Retrieval-Augmented Audio Deepfake Detection
Zuheng Kang, Yayun He, Botao Zhao, Xiaoyang Qu, Junqing Peng, Jing Xiao, and Jianzong Wang. 2024. Retrieval-Augmented Audio Deepfake Detection. In Proceedings of the 2024 International Conference on Multimedia Retrieval (ICMR ‘24). Association for Computing Machinery, New York, NY, USA, 376–384. https://doi.org/10.1145/3652583.3658086
What problems does this paper address?
Audio Deepfake Detection: Detect model-generated deepfake (DF) audios.
Retrieval-based Augmentation: Augment test samples with knowledge retrieved from samples in an external knowledge base.
What’s the motivation of this paper?
- Potential malicious use of AI-synthesized speech has serious personal and societal implications, increasing the need to develop effective DF detection techniques, and to build robust and reliable DF detection systems.
- Early DF detection methods rely on hand-crafted features, exhibiting limited performance due to the limited size of training set.
- More recent DF detection methods leverage self-supervised model as feature extractor, or replace hand-crafted features with end-to-end trainable encoders. These methods rely solely on the fuzzy parametric knowledge learned by a single model, resulting in performance bottlenecks and transparency issues.
Research Questions:
RQ1: Does the RAD framework reduce detection errors?
RQ2: Does updating external knowledge for the RAD framework further improve detection performance?
RQ3: Can the retrieved audio samples be interpreted?
RQ4: Does time-wise speedup method affect downstream DF detection performance?
What are the main contributions of this paper?
- This paper proposes a Retrieval-Augmented Detection (RAD) framework for audio deepfake detection.
- This paper extends the multi-fusion attentive classifier to integrate with RAD.
- This paper conducts extensive experiments to demonstrate the effectiveness of the proposed method.
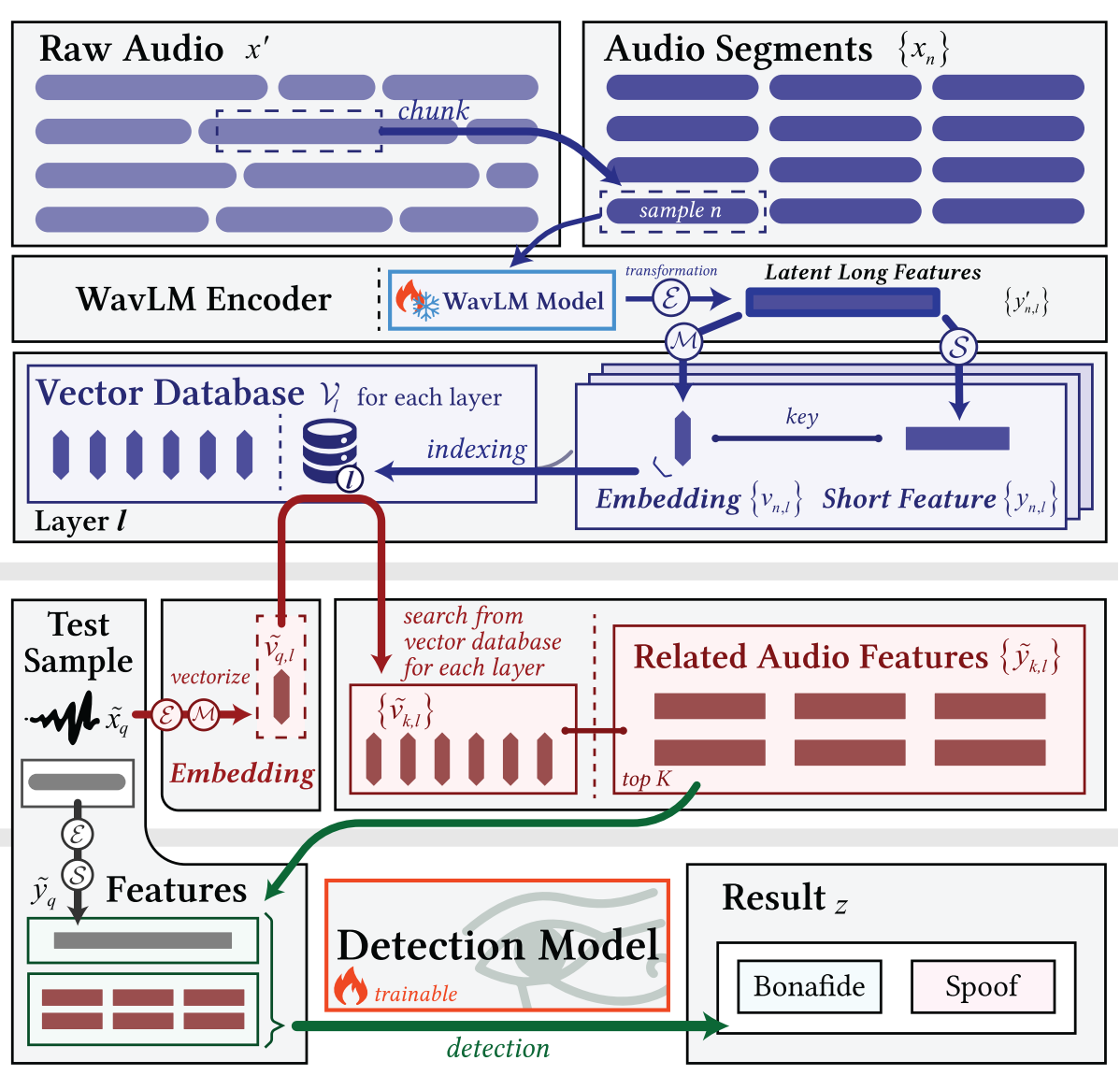
RAD Framework Architecture
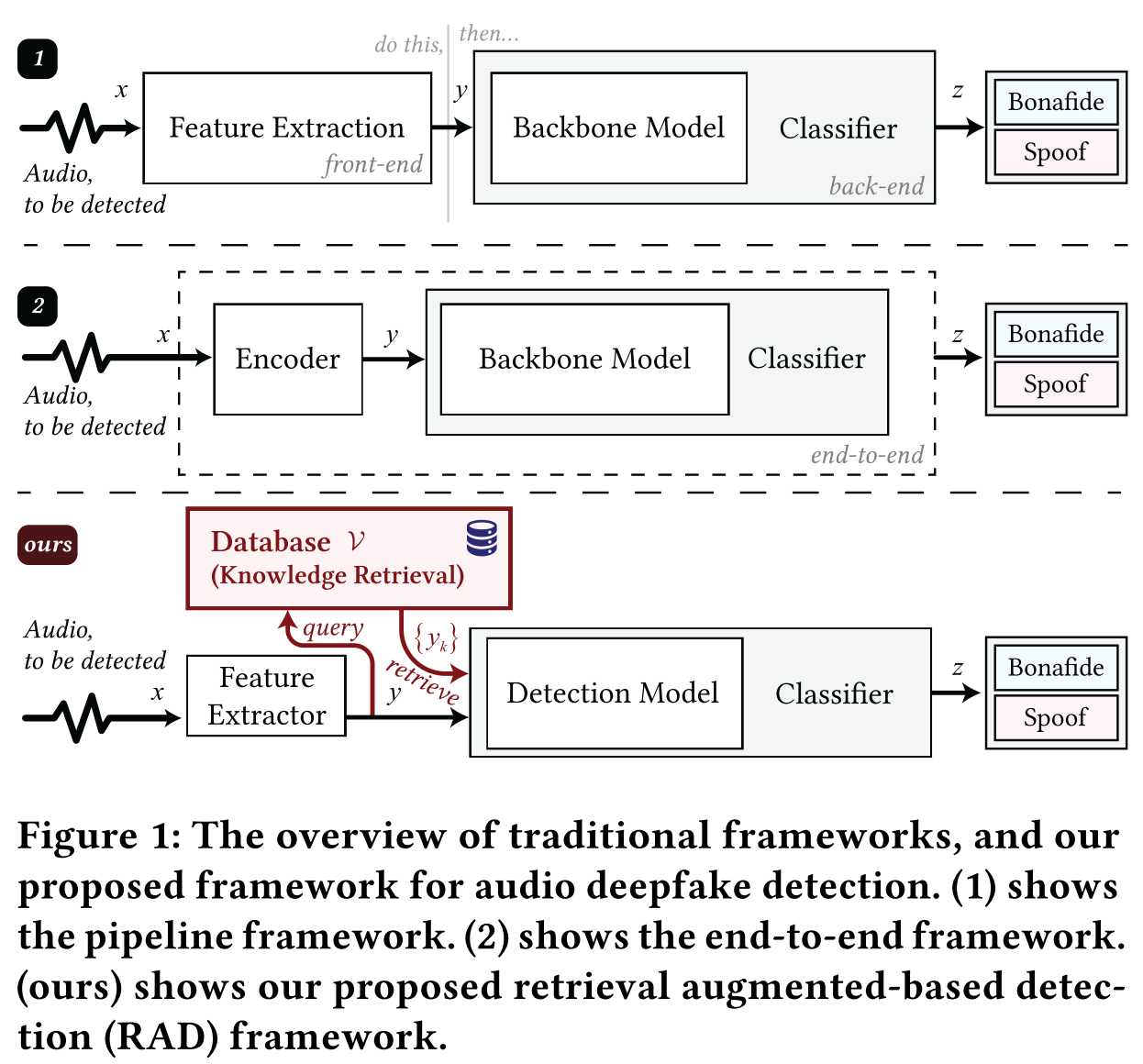
How does the RAD framework differ from pipeline and end-to-end frameworks?
How does the RAD method differ from Retrieval-Augmented Generation (RAG)?
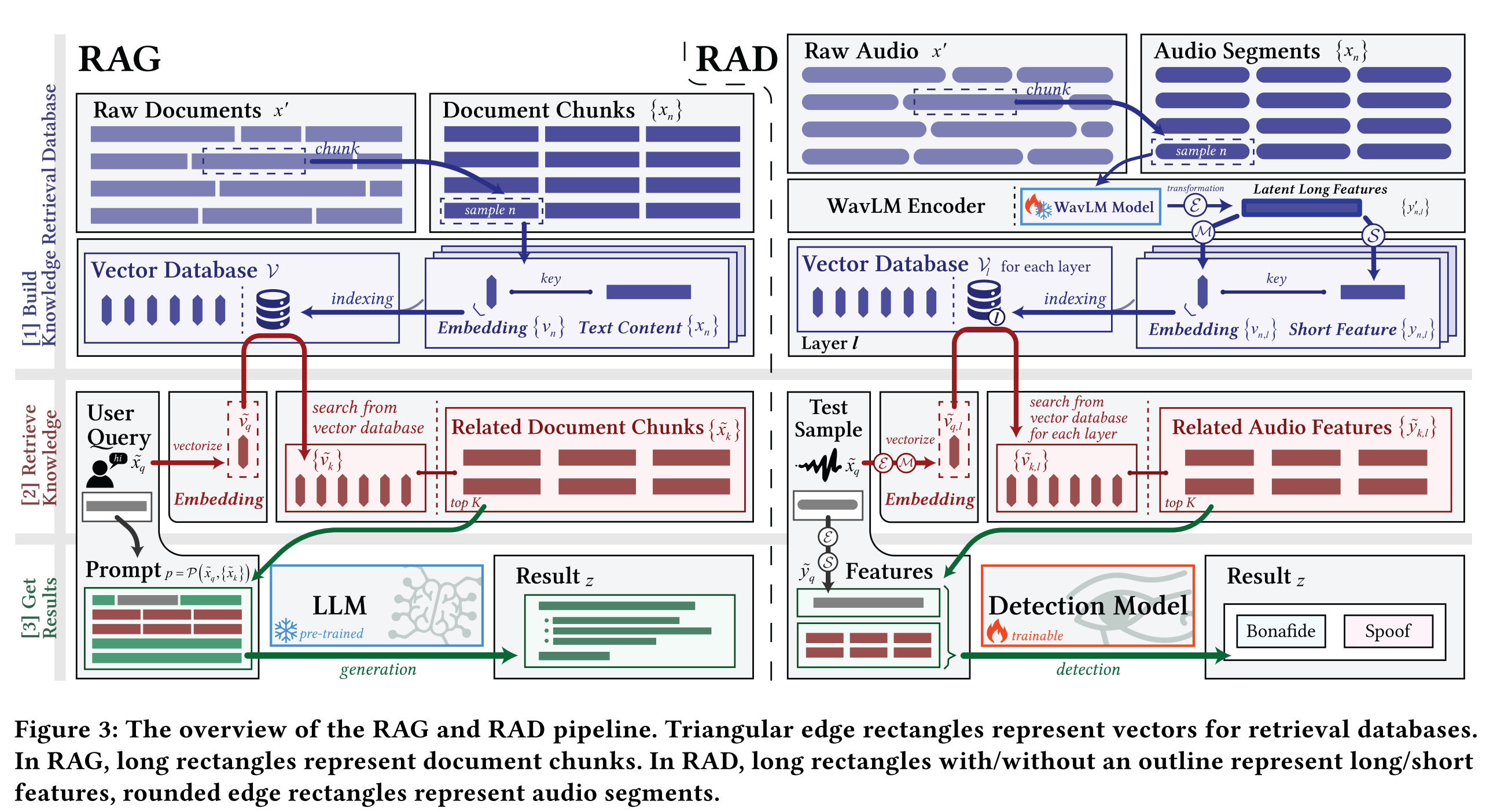
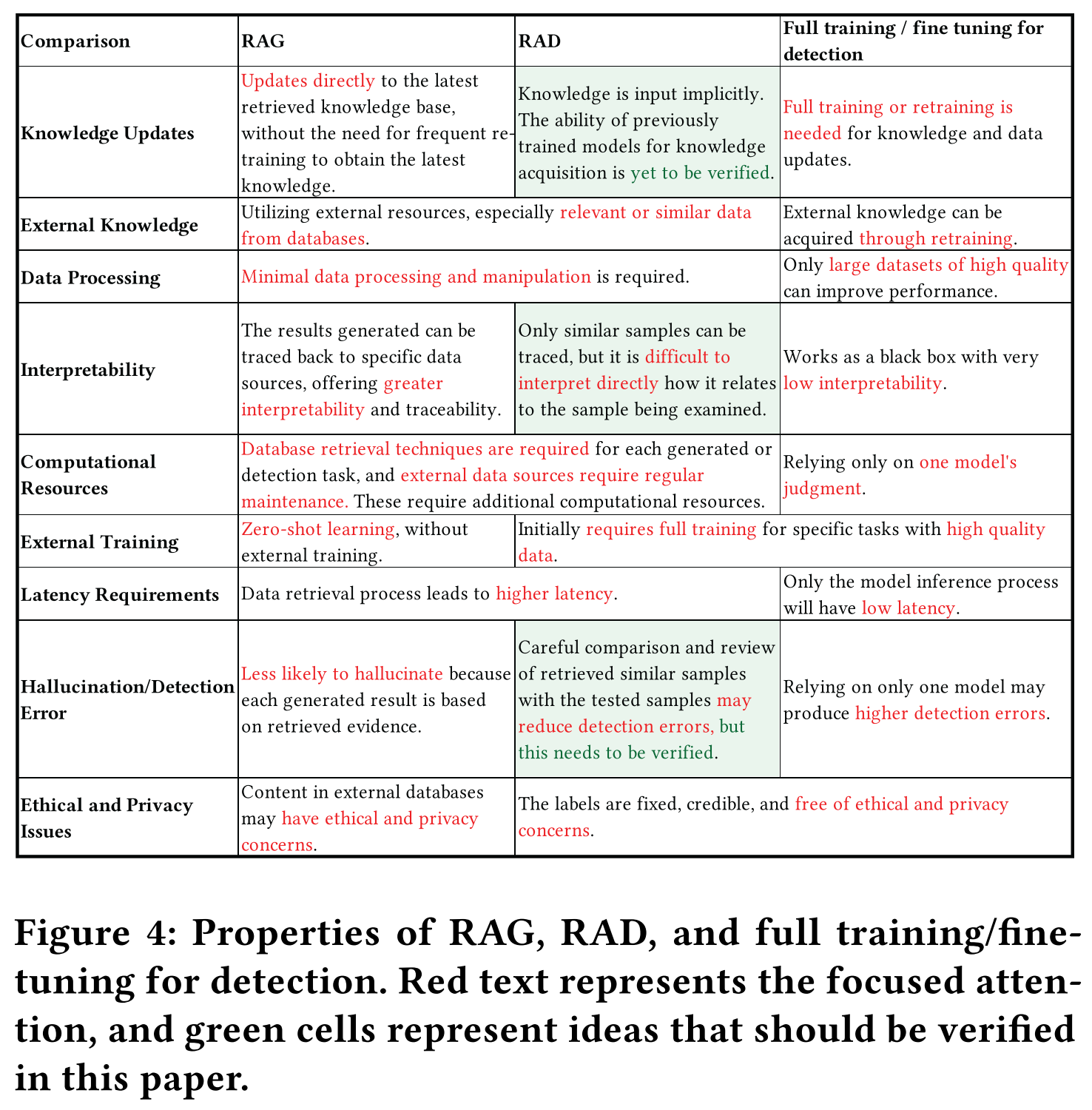
How does the proposed method (RAD) work?
1. Build Knowledge Retrieval Database
- Segment bonafide audio dataset into smaller audio segments.
- Encode the audio segments to latent long feature representations using a fine-tuned WavLM feature extractor.
- Each of the l hidden layers of the WavLM feature extractor produces a long feature for each audio segment, resulting in l long features for each audio segment.
- Perform two operations on the long features in parallel:
- Embed the long features into dense vector representations (i.e. embeddings) via a function M.
- Shorten the time dimension of the long features to form short features via a function S.
- Each embedding maintains an index linking to its original short feature.
- Store the collection of embeddings coming from the l WavLM layers in l vector databases.
2. Retrieve Knowledge
- Embed a test sample audio (query) into a query embedding using the WavLM feature extractor and the function M.
- Perform a similarity search for the query embedding across all l vector databases.
- Retrieve the top-K most similar embeddings, along with their assoicated short features.
3. Sample Detection
- Convert the test sample audio (query) to short features using the WavLM feature extractor and the function S.
- Combine the query short features and the top-K similar short features as input to a trainable DF detection model.
- The detection model predicts whether the query is bonefide or spoof, by comparing the query with the most similar samples.
Which models are used?
1. WavLM
Fine-tune WavLM for enhanced feature extraction:
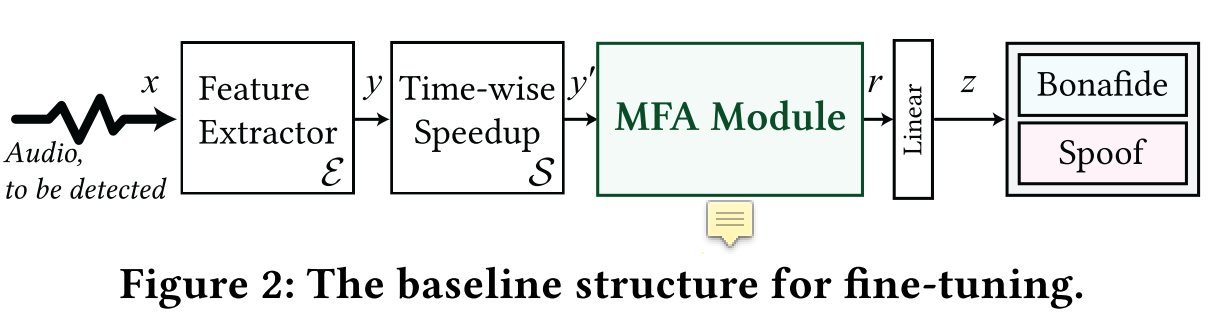
- Issue of the off-the-shelf WavLM: It was pre-trained only on bonafide audio and may not have exposure to spoofed audio.
- Fine-tune the WavLM feature extractor in an end-to-end manner, with time-wise speedup, a Multi-Fusion Attentive module, and a fully connected linear binary classification layer.
- Fine-tuning task: audio deepfake detection (bonafide / spoof)
- After fine-tuning: enhanced WavLM model that serves as an improved feature extractor.
2. DF detection model
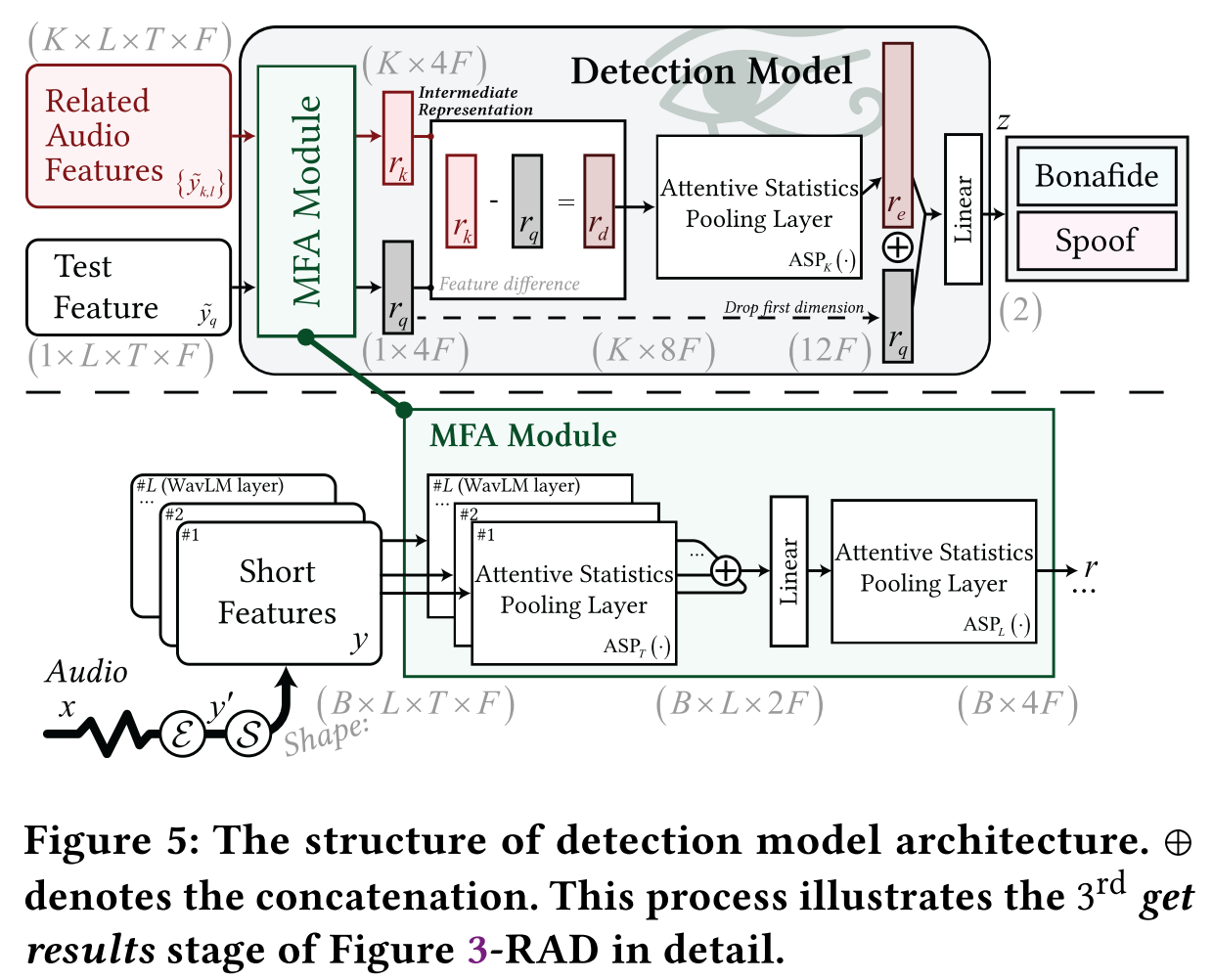
- Extend a Multi-Fusion Attentive (MFA) classifier to integrate it into the RAD framework.
- Input the test sample (query) feature and the retrieved features into the MFA module, creating two intermediate representations r_q and r_k.
- Calculate the difference r_d between r_q and r_k.
- Input r_d into a sample-wise ASP layer, resulting in an intermediate representation r_e.
- Concatenate r_e with r_q, send then to a fully connected layer for final classification.
What measures are taken for the performance optimization?
- Pre-compute and cache the WavLM features of all audio segments in the KB to speed up the training and testing.
- Time-wise speedup:
- Motivation: Acoustic features extracted by WavLM have a large frame-to-frame hop size and a large number of layers, resulting in an extremely large number of generated feature parameters that require significant storage space.
- Split the long features extracted by WavLM along the time dimension into multiple partitions with the help of an introduced speedup parameter.
- Take the average along the partitions to get the speedup short feature using the function S.
Which datasets are used?
- ASVspoof 2019 LA
- ASVspoof 2021 LA
- VCTK
Which evaluation metrics are used?
- min t-DCF (minimum normalized tandem detection cost function): measure the combined (“tandem”) performance of the ASV systems
- pooled EER (pooled equal error rate): measures the independent DF detection capability
What are the results and conclusions of the experiments?
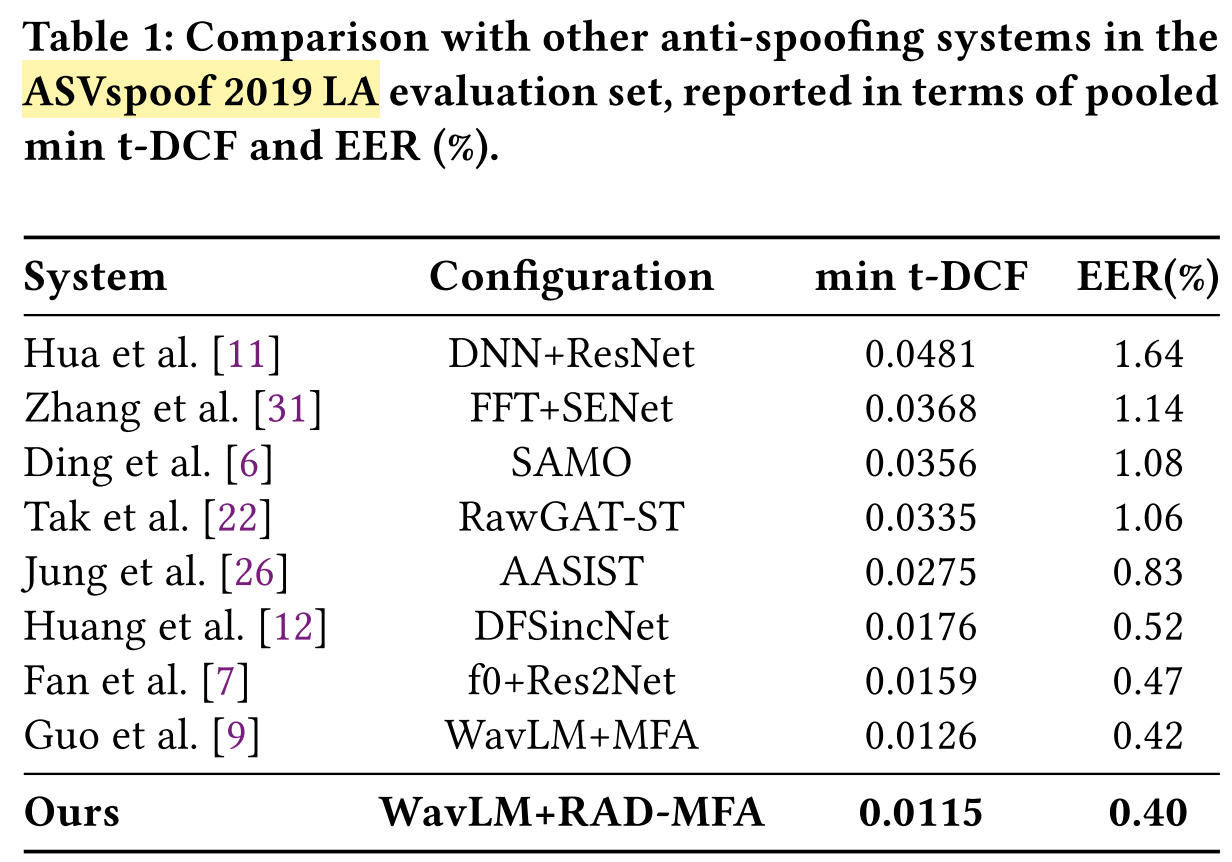
- Result: RAD achieves the highest scores of EER (0.40%) and min t-DCF (0.0115).
Conclusion: RAD is effective and superior. - Result: RAD outperforms Guo et al., which use a similar WavLM feature extractor and MFA network.
Conclusion: RAD overcomes the limitations of single-model approaches.
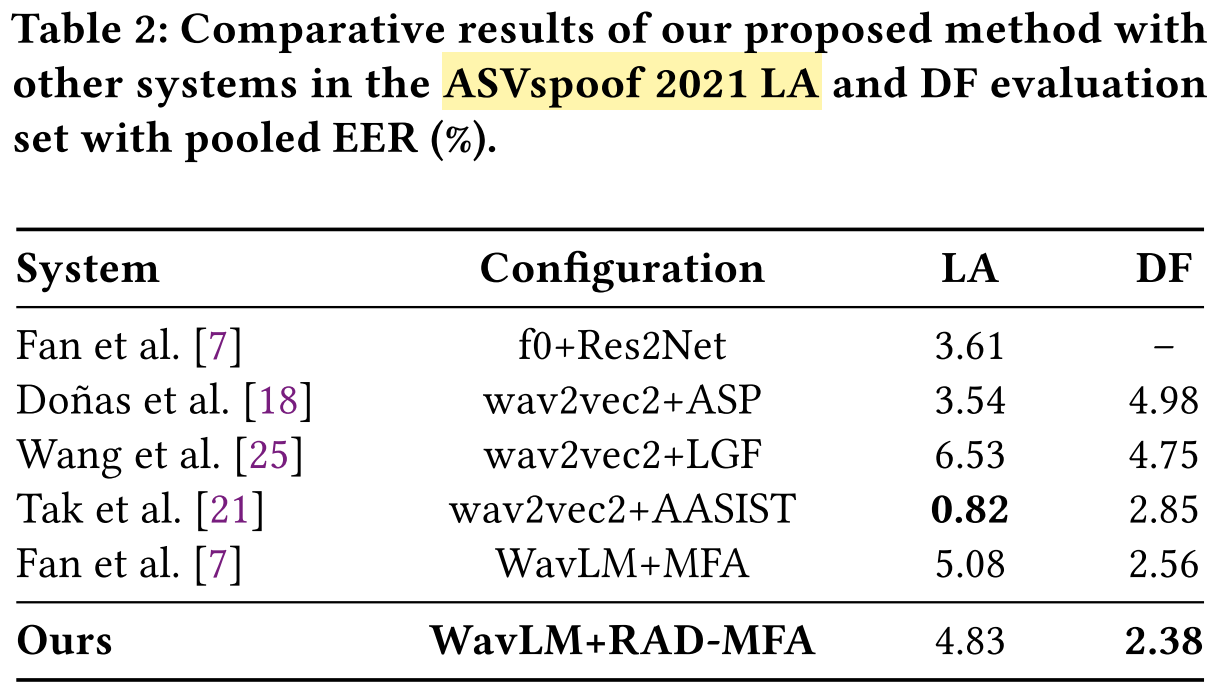
- Result: RAD achieves SOTA performance on the DF subset (EER = 2.38%).
- Result: RAD achieves competitive performance on the LA subset (EER = 4.89%).
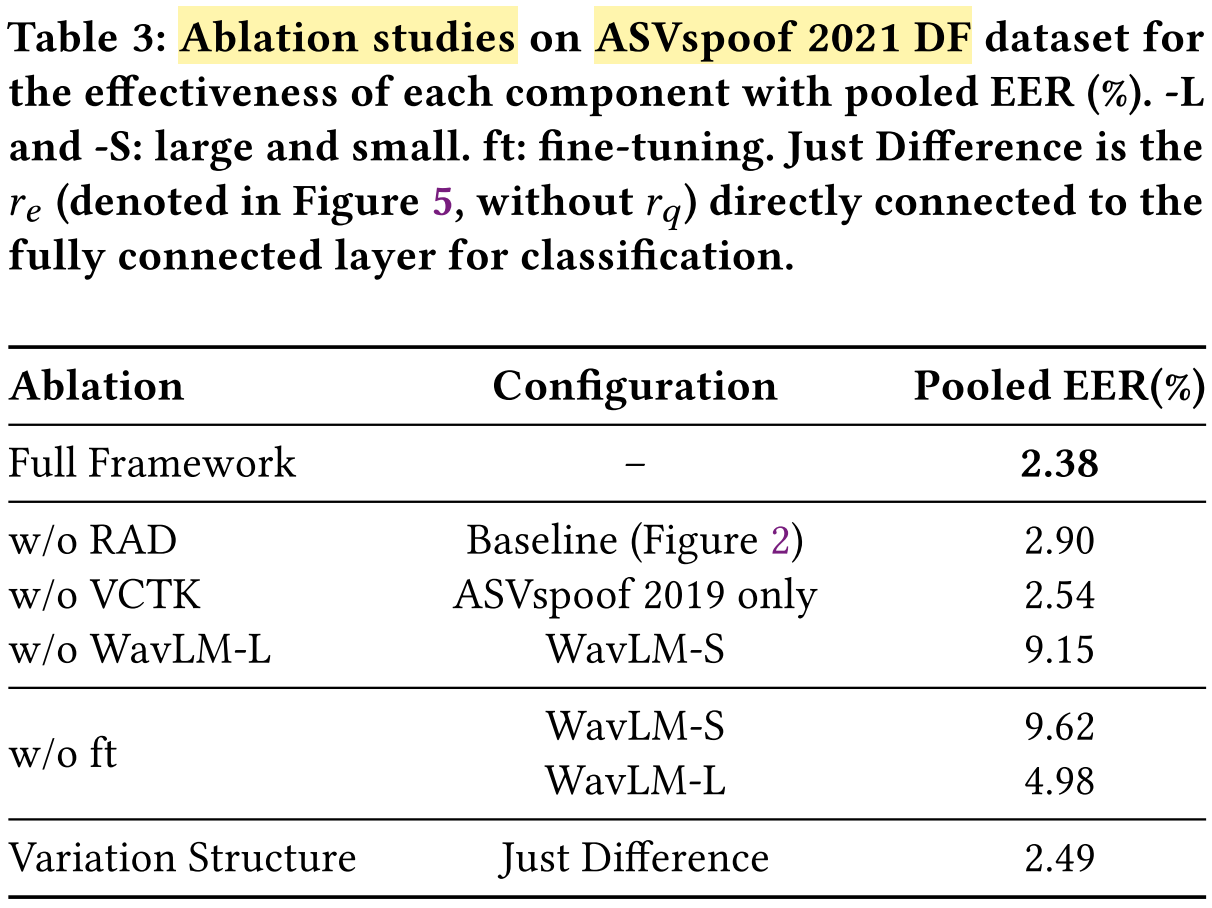
Ablation Study:
Evaluate different configurations and components of the RAD system on ASVspoof 2021 DF subset.
Analyze the impact of:
- the RAD framework
- WavLM-L feature extractor
- fine-tuning of the feature extractor
- incorporation of additional VCTK datasets for data retrieval
- the structure of the detection model
Evaluation metric: pooled EER
Result: The full RAD system achieves the SOTA performance (EER = 2.38%).
Result: Removing RAD for similar sample retrieval increases the pooled EER.
Conclusion: Answer to RQ1: The RAD framework is effective in reducing the detection error.Result: Excluding the summplementary VCTK dataset slightly increases the pooled EER
Conclusion: Answer to RQ2: Updating the knowledge with additional related data improves the performance.Result: Replacing WavLM-L with WavLM-S significantly increases the pooled EER, i.e. decreases the performance.
Conclusion: The feature extractor is important.Result: EER rises drastically without fine-tuning.
Conclusion: Fine-tuning has positive influence in enhancing DF detection performance.Result: Removing the r_q branch and directly connecting r_e to the classifier slightly increases the pooled EER.
Conclusion: Not only the difference of the feature, but also the original feature play the role for performance improvement.Result: The smaller the time-wise speedup parameter is, the better the performance, but also much higher computational cost and storage consumption.
Conclusion: Answer to RQ4: The time-wise speedup operation will affect the performance, but not too much.Result: The system appears to retrieve samples from the same speaker identities.
Conclusion: The system might rely strongly on speaker-discriminative features.Result: Initial layer retrievals correspond to the same speakes. Middle and final layer retrievals may differ in speaker identity.
Conclusion: The shallower layers of the model may focus on timbral and quality-based features. The deeper layers capture more abstract semantic information. A careful comparison of the retrieved results with the test sample will be a key factor in the performance improvement.
What are the main advantages and limitations of this paper?
Advantages:
- This paper addresses the performance bottlenecks and transparency issues of single-model DF detection approaches by utilizing bonafide audio segments from external DBs.
- This paper proposes a novel retrieval-augmented framework to effectively retrieve the external bonafide samples that are particularly similar to the query audio and makes comprehensive judgements on their contents and distributions, which enables the model to achieve more accurate detection results.
- The proposed method is more robust than previous methods, and can distinguish more detailed information in the input accuratelly by focusing on fine-grained differences rather than general parametric knowledge.
- This paper applies efficient performance optimization methods to accelerate the training and testing process, and saving the storage.
- This work analyzes how embeddings extracted from different layers of the WavLM feature extractor affect the performance, providing insights on the different knowledge encoded in different layers of the foundation model.
Limitations:
- The vector database contains audio segments produced by the same speaker as the queqry audio. This makes the detection task trivial. The authors should ensure that the audios in the database are made by different speakers from that of the test audio, or avoid retrieving audios from the same speaker.
- The related audio features are solely from bonafide audios. Incorporating audio features of spoofed audios could potentially help the detection model better distinguish bonafide audios from spoofed ones, for example, via contrastive learning.
- The paper does not answer RQ3 with sufficient analyses.
- This paper only uses WavLM as the feature extractor. It would be meaningful to compare different foundation models as the feature extractor, or even combine the features extracted from different foundation models, e.g., through feature selection and feature fusion.
What insights does this work provide and how could they benefit the future research?
- Title: Retrieval-Augmented Audio Deepfake Detection
- Author: Der Steppenwolf
- Created at : 2024-12-04 09:26:10
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2024/12/04/RADDeepfake/
- License: This work is licensed under CC BY-NC-SA 4.0.