FREB-TQA: A Fine-Grained Robustness Evaluation Benchmark for Table Question Answering
Wei Zhou, Mohsen Mesgar, Heike Adel, and Annemarie Friedrich. 2024. FREB-TQA: A Fine-Grained Robustness Evaluation Benchmark for Table Question Answering. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2479–2497, Mexico City, Mexico. Association for Computational Linguistics.
What problems does this paper address?
The evaluation of the robustness of architecturally different TQA systems against various types of perturbations on the input table.
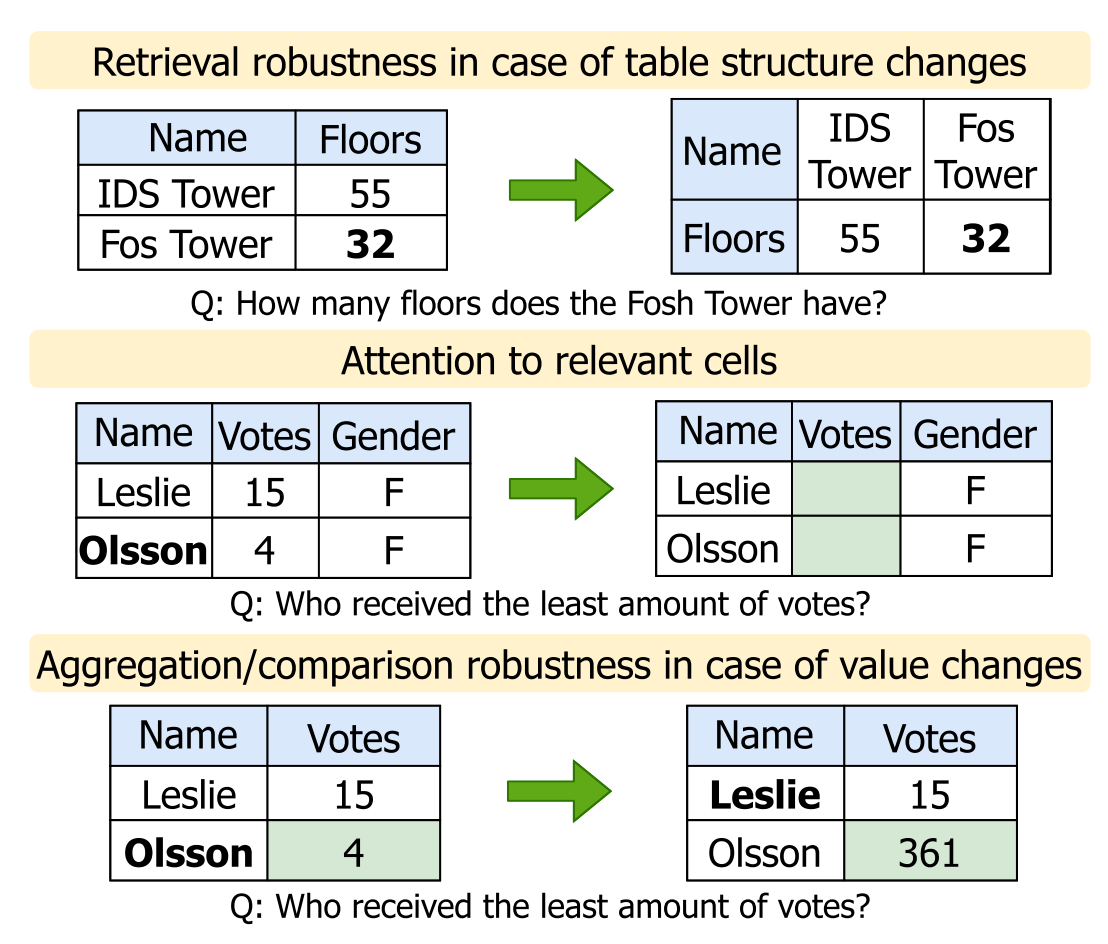
What’s the motivation of this paper?
Current TQA systems generate inconsistent responses by performing coarse-grained changes in tables and questions. Existing benchmarks fail to differentiate between different aspects of robustness. The underlying cause and nature of the lack of robustness of TQA models remains unclear. Thus, it is necessary to pinpoint the exact failures of TQA systems for improving their robustness.
Research Questions:
RQ1: Are TQA systems robust against table structure changes?
- RQ1.1: Do TQA systems exhibit any positional biases?
- RQ1.2: Do TQA systems have a bias towards particular table layouts?
RQ2: Can TQA systems pay attention to relevant cells while being robust against their intrinsic knowledge or positional biases?
- RQ2.1: To what extent TQA systems bypass relevant cells to derive their answers?
- RQ2.2: Would TQA systems bypass the whole table and rely on their intrinsic knowledge learned from training to answer the question?
- RQ2.3: To what extent TQA systems bypass table cell values and rely on the position of relevant cells?
RQ3: Are TQA systems robust against value changes?
- RQ3.1: To what extent TQA systems perform correct aggregations and adapt answers to the value changes accordingly?
- RQ3.2: Do TQA systems articulate correct answers because of their biases to certain values?
What are the main contributions of this paper?
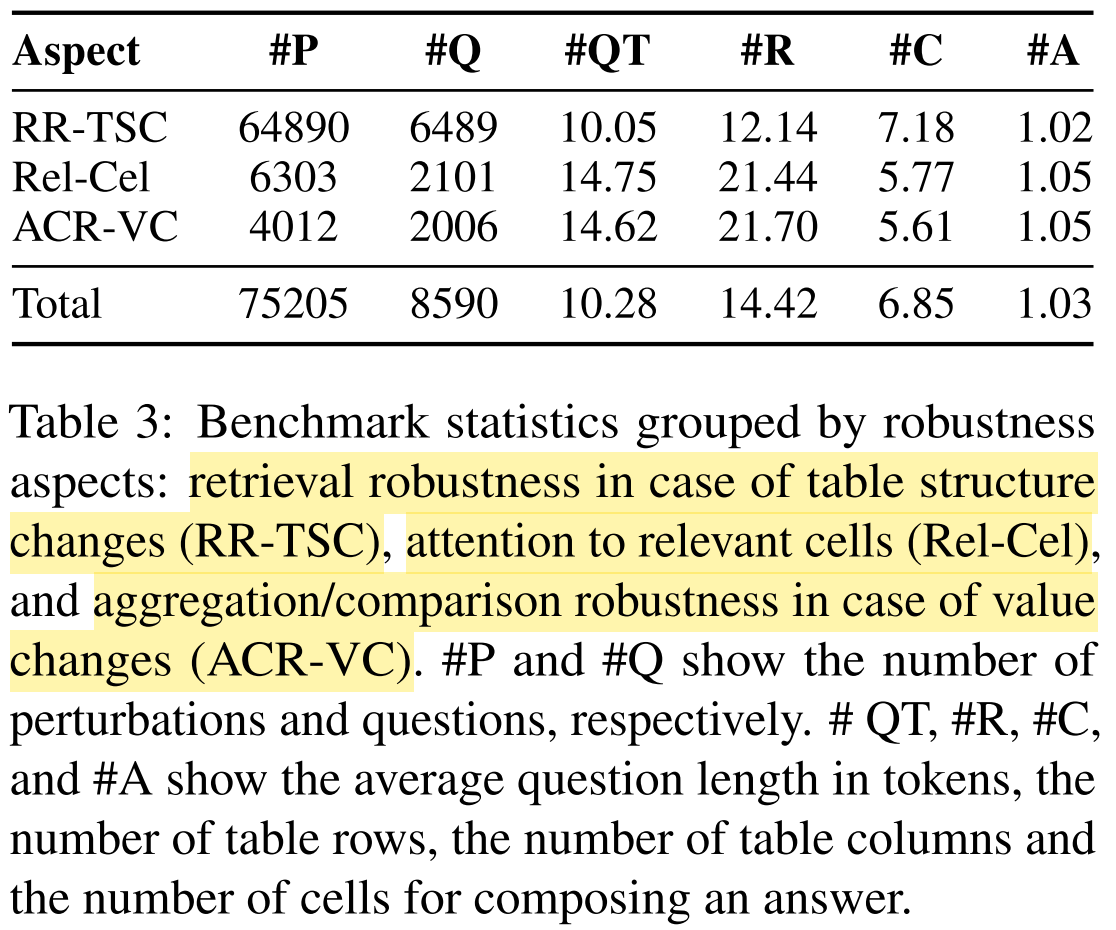
- Create FREB-TQA, a novel English benchmark for fine-grained analysis of three aspects of the robustness of TQA systems, i.e. (a) retrieval robustness in case of table structure changes; (b) robustness against intrinsic knowledge or positional biases; (c) aggregation / comparison robustness in case of value changes.
- Design seven novel automatic perturbation methods from the three aspects.
- Release a dataset with high-quality human annotations.
- Evaluate a range of TQA systems with various architectures (end-to-end, pipeline) and off-the-shelf LLMs (GPT-3.5, LLaMA2-13b).
How is the dataset created?
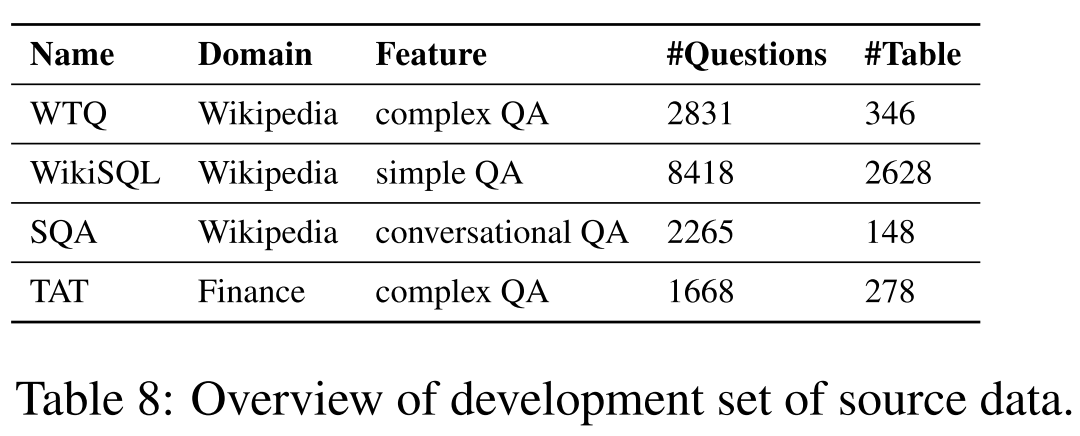
- Step 1: Start with the dev sets of four existing TQA datasets:
- WikiTableQuestions (WTQ)
- WikiSQL
- Sequential Question Answering (SQA)
- Tabular And Textual dataset for Question Answering (TAT)
- Step 2: Eliminate questions related to the table structure using a pre-defined word list
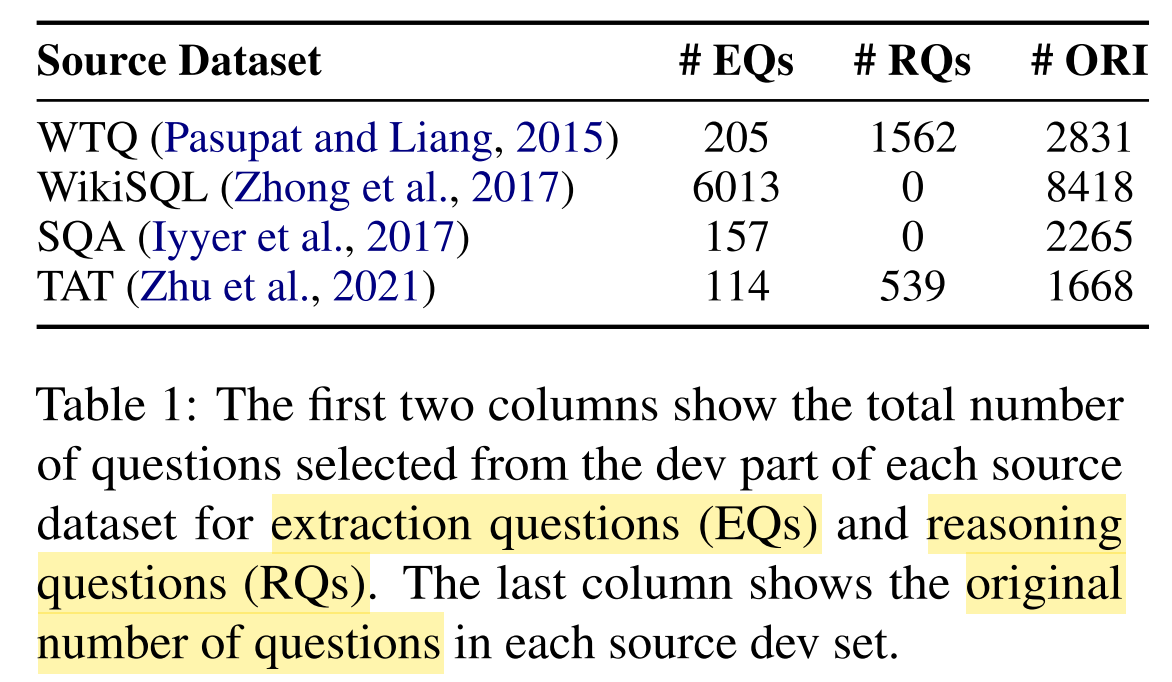
e.g., “What is the name of the actor in the first row?“ - Step 3: Group questions into Extraction Questions (EQs) and Reasoning Questions (RQs)
- Goal: To decouple the robustness aspects.
- For WTQ:
- Heuristics:
- Whether the question merely require cell value retrieval or further reasoning (e.g., comparing values of several cells).
- Lexical rule-based method:
- Given a table t, a question q, an answer a,
- String match between a and cell values in t.
- If no match: label q as RQ.
- Else:
- If q contains comparative or superlative words (signals for aggregation over table cells) using NLTK POS tags:
- label q as RQ
- Else:
- label q as EQ
- If q contains comparative or superlative words (signals for aggregation over table cells) using NLTK POS tags:
- Prompt LLaMA2-13b to classify q into either EQ or RQ.
- Aggregate the labels from lexical rule-based method and LLaMA2 model:
- If q is labeled as EQ by lexical rule-based method:
- If q is labeled as EQ by LLaMA2:
- q
EQ
- q
- ELSE:
- q
RQ
- q
- If q is labeled as EQ by LLaMA2:
- ELSE:
- q
RQ
- q
- Result: Two groups of questions EQs and RQs.
- Quality control: manual annotation on questions randomly sampled from WTQ.
- Heuristics:
- For WikiSQL:
- Select questions that can be answered without aggregation as EQs, otherwise RQs.
- For SQA:
- Take ONLY the first question from each dialog and label it as EQs.
- For TAT:
- Select questions that can be answered only based on tables.
- If q needs derivation or comparison: q
RQ - ELSE: q
EQ
- Step 4: Perturbation
- For RQ1 and EQs:
- Shuffle all rows / columns in a table randomly.
- Shift target rows / columns in a table, either to the top, to the middle, or to the bottom (for shifting rows) / either to the front or to the back (for shifting columns). (also for positional bias in RQ2)
- Transpose the table, i.e. rotate it by 90 degrees, exchanging rows and columns. (bias towards particular table layouts)
- For RQ2 and RQs:
- Remove relevant cells from the table.
- Remove the whole table by replacing it with a dummy table consisting a single “None”-value cell.
- Shift relevant rows by first removing them and then re-insert them at a random position of the table.
- For RQ3 and RQs: Manually modify cell values that should be aggregated to answer questions by three human annotators.
- Modify values to change answers. (RQ3.1)
- Modify values withouth changing answers. (RQ3.2)
- Quality control: ask two annotators not involved in the perturbation to answer the questions given the perturbed tables.
- For RQ1 and EQs:
Data statistics:
How does FREB-TQA differ from previous TQA benchmarks?
- FREB-TQA reveals the key strengths and weaknesses of end-to-end and pipeline TQA systems.
- Previous work do not disentangle the various aspects of robustness, thus not providing detailed insights into the cause of robustness issues.
- Previous work analyze the four aspects for other tasks.
Which systems and models are employed for the evaluation? What are their key differences?
- End-to-End systems:
- TAPEX: based on BART
- OmniTab: further fine-tune TAPEX on natural and synthetic data
- Pipeline systems:
- TaPas: first predicts relevant cells and an aggregation function, then produces answers using a numeric tool
- Binder: first generate intermediate representations (e.g. SQL queries) using GPT-3.5, then execute the queries using a program interpreter
- Off-the-shelf LLMs:
- GPT-3.5: three-shot prompting
- LLaMA-7b-chat: LORA fine-tuning
Which evaluation metrics are used?
- Exact match accuracy (Em)
- Exact match difference (Emd)
- Variation percentage (VP)
What are the results of the experiments?
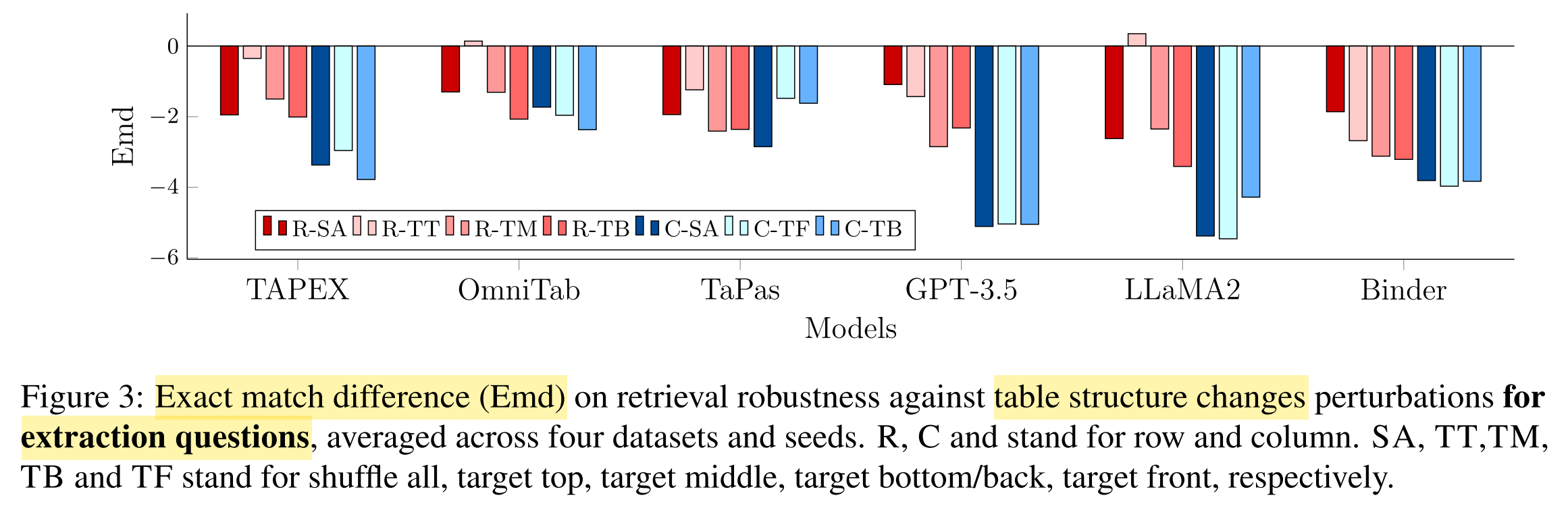
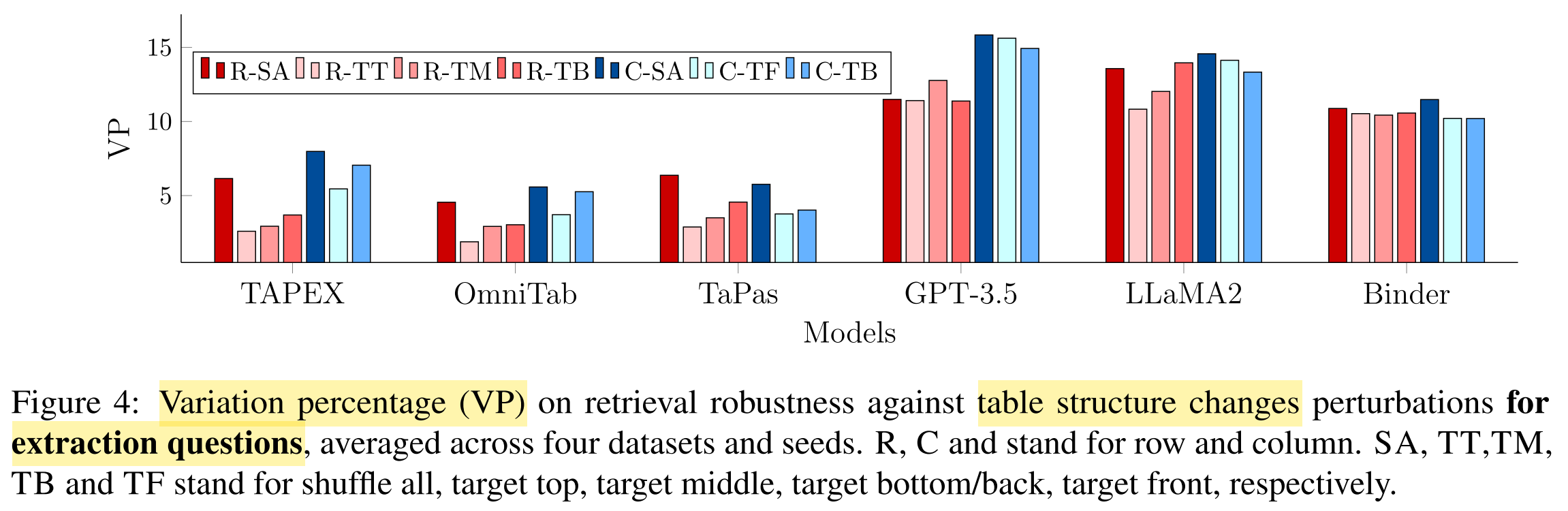
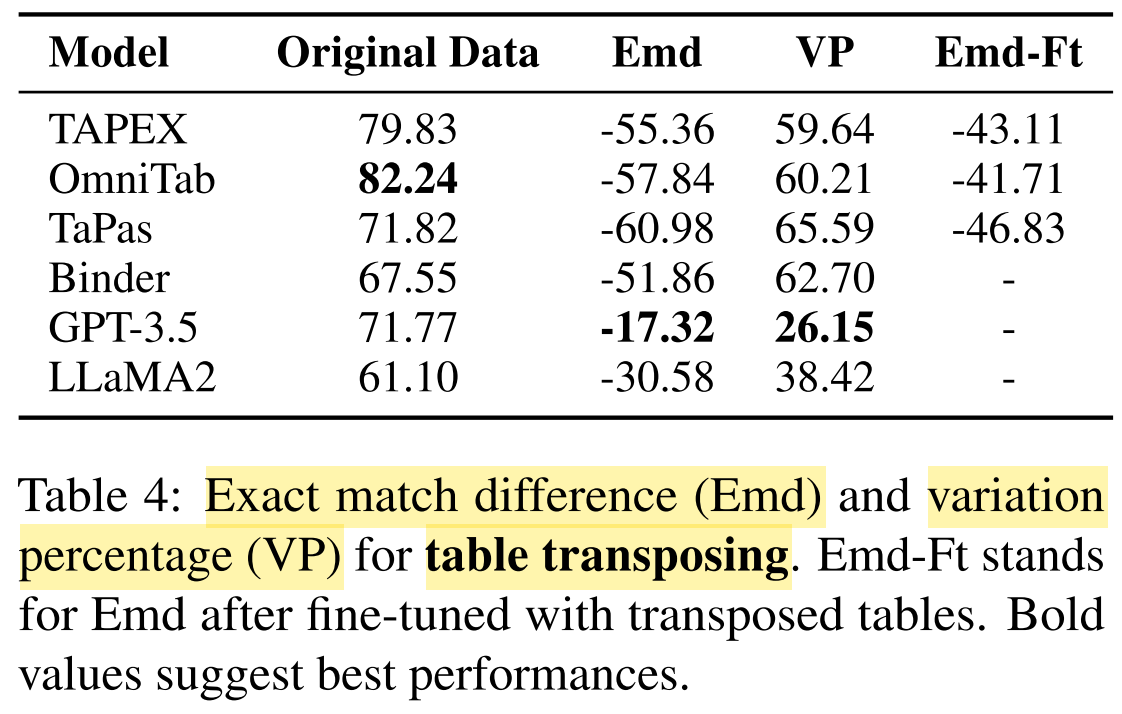
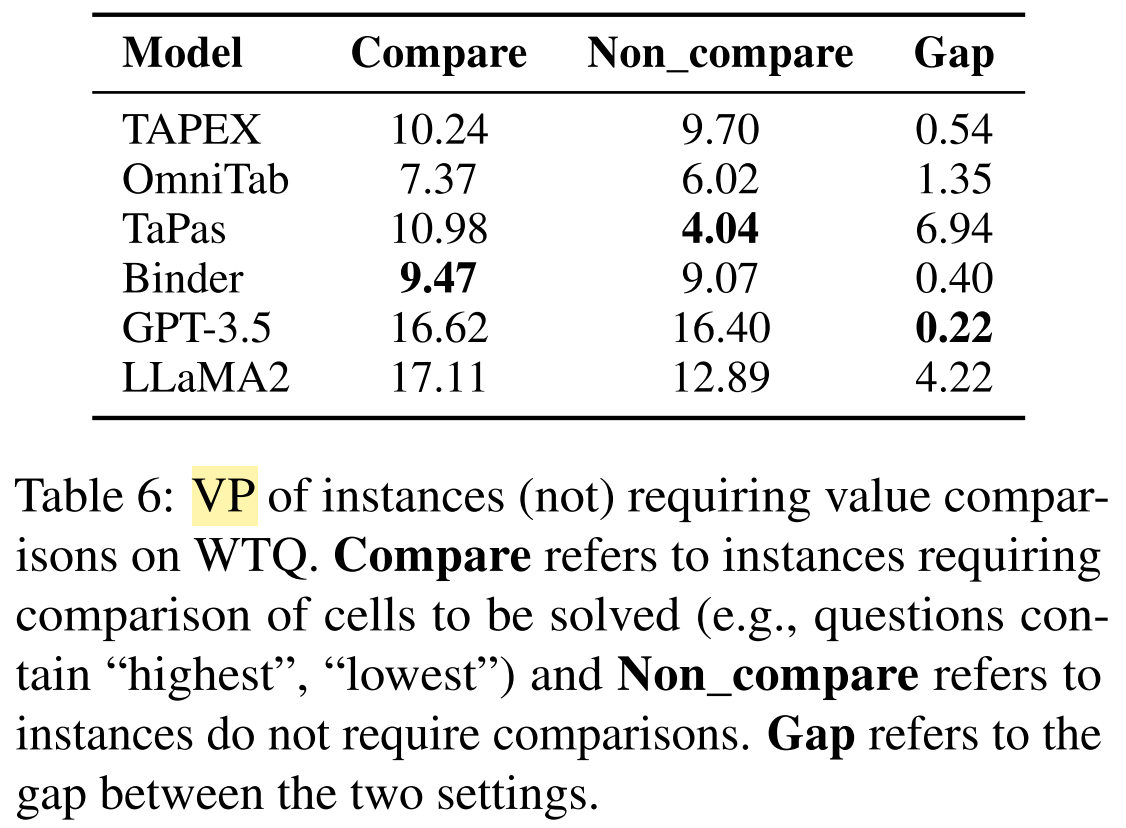
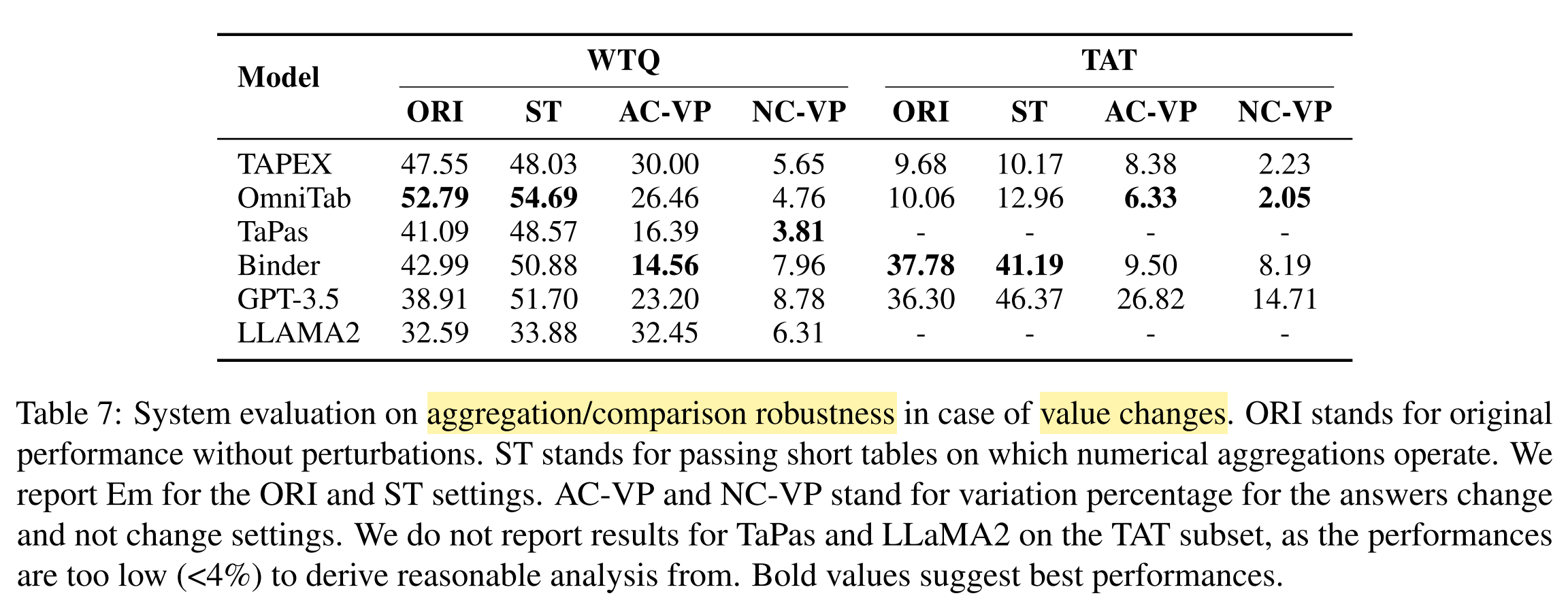
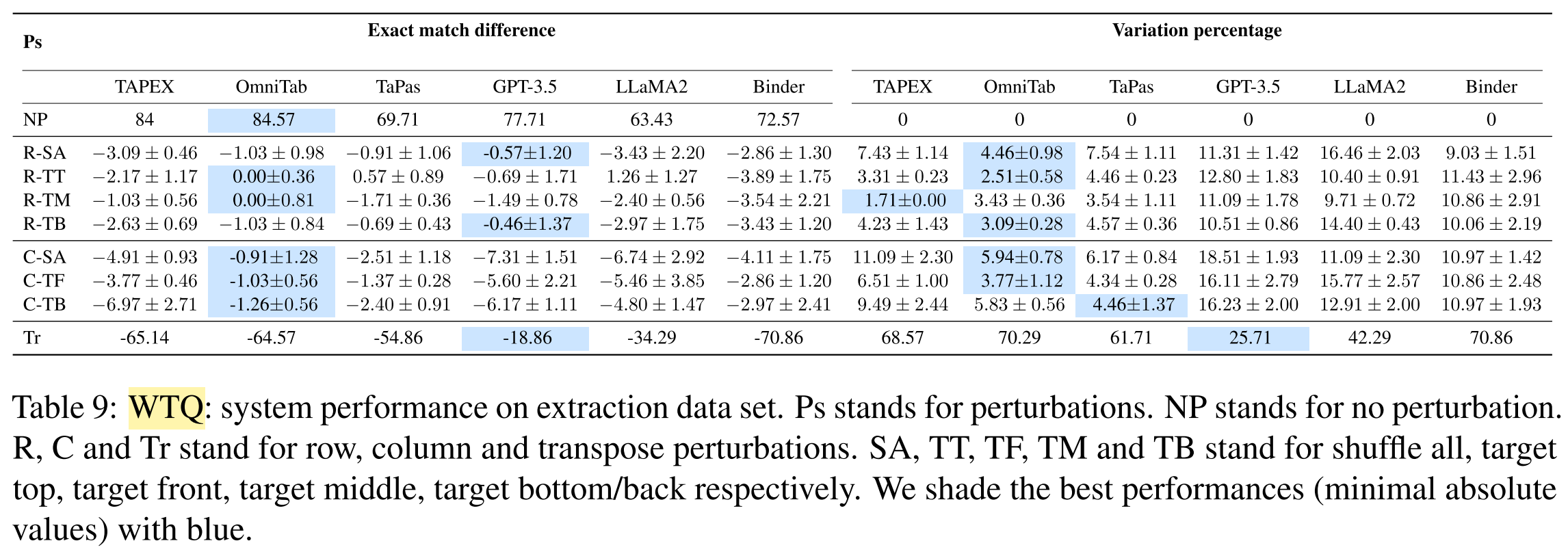
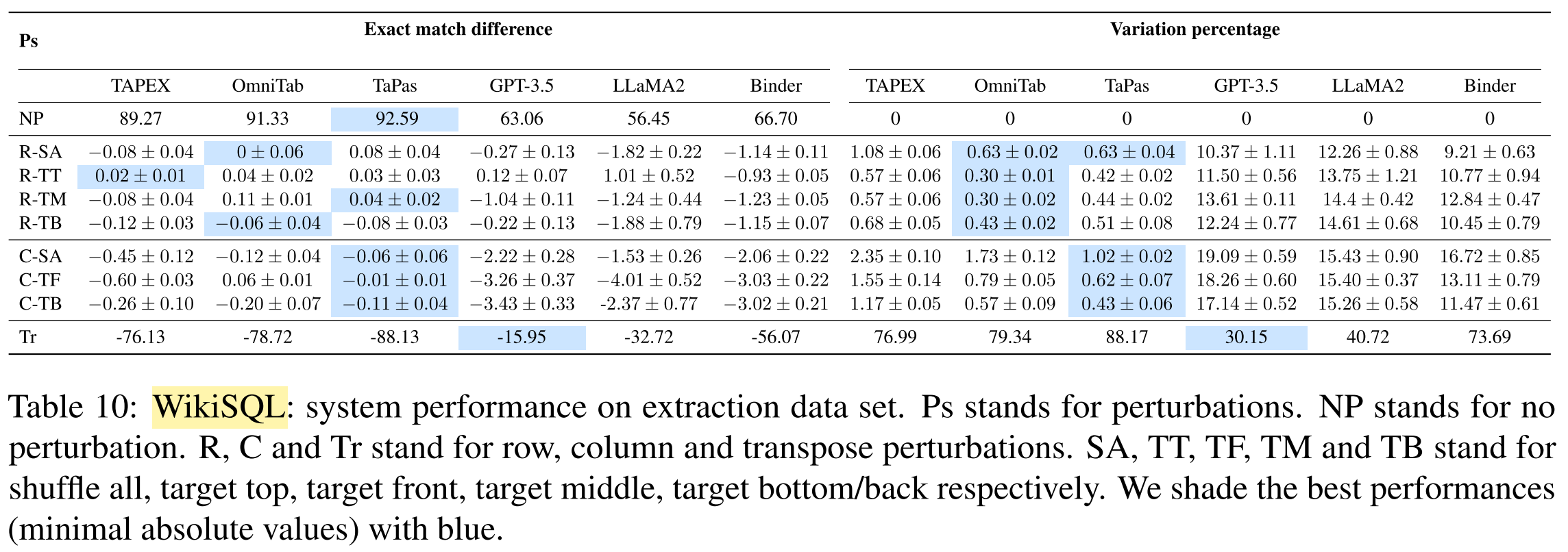
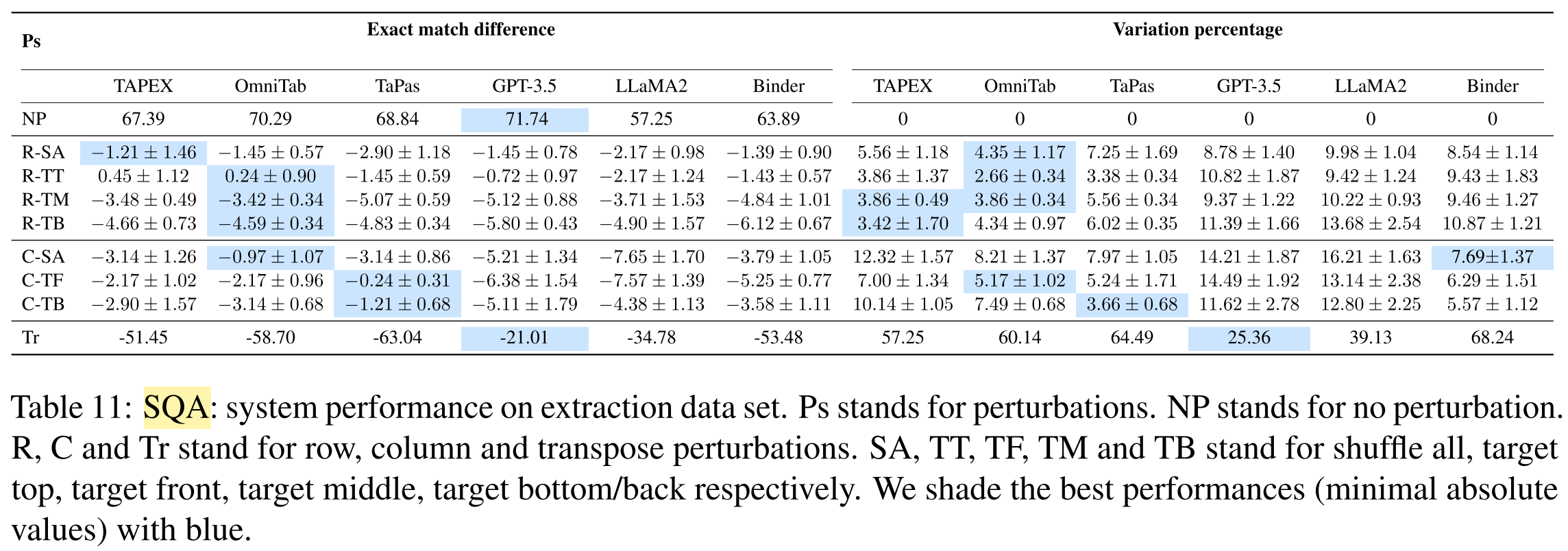
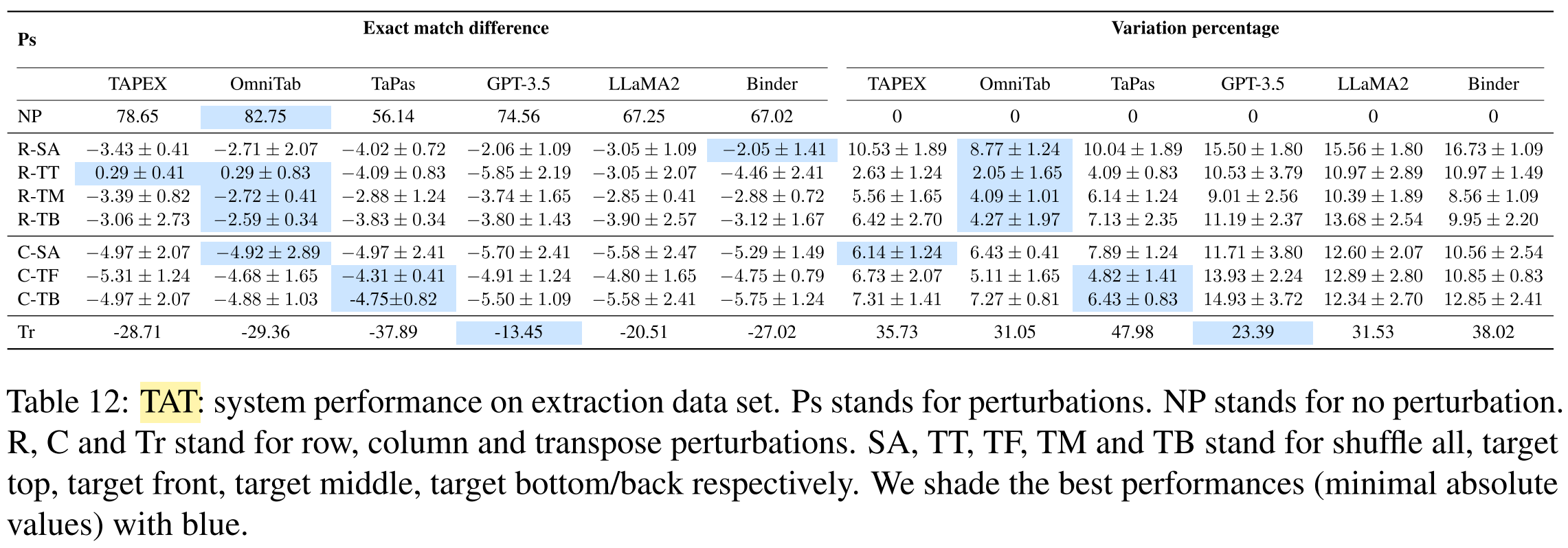
What conclusions are drawn from the results?
- All systems suffer from substantial robustness issues.
- End-to-end TQA systems:
- more robust against table structure changes
- fail on numerical reasoning questions
- LLMs-based systems:
- more robust against transposing tables
- less robust against table structure changes
- perform better on short serialized tables
- Pipeline systems:
- more robust against value changes in relevant cells
- the prediction of aggregation function or query still suffer s from various perturbations of the table
- intermediate representations (i.e. aggregation function, query) makes the model more explainable
- pipeline-based paradigm is promising towards more robust TQA
What are the main advantages and limitations of this paper?
Advantages:
- This work disentangles the various aspects of TQA systems’ robustness, which provides fine-grained analyses and deep insights into the underlying cause of their robustness issues.
- This work evaluates two classes of TQA systems which have different mechanisms and complete the task in different manners, facilitating the investigation of the impact of system architecture on the robustness.
- This work also evaluates recent LLMs (GPT-3.5 and LLaMA-7b-chat) that generate answers auto-regressively, posing challenges in terms of controlled generation, faithfulness and interpretability.
- This work makes the novel benchmark publicly available, boosting future research on this problem in the community.
- This work focuses on the robustness issues of TQA systems that are crucial in real-world applications, e.g., the interaction with relational databases and information extraction.
Limitations:
- The input tables are serialized into plain text before being fed to the model. Despite its necessity to align with the models input format during training, the serialization process often increases the input length and hence reduces the model’s robustness. The serialized table could omit relevant information across different rows or columns. More serialization methods could be compared to assess the model’s robustness.
- This work only evaluates general LLMs, i.e. GPT-3.5 and LLaMA-7b-chat, which were pre-trained on plain texts. Further evaluations could be done using LLMs specifically trained on the TQA task, which are equipped with a specific table encoder.
- Humans typically also rely on their visual perception to comprehend the table. Would it be worth adopting multimodal models that takes the screenshot of the table and the textual question as inputs, and generates the answer based on the information from both modalities?
What insights does this work provide and how could they benefit the future research?
- Title: FREB-TQA: A Fine-Grained Robustness Evaluation Benchmark for Table Question Answering
- Author: Der Steppenwolf
- Created at : 2024-12-03 12:31:48
- Updated at : 2025-06-22 20:46:50
- Link: https://st143575.github.io/steppenwolf.github.io/2024/12/03/FREB-TQA/
- License: This work is licensed under CC BY-NC-SA 4.0.