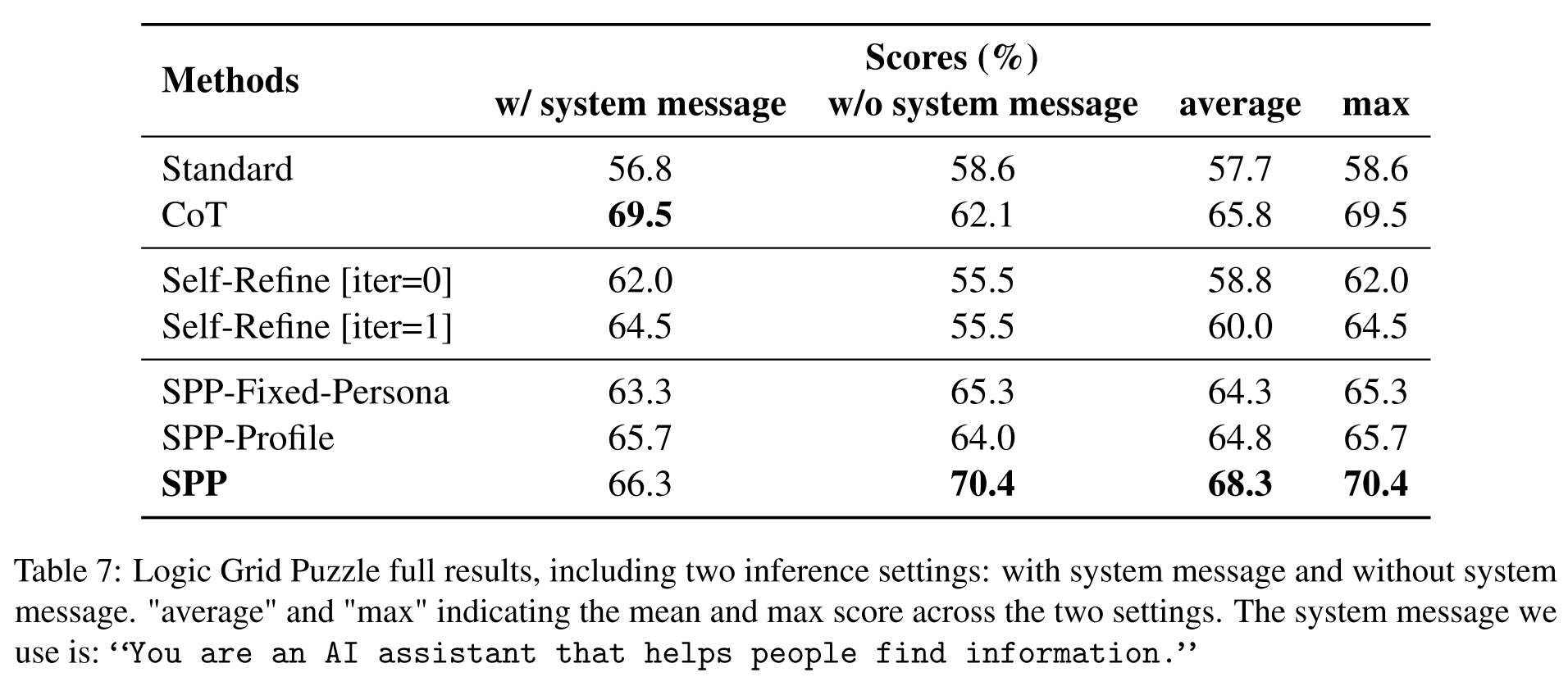
- dataset: Logic Grid Puzzle data from BigBench
- evaluation metric: accuracy of the predicted house numbers
What are the baseline methods?
- Standard Prompting
- Chain-of-Thought (CoT) Prompting
- Self-Refine
What are the results of the experiments?
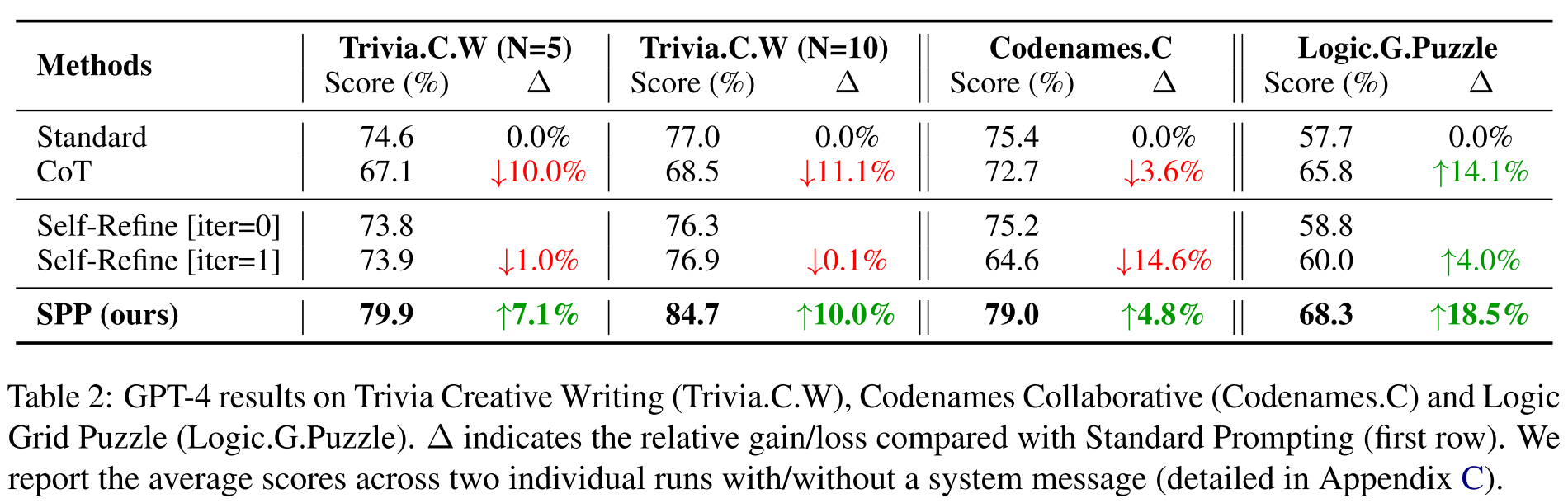
Trivia Creative Writing: SPP > Standard Prompting > Self-Refine [iter=1] > Self-Refine [iter=0] > CoT
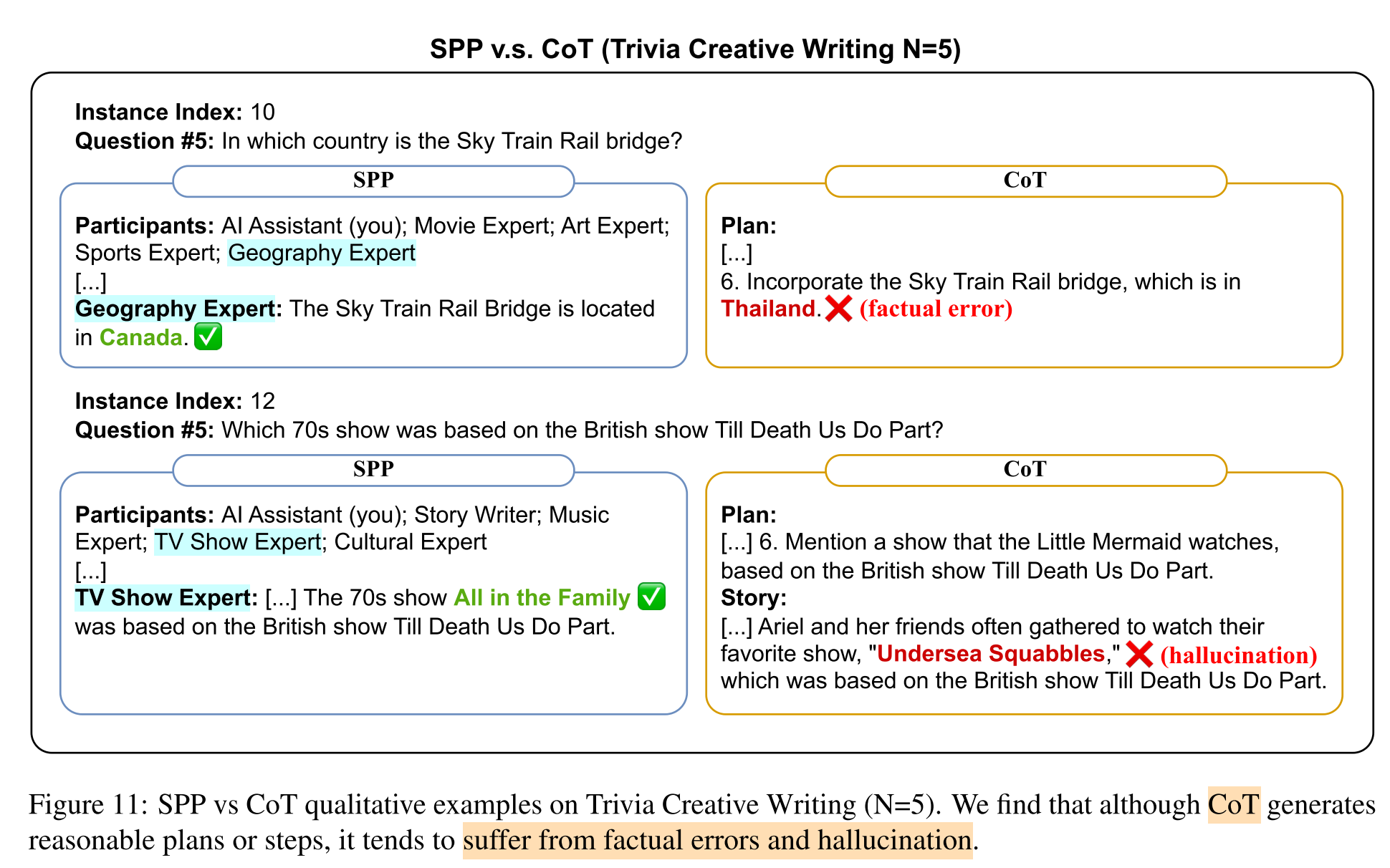
- CoT underperforms standard prompting —> CoT is ineffective in eliciting LLM’s knowledge ability, final solution still contains factual errors and hallucinations

- Self-Refine: only marginal improvements over iterations
- SPP outperforms all baselines significantly —> SPP is particularly beneficial when the task requires incorporating knowledge from numerous domains
Codenames Collaborative: SPP > Standard Prompting > Self-Refine [iter=0] > CoT > Self-Refine [iter=1]
- CoT underperforms standard prompting
- Iterative Self-Refine degrades performance (tends to change the initial solution even if it is already good)
- SPP outperforms all baselines significantly —> effective on collaborative tasks that require knowledge, reasoning, and theory of mind skills
- SPP generates detailed and interpretable intermediate dialogues
Logic Grid Puzzle: SPP > CoT > Self-Refine [iter=1] > Self-Refine [iter=0] > Standard Prompting
- CoT outperforms Standard Prompting —> CoT elicits better reasoning ability
- SPP performs the best
What are the most important findings and conclusions of this work?
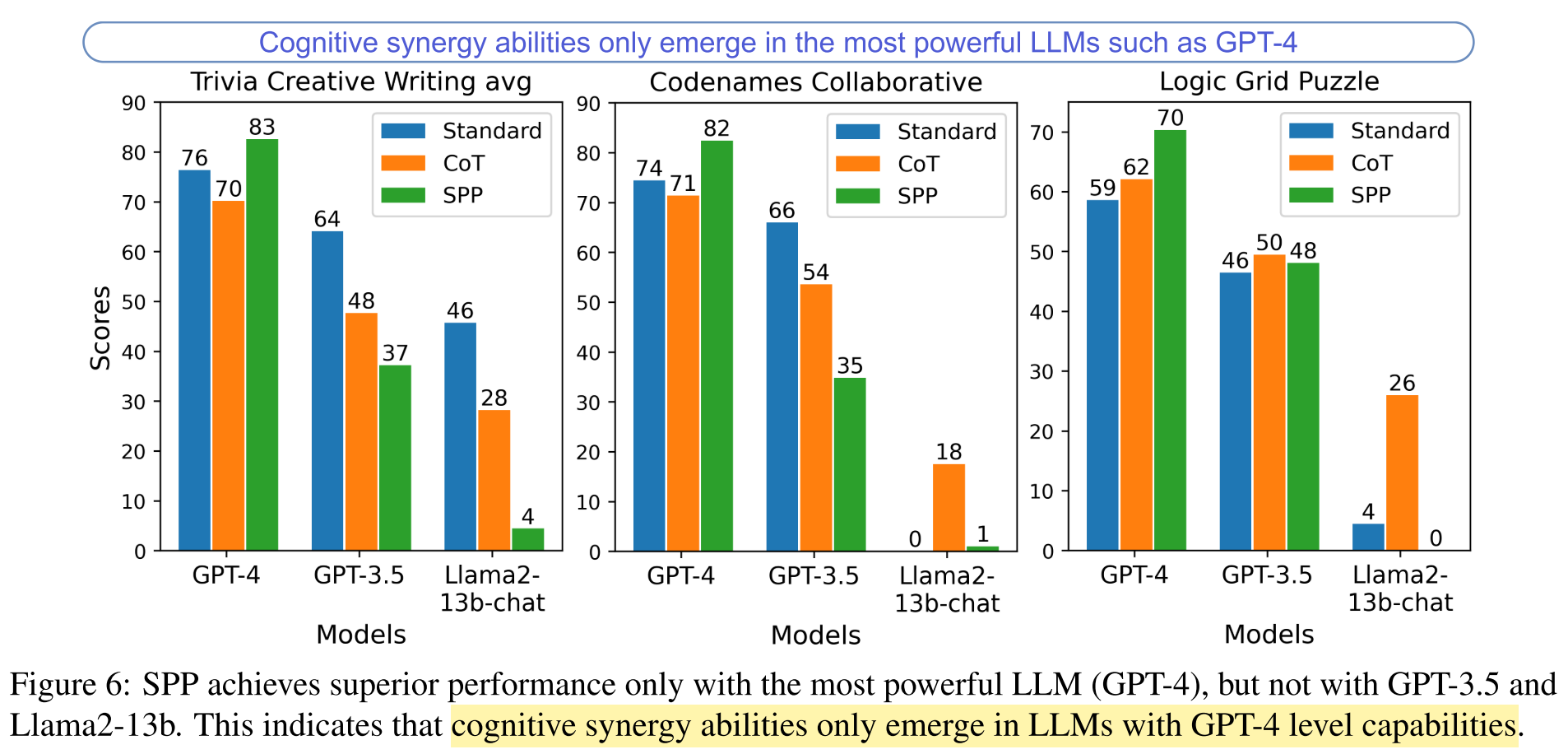
SPP effectively unleashes cognitive synergy and improves both knowledge and reasoning abilities in GPT-4-level LLMs, but not in smaller, less capable models, such as GPT-3.5-turbo and Llama2-13b-chat.
SOTA LLMs (i.e. GPT-4) can effectively identify accurate and useful personas in a zero-shot manner.
- Are the identified personas highly relevant to the tasks?
- Yes.
- On knowledge-intensive tasks: SPP identifies more diverse and specific personas.
- On reasoning-intensive tasks: SPP identifies more homogeneous personas.
- Is a detailed profile for each persona necessary for eliciting domain knowledge?
- SPP-Profile: generating profiles for each persona during the Persona Identification phase
- SPP > SPP-Profile
- A fine-grained persona without a detailed profile may already be sufficient for eliciting certain domain knowledge.
- Are the identified personas highly relevant to the tasks?

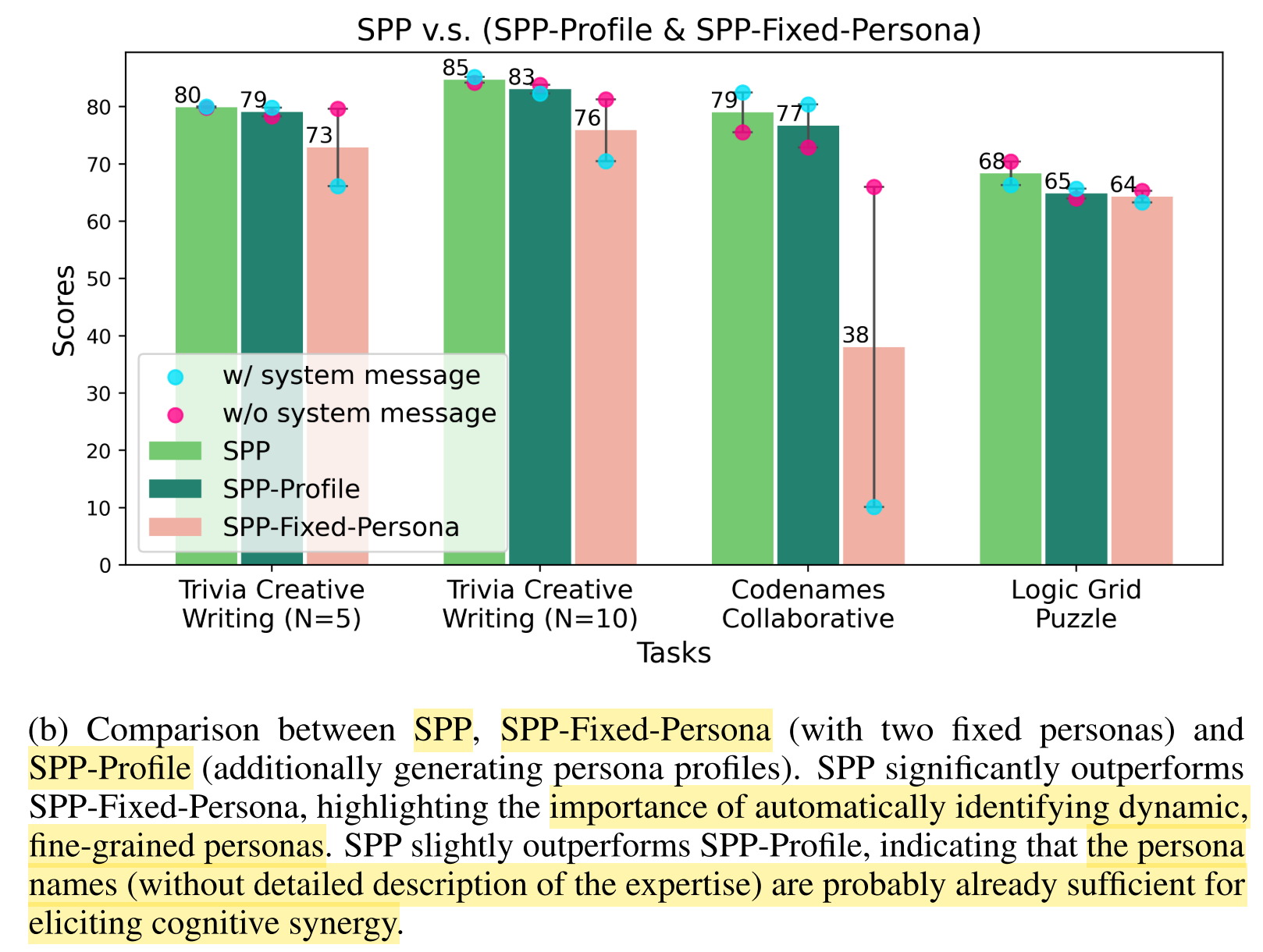
Dynamic, fine-grained personas vs. fixed, general personas:
- SPP-Fixed-Persona: forcing the personas to be fixed as an “AI Assistant” and an “Expert”
- SPP > SPP-Fixed-Persona
- Dynamic, fine-grained personas are more effective than fixed, general personas.
- Fixed personas induces the early-termination problem, where the model stops generating after identifying the participants.
- Removing the system message can effectively reduce the early-termination problem, but cannot fully eliminate it.
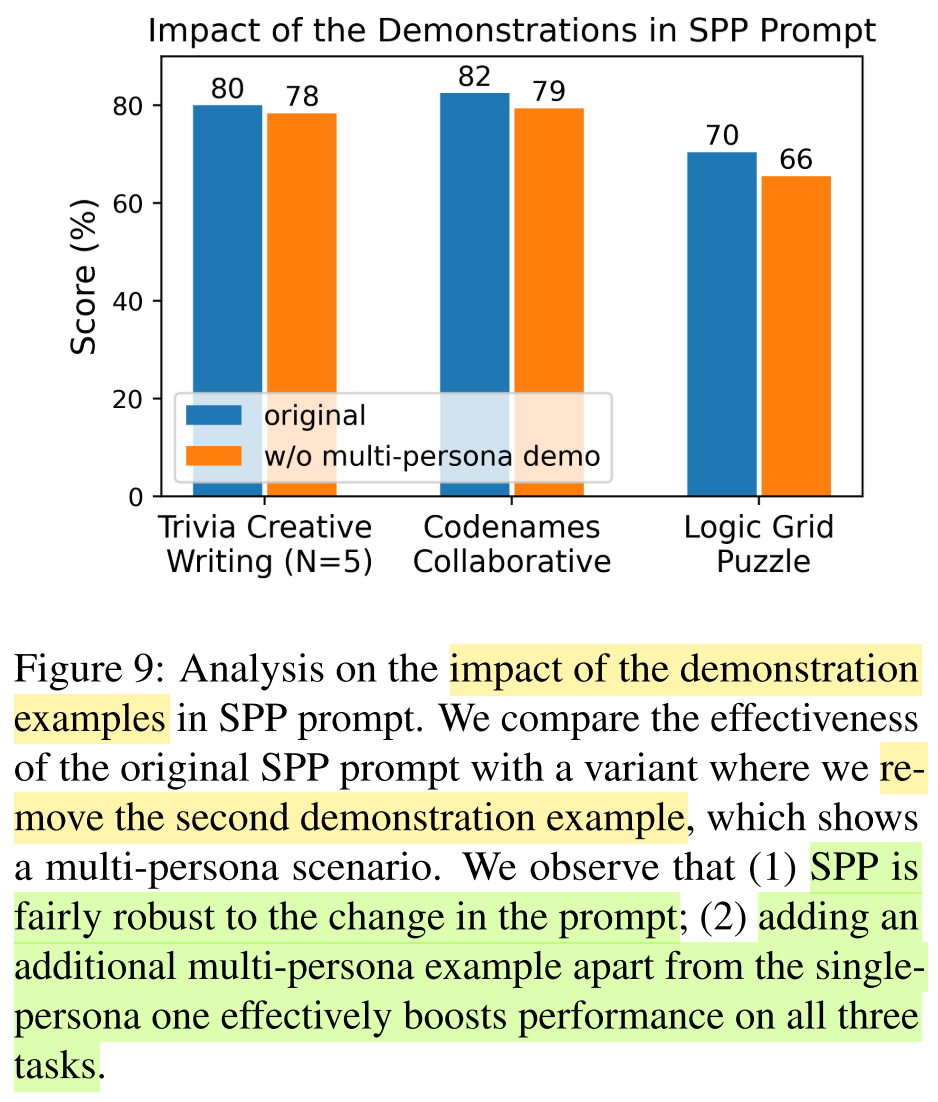
Impact of demonstration examples in SPP prompt:
- Ablation study: remove the second demo example which contains more than two personas
- SPP is fairly robust to the prompt change and show good performance with only the first demo example.
- Adding the second demonstration example which requires collaboration of more than two personas further boosts the performance.
The brainstorming phase effectively improves the quality of the initial solution.




What do you find most interesting about this work?
- SPP mitigates factual hallucinations in knowledge-intensive tasks.
- The cognitive synergy can only be fully unleashed in LLMs with a certain level of instruction-following capabilities, akin to that of GPT-4.
- The effectiveness of SPP is not seen in smaller and less capable models, such as GPT-3.5 and Llama2-13b-chat.
- Llama2 suffers from a unique early-termination problem, where the model stops generating after identifying the participants, behaving as if it were waiting for input from a user instead of following the examples to generate responses on its own (cf. Appendix E).

What are the origins of factual hallucinations in this task?
The factual hallucinations are observed in the final output generated using CoT prompting in the knowledge-intensive Triva Creative Writing task (cf. Figure 8, 11).
How are the factual hallucinations mitigated?
SPP unleashes the cognitive synergy within an LLM, which effectively simulates different personas that provide productive advice to revise the answer.
What are the main advantages and limitations of this paper?
Advantages:
- SPP works in a solely zero-shot manner, saving resources for training / fine-tuning and data annotation.
- SPP does not require external knowledge base and additional knowledge retrieval systems (cf. RAG).
- The multi-persona role-playing and multi-turn self-collaboration is done by a single LLM and does not require additional LLM instances.
- SPP mitigates factual hallucinations in the knowledge-intensive task that are common when using CoT.
- SPP elicits both knowledge and reasoning abilities in LLMs, improving factuality while maintaining strong reasoning performance.
Limitations:
Even when a fine-grained persona is assigned, the generated answer may still be incorrect.
- It is unclear to what extent assigning a persona can help enhance domain knowledge in a specific area.
- Diagnostic experiments and theoretical investigation are needed to quantify the impact of having a persona or not.
The prompt contains two demo examples. Why do the authors call their method “zero-shot”?
Adopting the SPP prompt with the same two demo examples for all tasks is suboptimal.
- need better task-specific demo examples
Single-agent cognitive synergist has limited local memory and enables less flexible human-computer interaction.
SPP cannot unleash the cognitive synergist in smaller, less capable models, which posses relatively less instruction-following ability.
- The authors claim: A strong instruction-following ability is a pre-requisite for SPP to effectively elicit cognitive synergy in LLMs.
What insights does this work provide and how could they benefit the future research?
- Recent research: Assigning personas / roles to LLMs influences their generation behavior.
- Limitations in persona assignment and multi-agent collaboration include single or fixed persona assignments and the need for multiple LLM instances increase the inference cost.
- SPP: a single LLM, dynamically identify personas
- The emergent nature of cognitive synergy aligns with the emergent ability of self-debugging in code generation.
- LLMs face challenges in complex knowledge-intensive tasks due to the factual hallucination problem.
- CoT and Self-Refinement simulate human-like slow thinking required in reasoning-intensive tasks, but do not necessarily reduce factual hallucinations.
- RAG enhances knowledge acquisition, but does not improve the model’s reasoning ability.
- Solution of this paper: SPP, elicits both knowledge and reasoning abilities of LLMs at GPT-4-level, improving factuality while maintaining strong reasoning performance.
Comparison between different prompts:
SPP full prompt:

SPP-Profile prompt:

SPP-Fixed-Persona prompt:

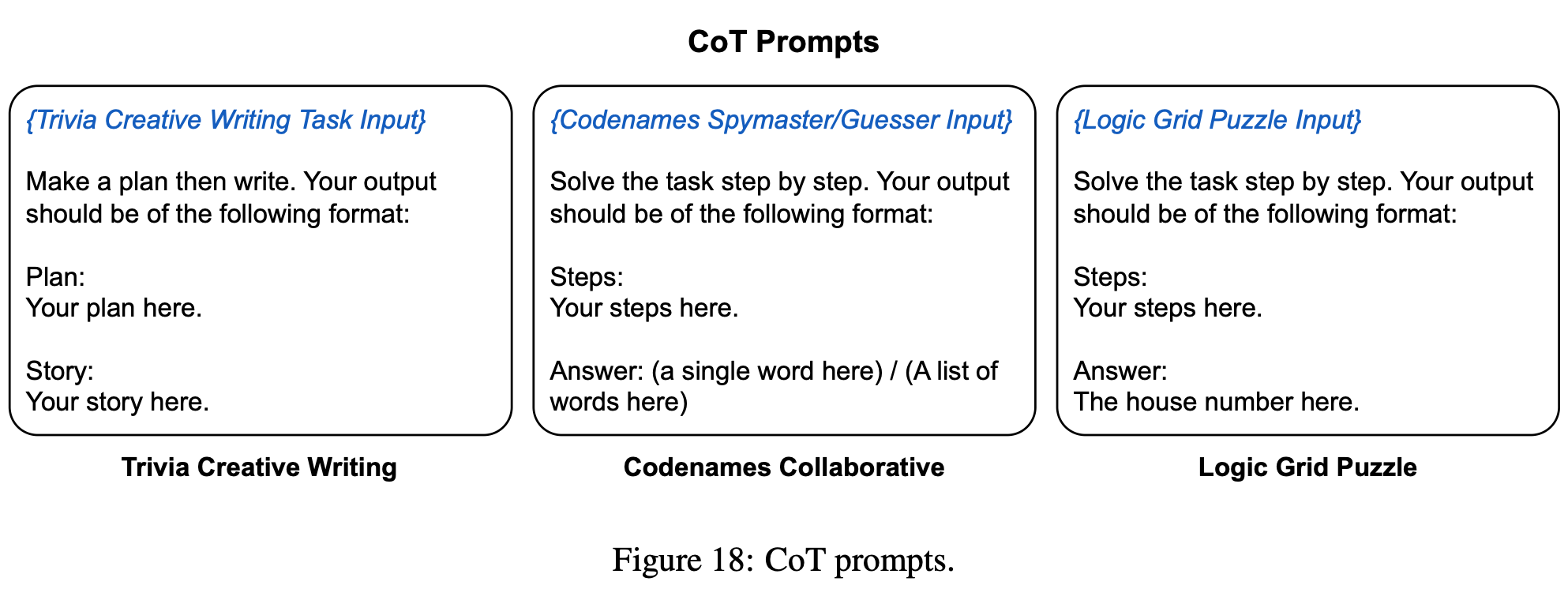
Chain-of-Thought (CoT) prompts:
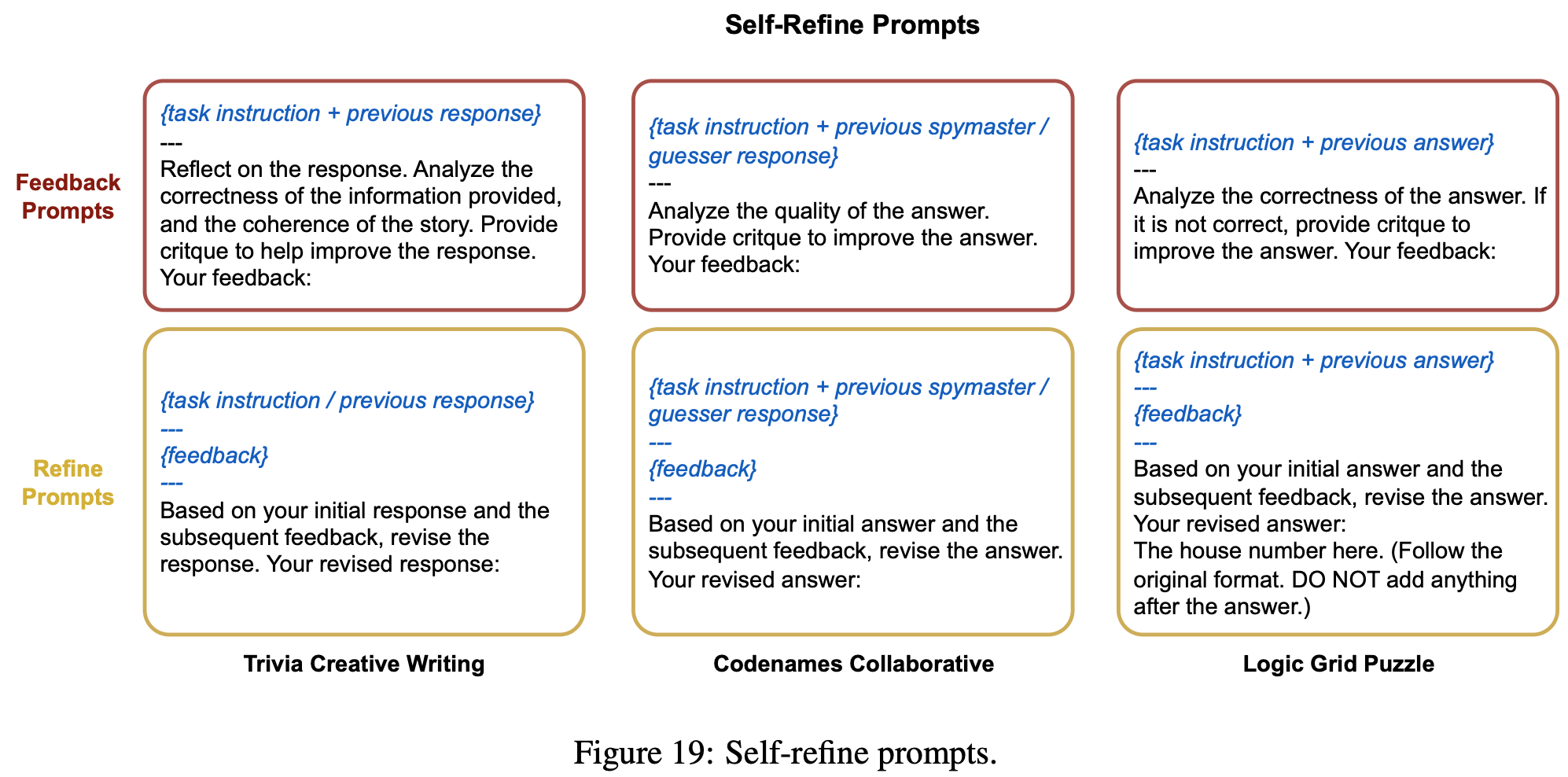
Self-Refine prompts:
- Title: Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration
- Author: Der Steppenwolf
- Created at : 2024-12-04 16:57:15
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2024/12/04/SPP/
- License: This work is licensed under CC BY-NC-SA 4.0.